Fastjson 介绍
Fastjson 是阿里巴巴开发的一个高性能 JSON 解析库,广泛应用于 Java 项目中。它的主要功能是对 JSON 数据进行序列化和反序列化,即将 Java 对象转换为 JSON 字符串,或者将 JSON 字符串解析为 Java 对象。Fastjson 的优势在于其速度和灵活性,特别是在处理大规模数据时性能表现良好。
快速入门
导入如下依赖:
1 | <dependencies> |
在 pojo 包下创建一个简单类:
1 | package pojo; |
序列化
调用 JSON 的 toJSONString 方法将对象转换为字符串:
1 | import com.alibaba.fastjson.JSON; |
输出结果如下:
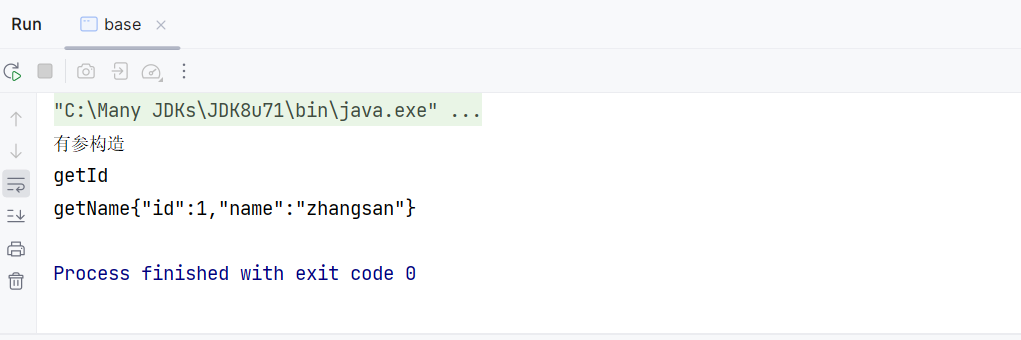
可以看出,在调用 JSON.toJSONString 方法时调用了对象的 getter 方法获取属性值。
toJSONString 方法有很多重写:
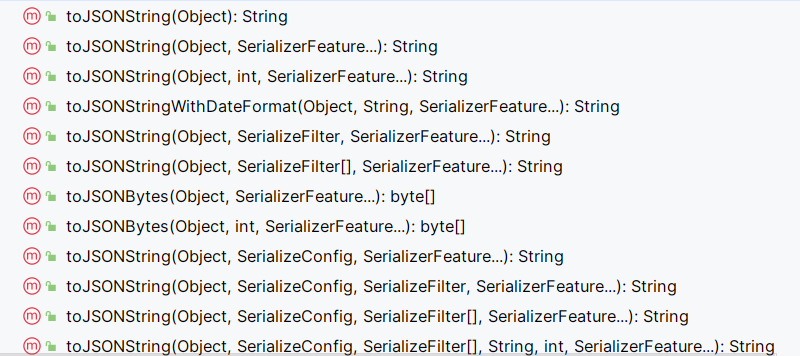
在 Java 中,方法参数后面的三个点(…)代表可变参数(Varargs),即这个方法可以接受任意数量的该类型参数。在 Fastjson 中,SerializerFeature… features 意味着这个方法可以接受多个 SerializerFeature 枚举值,甚至可以不传递任何 SerializerFeature。
如果再多传入一个参数 SerializerFeature ,值为 SerializerFeature.WriteClassName ,就可以在序列化结果中多打印一个 @type:类名 :
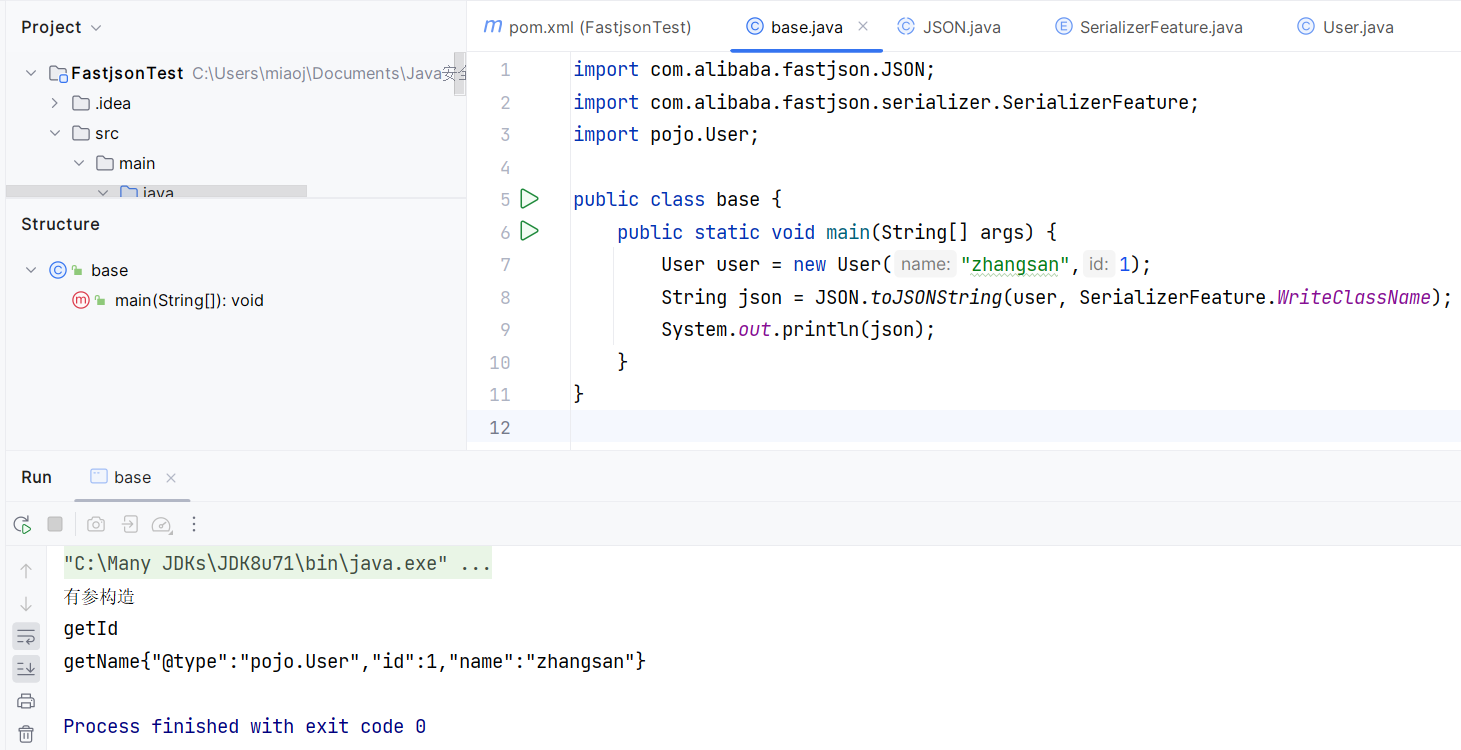
传入 SerializerFeature.WriteClassName 可以使得 Fastjson 支持自省,开启自省后序列化成 JSON 的数据就会多一个 @type ,这个是代表对象类型的 JSON 文本。
反序列化
反序列化时常使用的方法为 parse() 、parseObject() 、parseArray() ,这三个方法也均包含若干重载方法:
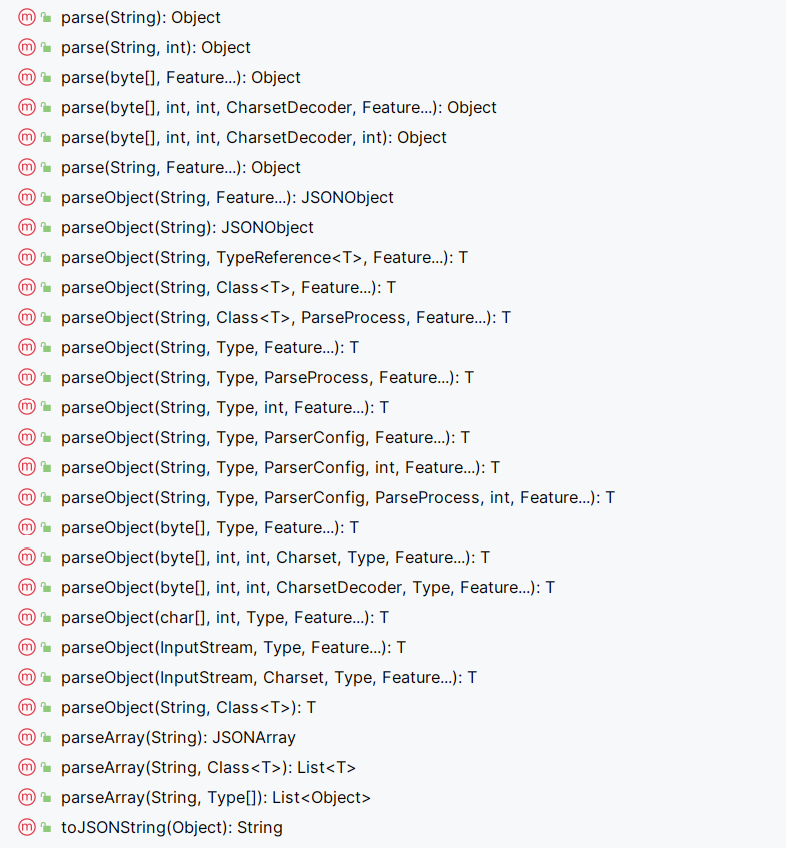
下面程序用来测试反序列化:
1 | import com.alibaba.fastjson.JSON; |
输出结果如下:

不同的方法和参数得到的结果也不同,其中:
1 | JSON.parseObject(json2) |
这两个方式的反序列化是失败的。
parse() 、parseObject()
来聊聊这两个方法。在上面的案例中可以知道,如果要成功反序列化出 User 对象,parseObject 就一定要指定第二个参数为 User.class ,而 parse 则一定要用 @type 指定要反序列化的类。
parseObject 方法如果不指定第二个参数,那么会返回 JSONObject 对象,而不是 User 对象:
1 | JSON.parseObject(json) |

并且像这样的调用方式会同时调用 User 的 getter/setter 方法。
getter/setter 方法的调用
可以发现,无论是序列化还是反序列化,都会调用其 getter 或 setter 方法。我们来跟进一下看看具体是在哪里调用的。
就以 JSON.parseObject(json) 这样的调用方式为例,跟进 JSON#parseObject(String):
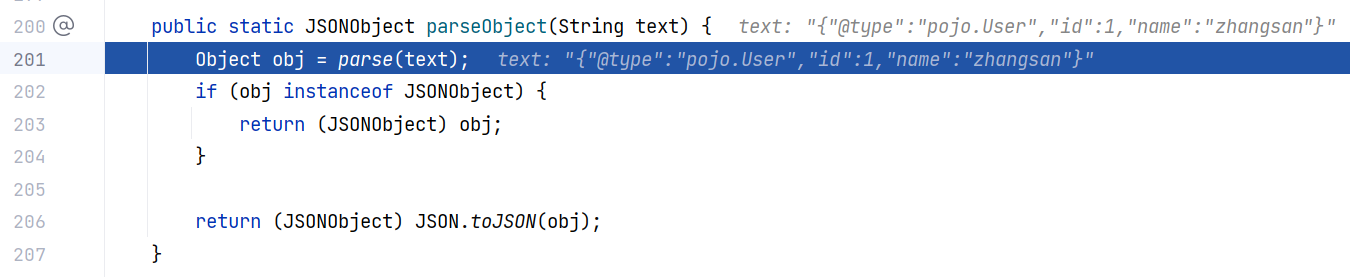
这里调用 parse 方法,跟进 JSON#parse(String):

继续跟进 JSON#parse(String, int):
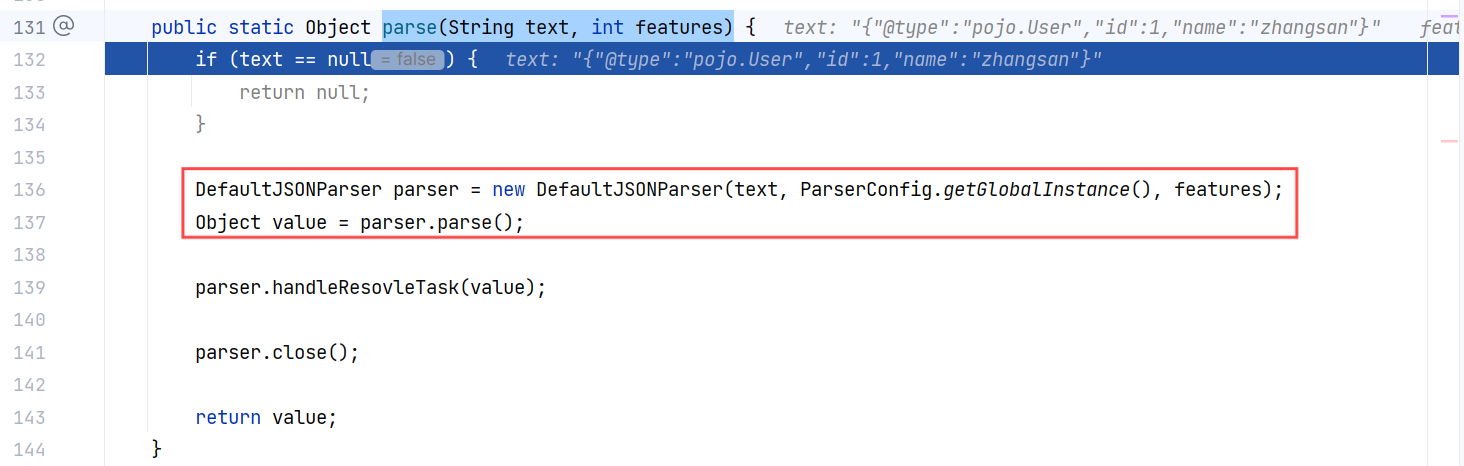
这里先是调用 DefaultJSONParser 获取一个默认 Json 解析器,然后调用解析器的 parse 方法。
跟进 DefaultJSONParser#parse():

跟进 DefaultJSONParser#parse(Object):

直接进入了 case LBRACE 。JSONObject 的构造方法没什么可看的。
直接跟进 DefaultJSONParser#parseObject(final Map, Object):
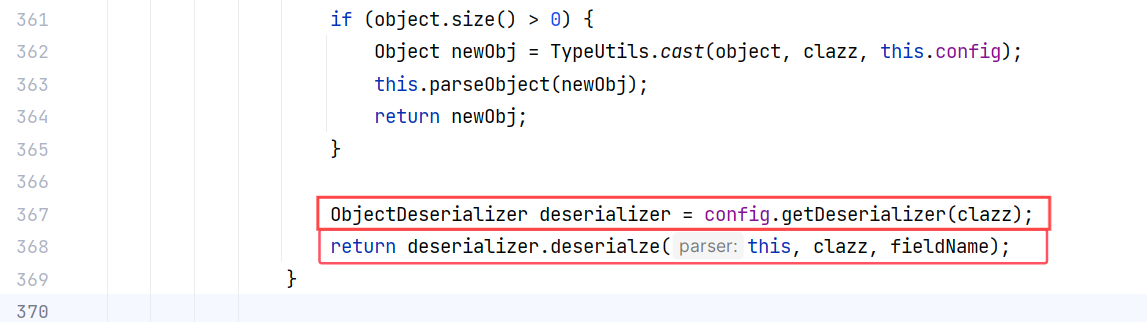
方法的中间调用了 config.getDeserializer 来获取一个反序列化器,我们先跟进它,也就是 ParserConfig#getDeserializer(Type):
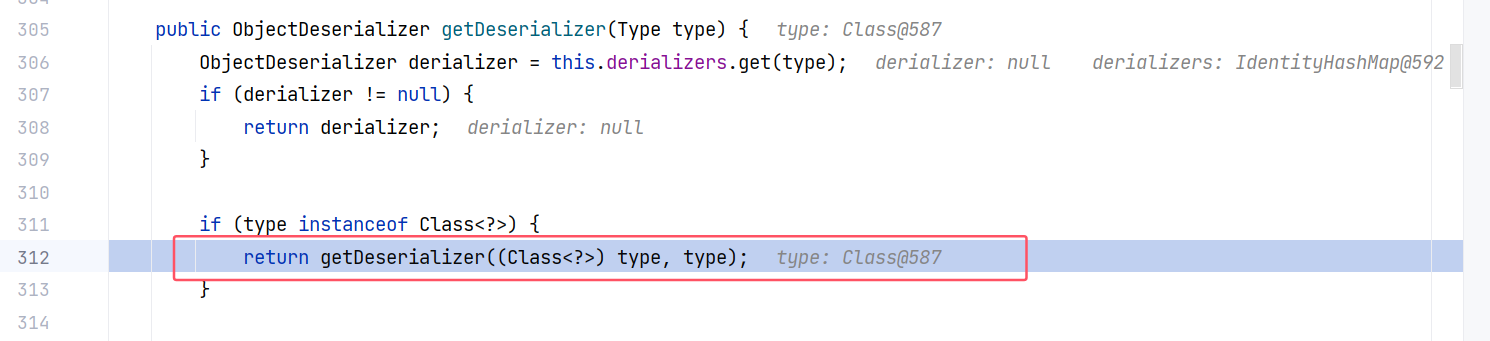
这里调用重载方法,跟进 ParserConfig#getDeserializer(Class<?>, Type):
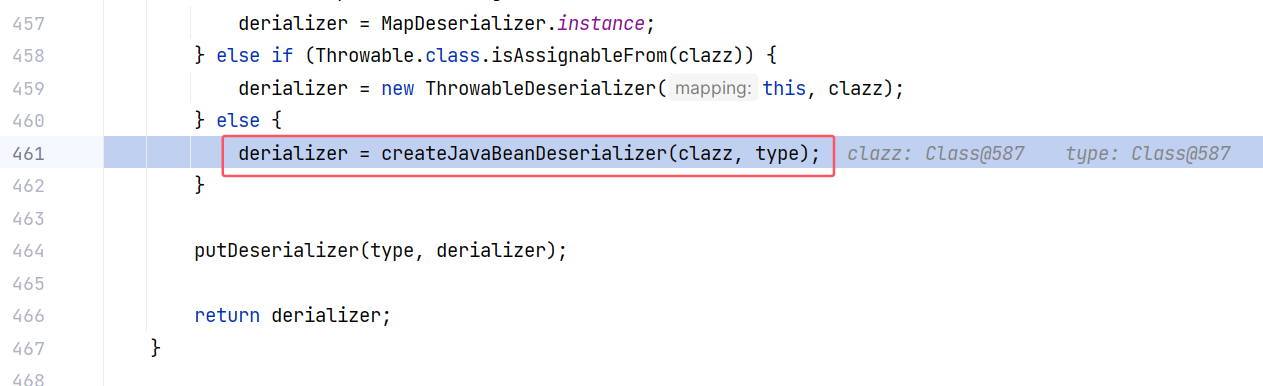
跟进 ParserConfig#createJavaBeanDeserializer(Class<?>, Type) :
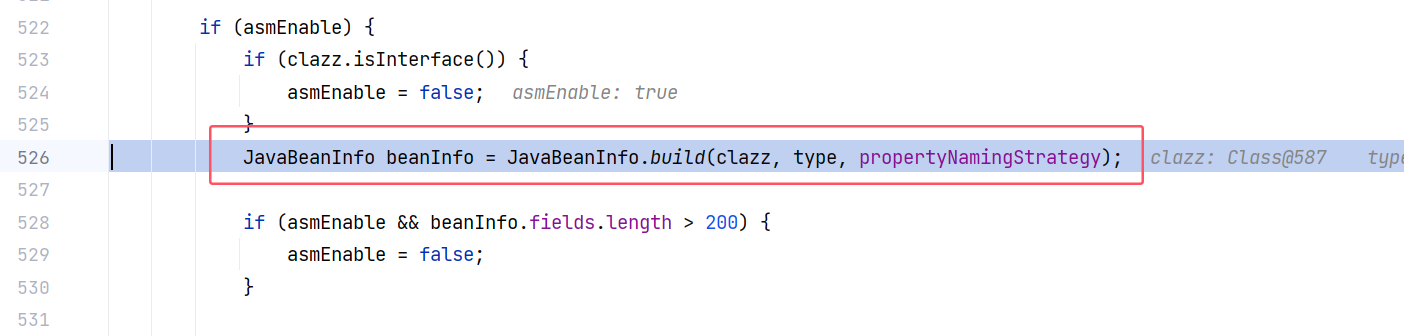
跟进 JavaBeanInfo#build(Class<?>, Type, PropertyNamingStrategy):
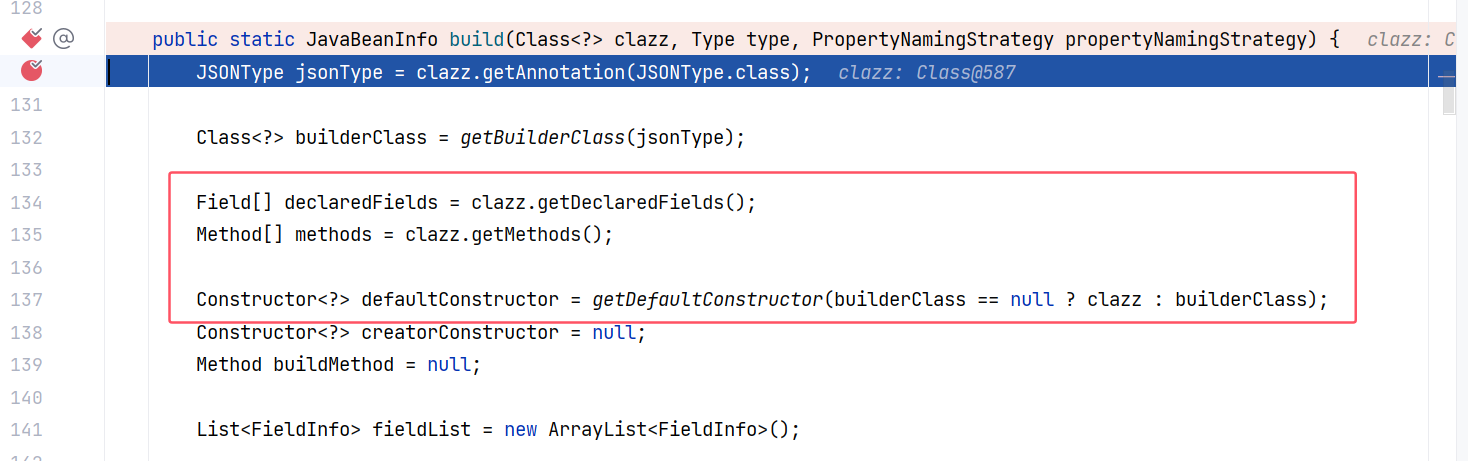
这个方法比较重要,那些 getter/setter 方法就是在这里获取名称的。
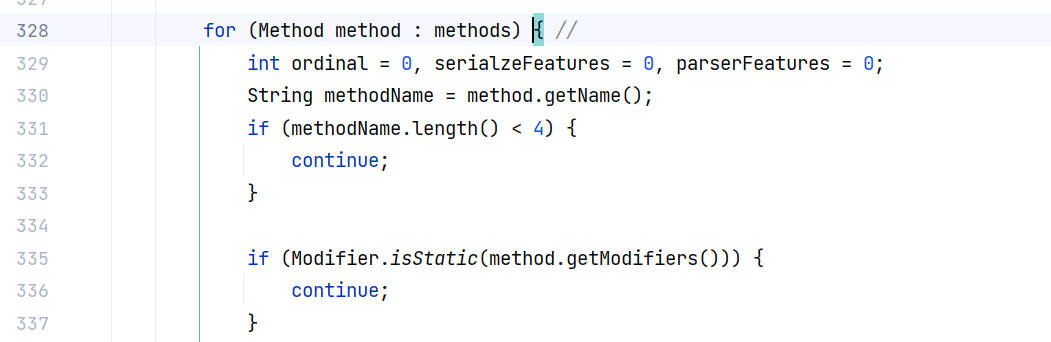
在方法的中间遍历类中的所有 public 方法,过滤出符合条件的 setter 方法:
代码很长,这里就不放完了。总结起来就是:
判断 setter 方法:
- 方法名长度大于等于 4
- 不是静态方法
- 返回类型为空或当前类
- 参数个数为 1 个
- 方法上的 @JSONField 注解没有指定该字段不可反序列化
- 方法名以 “set” 开头
判断字段名:
char c3 = methodName.charAt(3); 获取方法名的第四个字符(即 setXyz 中的 X)
- 如果 c3 是大写字母,则字段名为 setXyz 中的 xyz 。
- 如果 c3 是下划线 _ ,则字段名为 set_xxx 中的 xxx 。
- 如果方法名的第五个字符是大写字符,则保留原来的大写风格。比如 setURL 保留 URL 作为字段名。
- 根据上述方法推导出来的字段名,通过反射去查找类中的实际字段。如果没有找到字段,并且方法参数是
boolean类型,尝试将字段名前面加个 “is” ,改为 isXyz 形式重新查找字段。
后面再接着遍历类中的所有 public 方法,过滤出符合条件的 getter 方法:

同样总结一下获取 getter 方法的规则:
- 方法名长于 4
- 不是静态方法
- 以 get 开头且第 4 位是大写字母
- 没有参数
- 返回类型继承自 Collection|Map|AtomicBoolean|AtomicInteger|AtomicLong
- 对带有 @JSONField 注解的方法,优先使用注解中定义的属性名或选项。
build 方法的最后将该类的构造函数、字段、获取到的 setter/getter 方法以及其他与序列化和反序列化相关的信息都封装进了一个 JavaBeanInfo 对象:

好的,回到 DefaultJSONParser#parseObject(final Map, Object) ,我们接下来看下面的调用:

跟进 JavaBeanDeserializer#deserialze(DefaultJSONParser, Type, Object):

这里需要注意的是,如果直接进入下一步,会跟不进去:
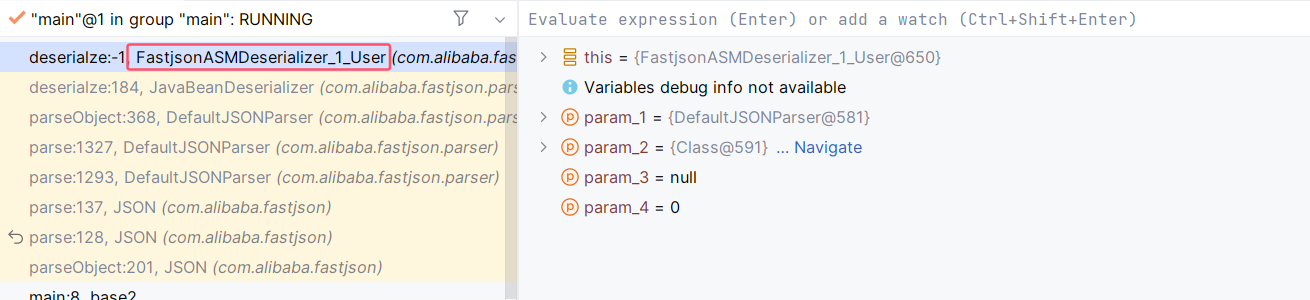
这是由于 ParserConfig#createJavaBeanDeserializer(Class<?>, Type) 中设置 asmEnable 为 true 了。如果确实想跟进去看的话,可以在调试时将其值设置为 false 。asmEnable 是 true 的情况下,使用 asm 从字节码层面生成特定 javabean 的反序列化器,自然无法跟进去看了;为 false 的时候,则使用常规的 set 方法进行反序列化(效率低、不安全)。不过这两种方法生成的内容是一样的。
那么重新调试,再次调试到这里的时候,将其值设置为 false :
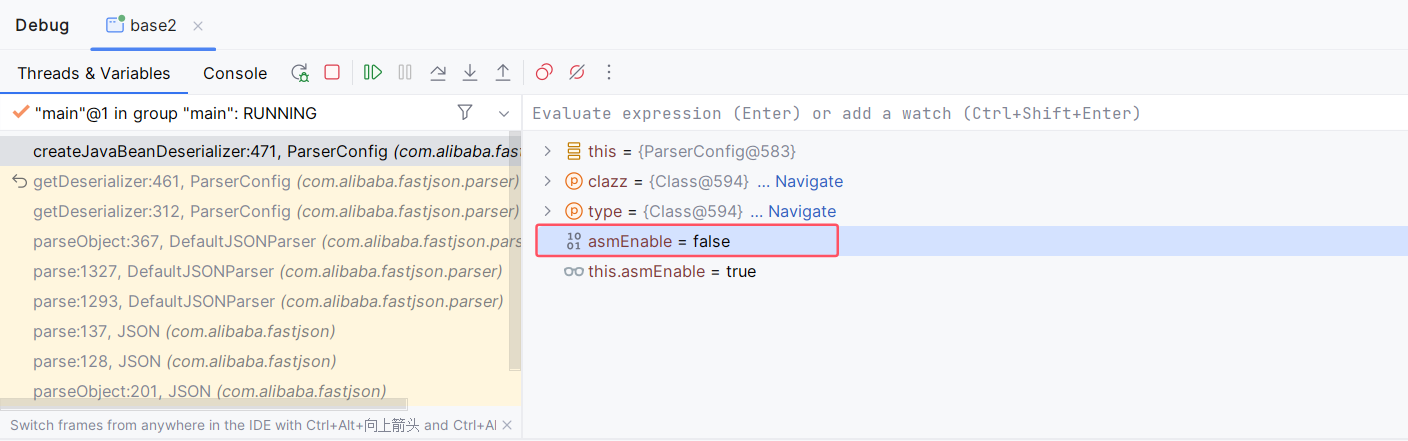
继续调试到 JavaBeanDeserializer#deserialze(DefaultJSONParser, Type, Object),此时可以跟进了:

这里两个重载方法,一路跟到 JavaBeanDeserializer#deserialze(DefaultJSONParser, Type, Object, Object, int):
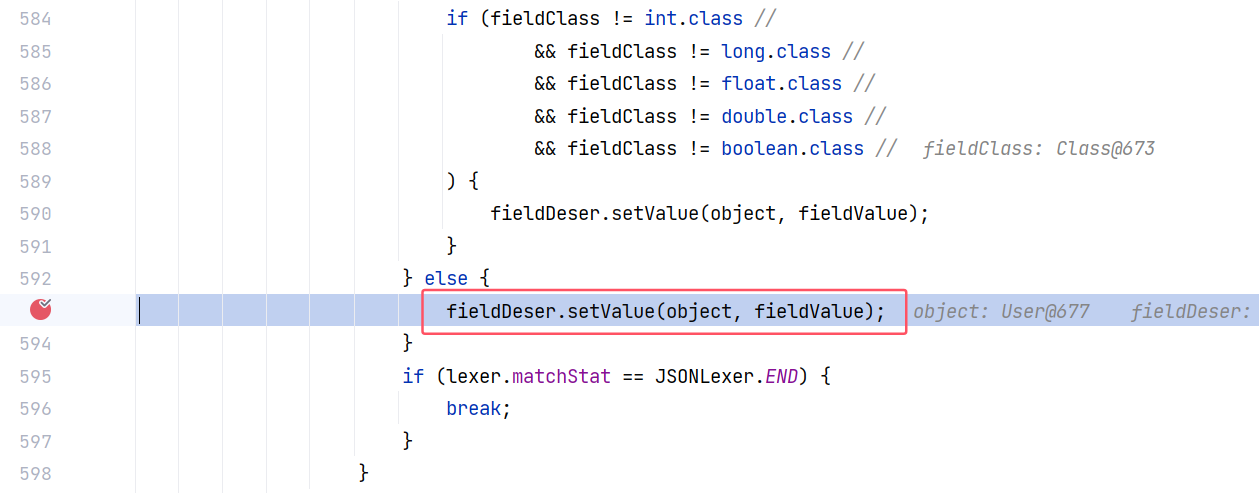
这个方法在经过一系列处理后,最终调用到了 fieldDeser.setValue 来为 User 对象赋值。
跟进 FieldDeserializer#setValue(Object, Object):
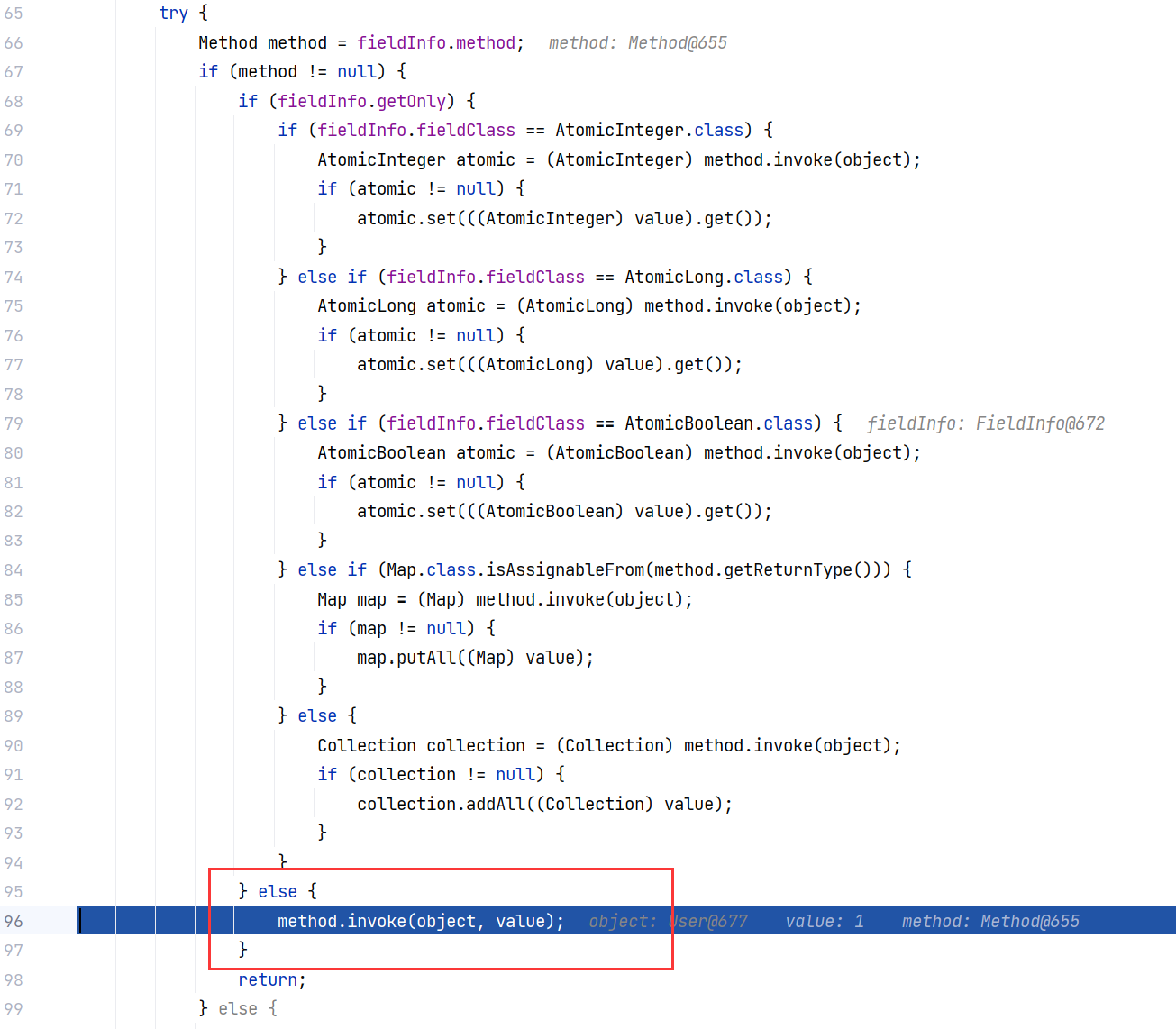
这里就是最终调用 setter 方法的地方。
然而,如果说 json 字符串中的字段名与 JavaBeanInfo#build(Class<?>, Type, PropertyNamingStrategy) 方法获取到的 JavaBeanInfo 对象中存储的字段名不一致的话,那么 JavaBeanDeserializer#deserialze(DefaultJSONParser, Type, Object, Object, int) 的 matchField 值为 false ,就会进入另一条分支,调用 parseField 方法来处理。比如我现在将 id 字段改为 _i_d_ ,但是 setter 方法还是叫 setId :
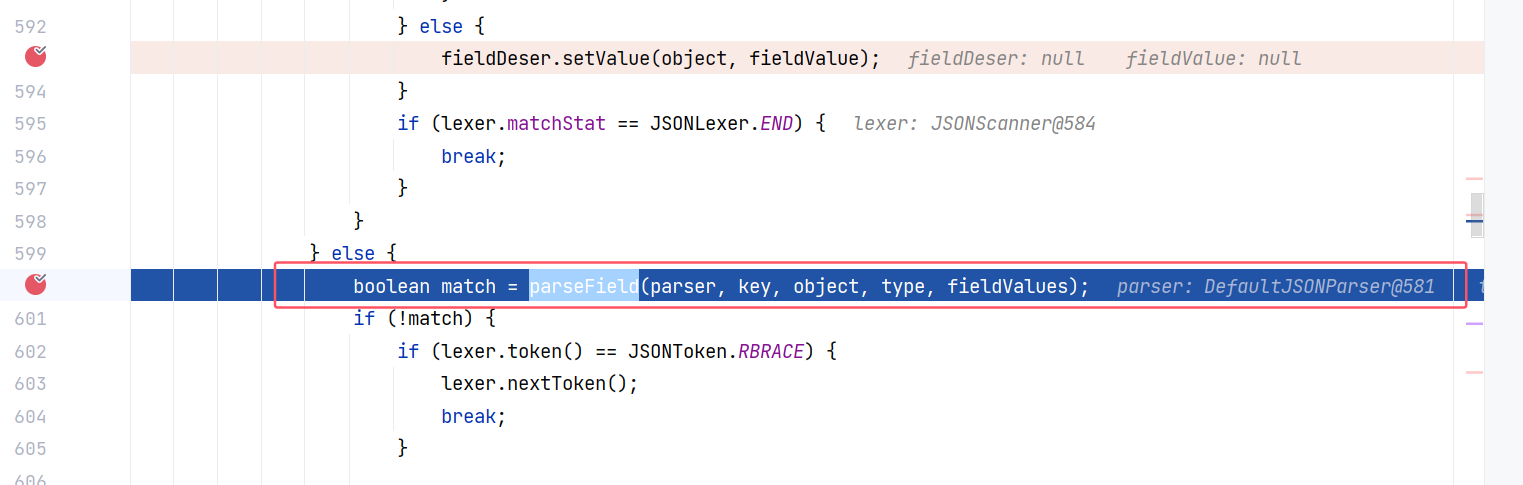
跟进 JavaBeanDeserializer#parseField(DefaultJSONParser, String, Object, Type, Map<String, Object>):
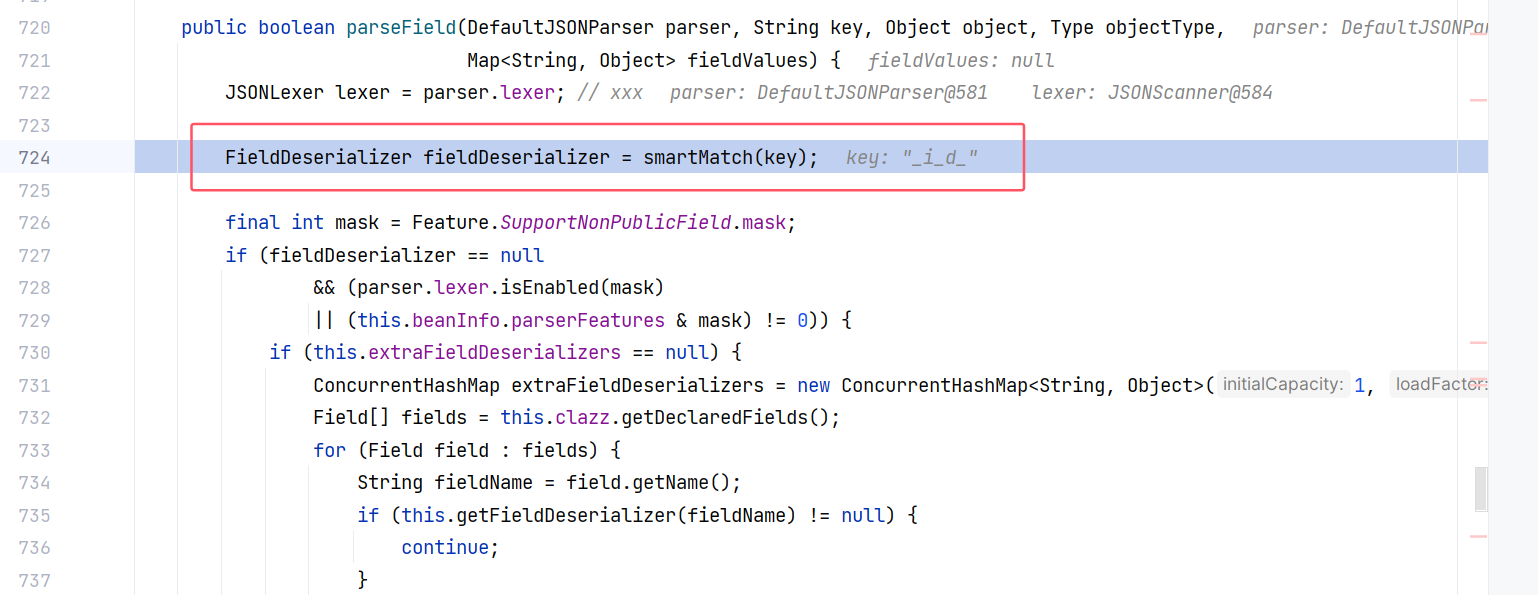
跟进 JavaBeanDeserializer#smartMatch(String),这是一个比较关键的方法,如果匹配不一致的话,会判断 key 是否是 is 开头,或者将 key 中的 - 和 _ 去掉再比对:
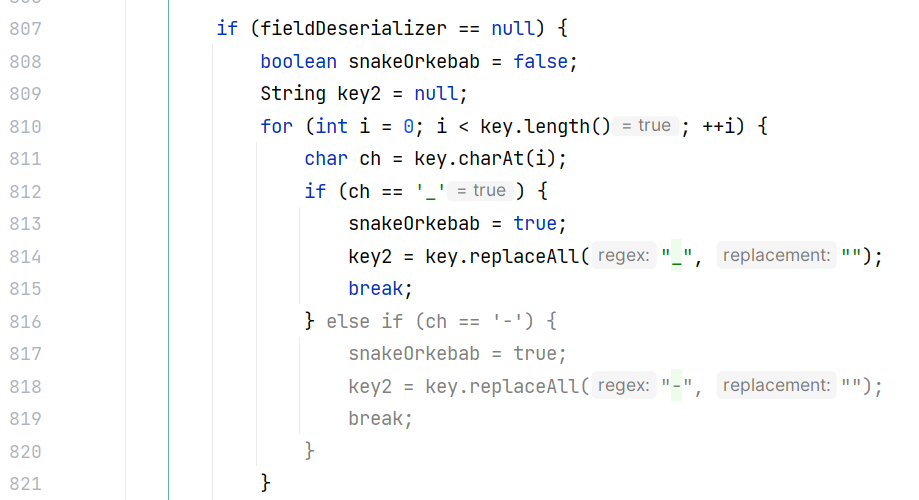
也就是说即使字段名为 _i_d_ ,依然能够找到名为 setId 的 setter 方法。
若是走这条路,则是在 DefaultFieldDeserializer#parseField(DefaultJSONParser, Object, Type, Map<String, Object>) 中调用 setvalue 方法:

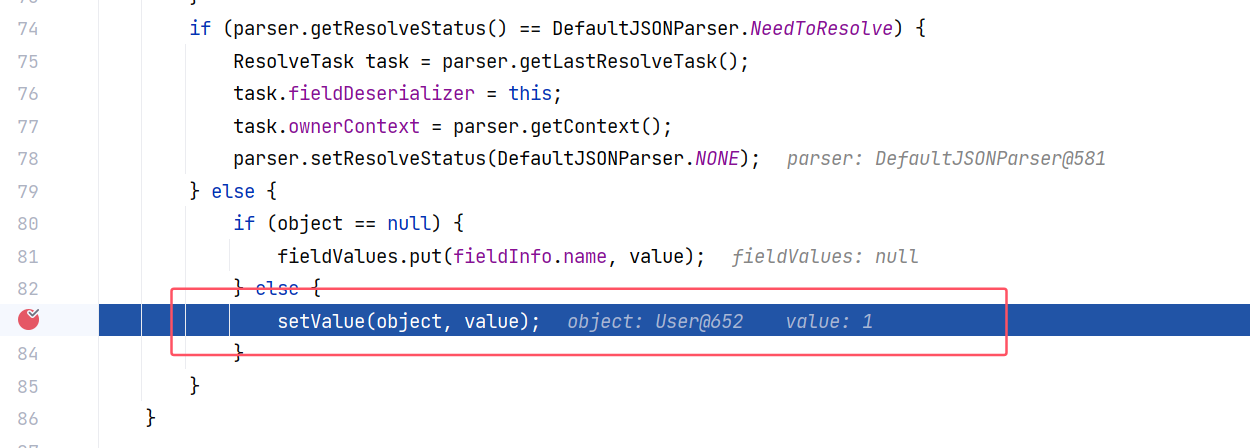
那么 getter 方法又在哪里调用呢?回到最初的 JSON#parseObject(String):
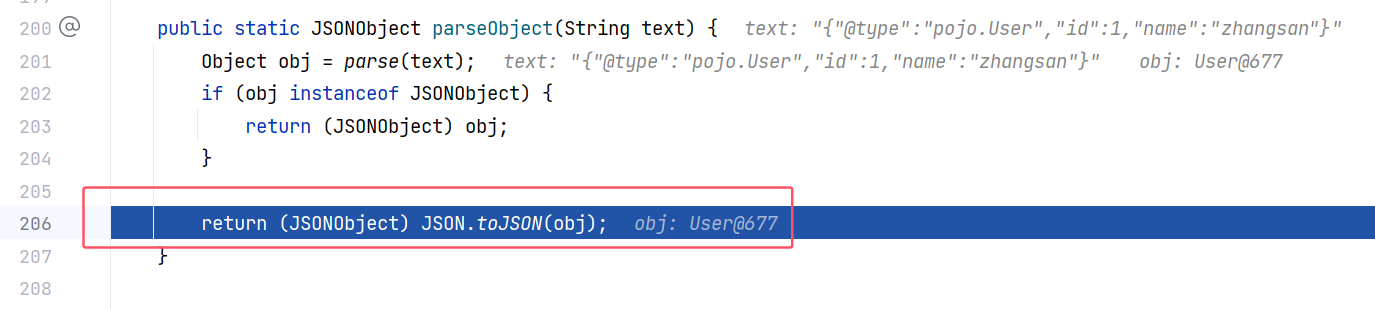
现在 parse 这条路已经走完了,跟进 JSON#toJSON(Object),这是一个将 Java 对象转为 Json 数据的方法:

跟进 JSON#toJSON(Object, SerializeConfig) :
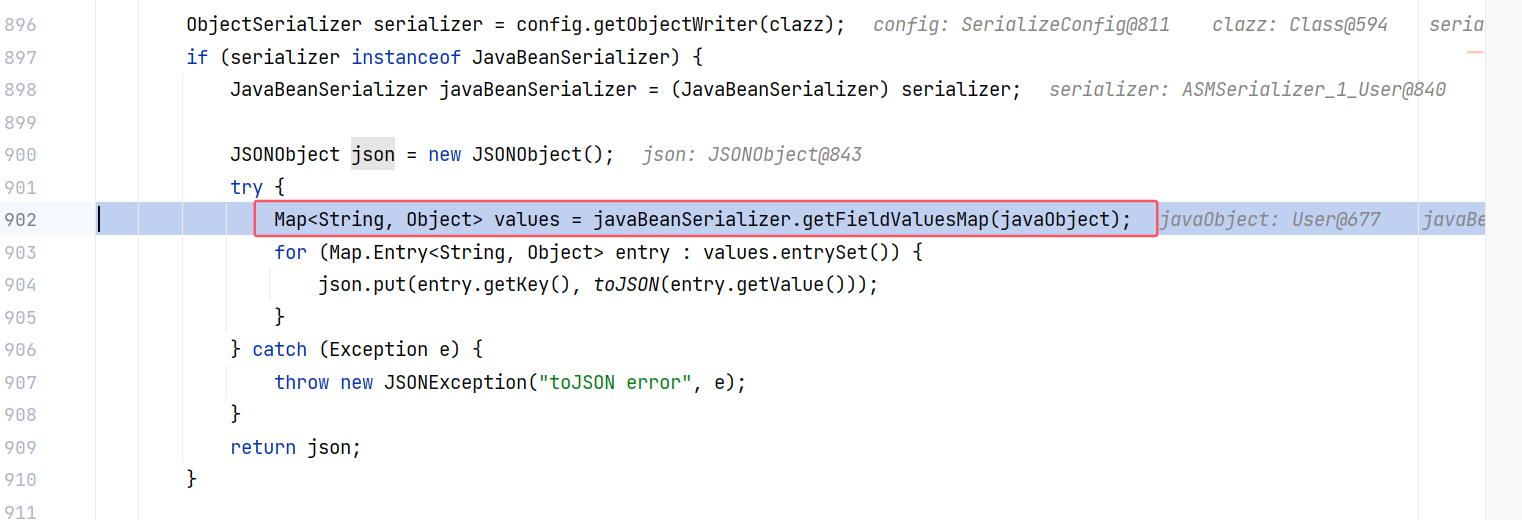
这里调用 javaBeanSerializer.getFieldValuesMap 来获取字段值的 Map 集合。
跟进 JavaBeanSerializer#getFieldValuesMap(Object):
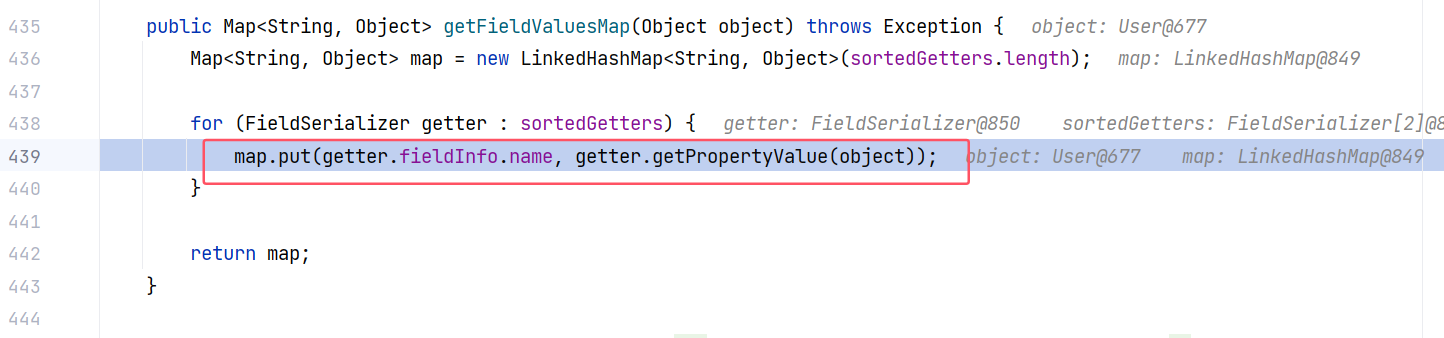
这里调用 getter.getPropertyValue 获取属性值。
跟进 FieldSerializer#getPropertyValue(Object) :
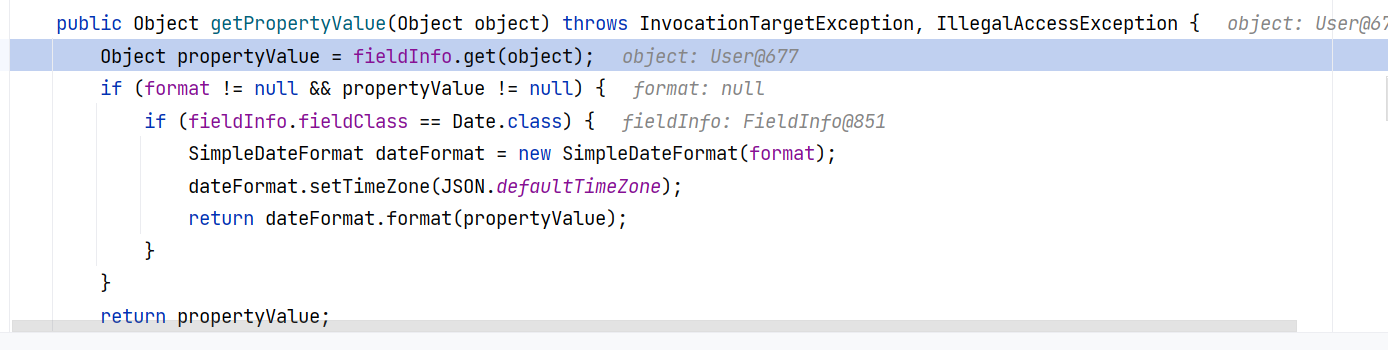
跟进 FieldInfo#get(Object):

这里就是调用 getter 方法的地方了。
调用链总结
于是可以总结出如下调用链:
1 | JSON#parseObject(String) |
其他的反序列化调用方式也大差不差。
特性总结
这里直接引用素十八师傅的总结(1.4.8. Fastjson 反序列化漏洞):
- 使用
JSON.parse(jsonString)和JSON.parseObject(jsonString, Target.class),两者调用链一致,前者会在 jsonString 中解析字符串获取@type指定的类,后者则会直接使用参数中的 class 。 - fastjson 在创建一个类实例时会通过反射调用类中符合条件的 getter/setter 方法,其中 getter 方法需满足条件:方法名长于 4、不是静态方法、以
get开头且第 4 位是大写字母、方法不能有参数传入、继承自Collection|Map|AtomicBoolean|AtomicInteger|AtomicLong、此属性没有 setter 方法;setter 方法需满足条件:方法名长于 4,以set开头且第 4 位是大写字母、非静态方法、返回类型为 void 或当前类、参数个数为 1 个。具体逻辑在com.alibaba.fastjson.util.JavaBeanInfo.build()中。 - 使用
JSON.parseObject(jsonString)将会返回 JSONObject 对象,且类中的所有 getter 与 setter 都被调用。 - 如果目标类中私有变量没有 setter 方法,但是在反序列化时仍想给这个变量赋值,则需要使用
Feature.SupportNonPublicField参数。 - fastjson 在为类属性寻找 get/set 方法时,调用函数
com.alibaba.fastjson.parser.deserializer.JavaBeanDeserializer#smartMatch()方法,会忽略_|-字符串,也就是说哪怕你的字段名叫_a_g_e_,getter 方法为getAge(),fastjson 也可以找得到,在 1.2.36 版本及后续版本还可以支持同时使用_和-进行组合混淆。 - fastjson 在反序列化时,如果 Field 类型为
byte[],将会调用com.alibaba.fastjson.parser.JSONScanner#bytesValue进行 base64 解码,对应的,在序列化时也会进行 base64 编码。
这些特性对于分析反序列化漏洞有很大帮助,其中一部分已经在前面的代码分析中证明完成。
Fastjson 反序列化
fastjson 1.2.24
影响版本:fastjson <= 1.2.24
描述:fastjson 默认使用 @type 指定反序列化任意类,攻击者可以通过在 Java 常见环境中寻找能够构造恶意类的方法,通过反序列化的过程中调用的 getter/setter 方法,以及目标成员变量的注入来达到传参的目的,最终形成恶意调用链。此漏洞开启了 fastjson 反序列化漏洞的大门,为安全研究人员提供了新的思路。
TemplatesImpl 利用链
com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl 实现了 Serializable 接口,它可以被序列化。
具体来看 TemplatesImpl#getTransletInstance() 方法:
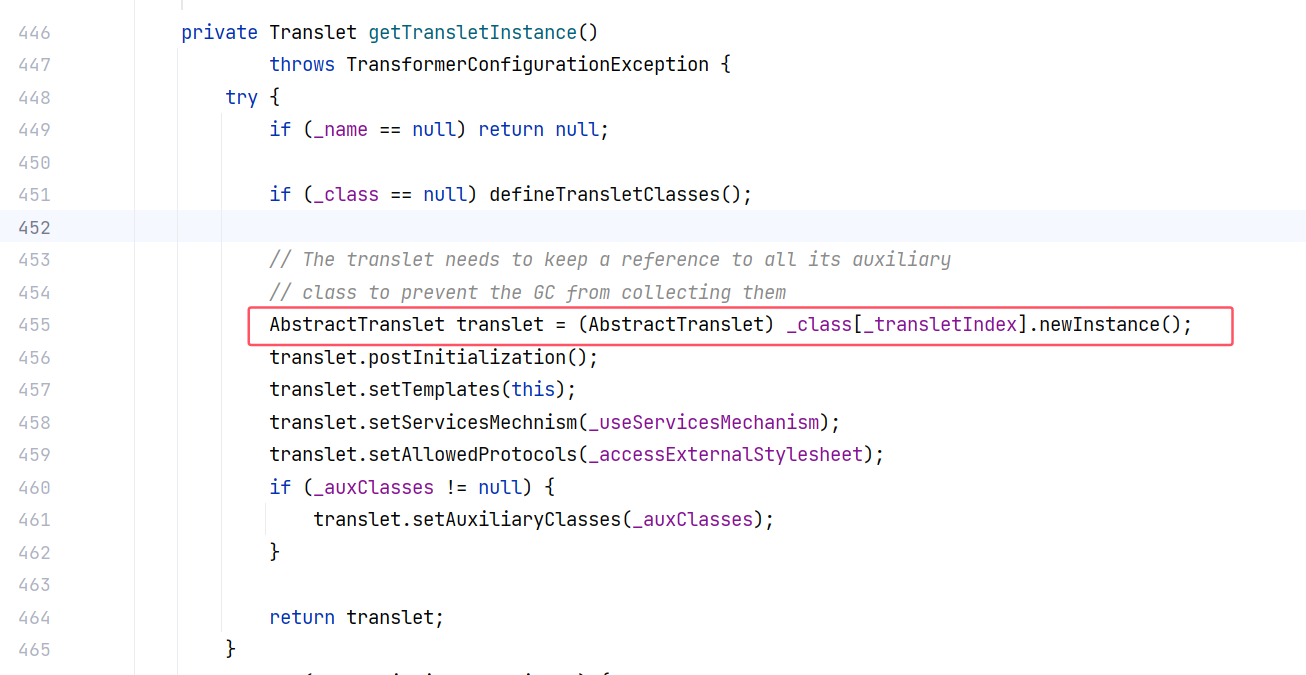
这是一个 getter 方法,但是不满足调用要求,它的返回类型是 Translet 。
再往上找,newTransformer() 方法调用了 getTransletInstance() :
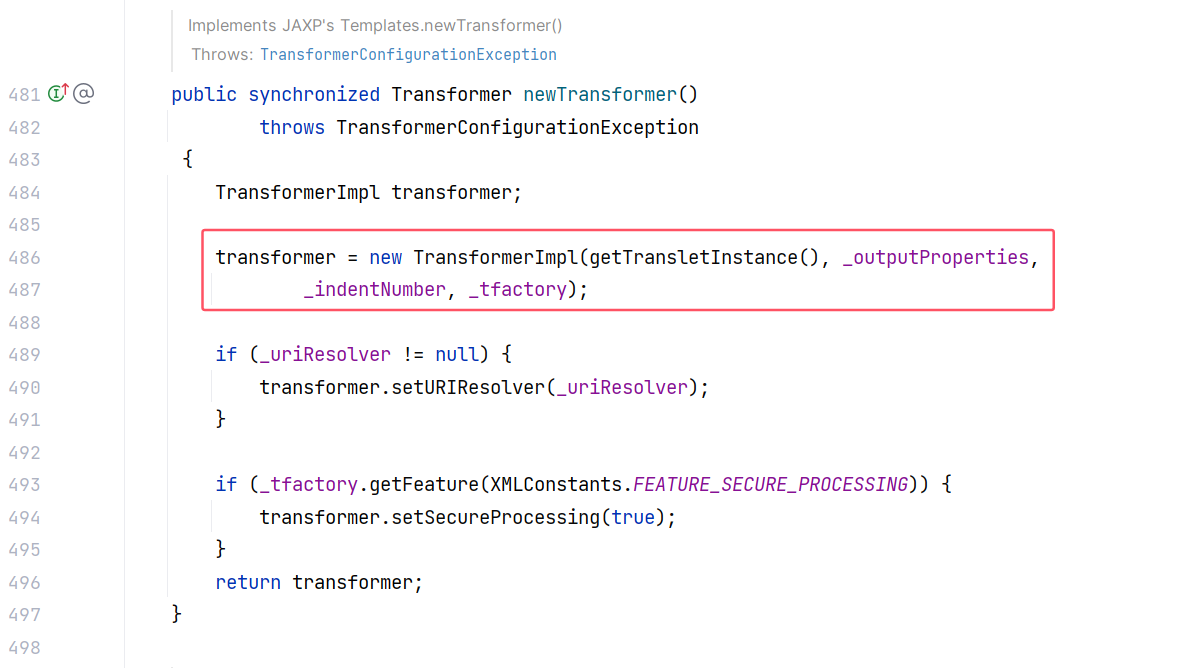
getOutputProperties() 方法又调用了 newTransformer() :
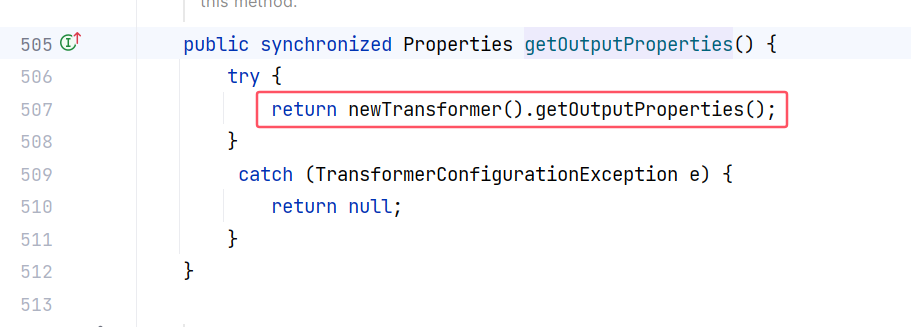
getOutputProperties() 方法是成员属性 _outputProperties 的 getter 方法,它的返回类型是 Properties ,Properties 实现了 Map 接口,符合要求,反序列化时可以调用。
不过美中不足的是 _outputProperties 属性是私有的,而且没有 setter 方法,所以要用 Feature.SupportNonPublicField 参数才能给它赋值。
有关 TemplatesImpl 链的一些细节我已经在 CC3 的文章中分析清楚了,总结一下调用链:
1 | TemplatesImpl#getOutputProperties() |
下面直接给出测试用例:
1 | import com.alibaba.fastjson.JSON; |
这里我为 _bytecodes 传入的是一个 base64 编码的字节码,如果 JSON 中包含 Base64 编码的字符串,并且将它反序列化为 byte[] 类型的字段时,Fastjson 会自动尝试将该 Base64 字符串转换为字节数组。其中对应的解码操作在 JSONScanner#bytesValue() 中:

调用堆栈如下:
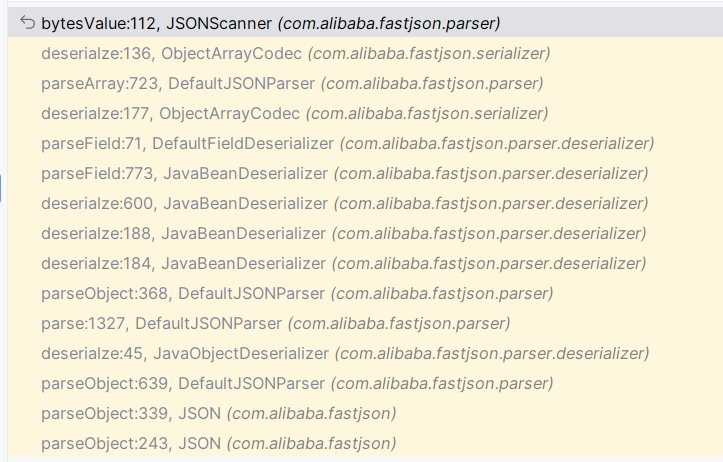
Eval.class 是 Eval 类编译后生成的字节码文件,Eval 类内容如下:
1 | package pojo; |
JdbcRowSetImpl 利用链
com.sun.rowset.JdbcRowSetImpl 这条利用链是由于 javax.naming.InitialContext#lookup() 参数可控导致的 JNDI 注入。
setAutoCommit,这是一个 setter 方法,调用了 connect 方法:
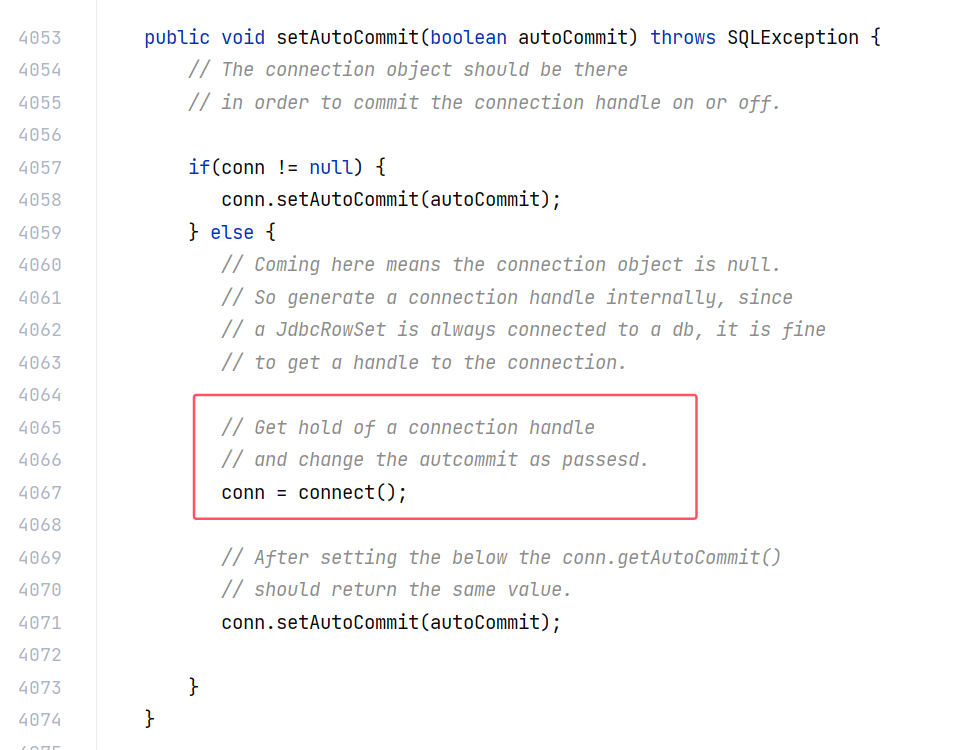
跟进 connect 方法:
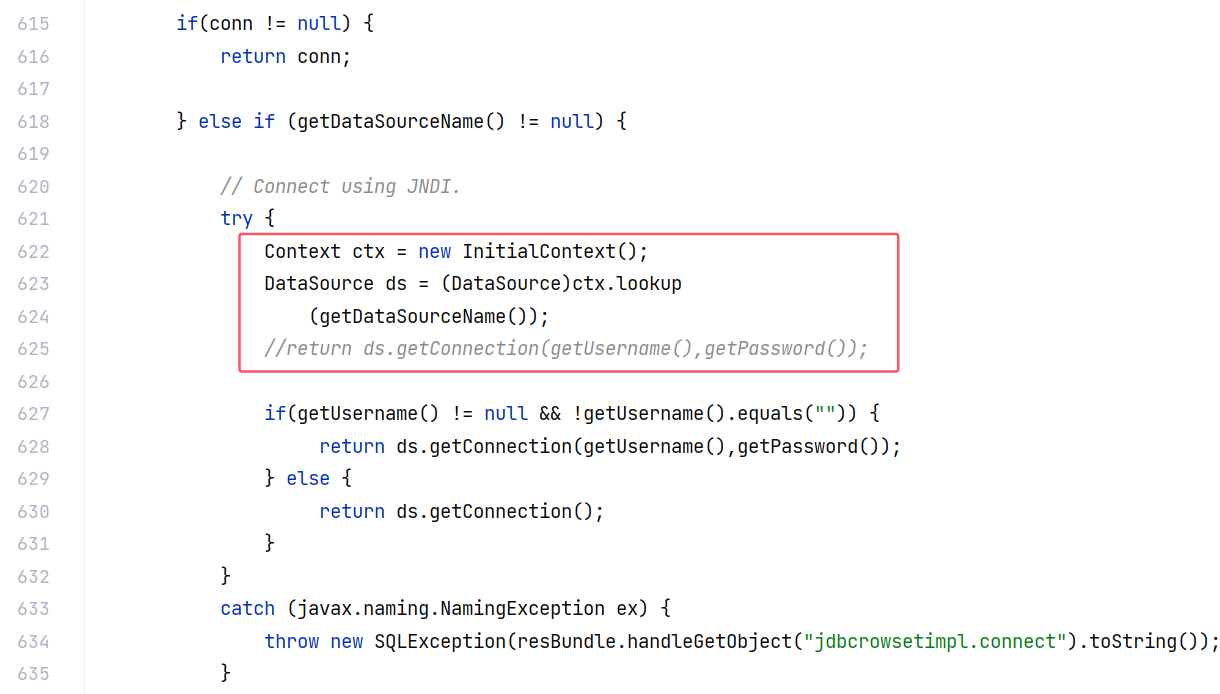
这里会调用 lookup 方法进行 Jndi 远程调用。
getDataSourceName():
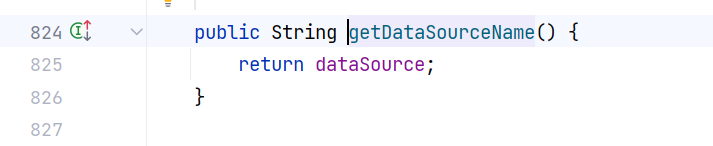
所以只需要将 dataSource 设置成 JNDI 服务端地址就行。
调用链如下:
1 | JdbcRowSetImpl#setAutoCommit(boolean) |
测试用例:
1 | import com.alibaba.fastjson.JSON; |
fastjson 1.2.25
影响版本:1.2.25 <= fastjson <= 1.2.42
fastjson 1.2.25 引入了 checkAutoType 安全机制,采用黑白名单校验类是否可加载。默认情况下 autoTypeSupport 关闭,基于白名单实现安全机制,而打开 autoTypeSupport 之后,是基于内置黑名单来实现安全的,fastjson 也提供了添加黑名单的接口。
checkAutoType 安全机制
将依赖版本升级到 1.2.25 之后,再运行上面的 TemplatesImpl 链,会报错:

根据报错信息找到了 ParserConfig#checkAutoType(String, Class<?>),在看这个方法之前,先说一下 ParserConfig 新增的一些属性:

autoTypeSupport 是新增的一个标志位,denyList 是黑名单,acceptList 是白名单。
黑名单中包含如下类:
1 | bsh |
接着来看 ParserConfig#checkAutoType(String, Class<?>),这个方法最主要的是几个 if 判断,反复使用黑白名单来验证。
$ 替换为 .,处理嵌套类;如果 autoTypeSupport 为 true ,那么先用白名单检查,再用黑名单检查,白名单检查通过的话可以直接加载类,而黑名单不会:
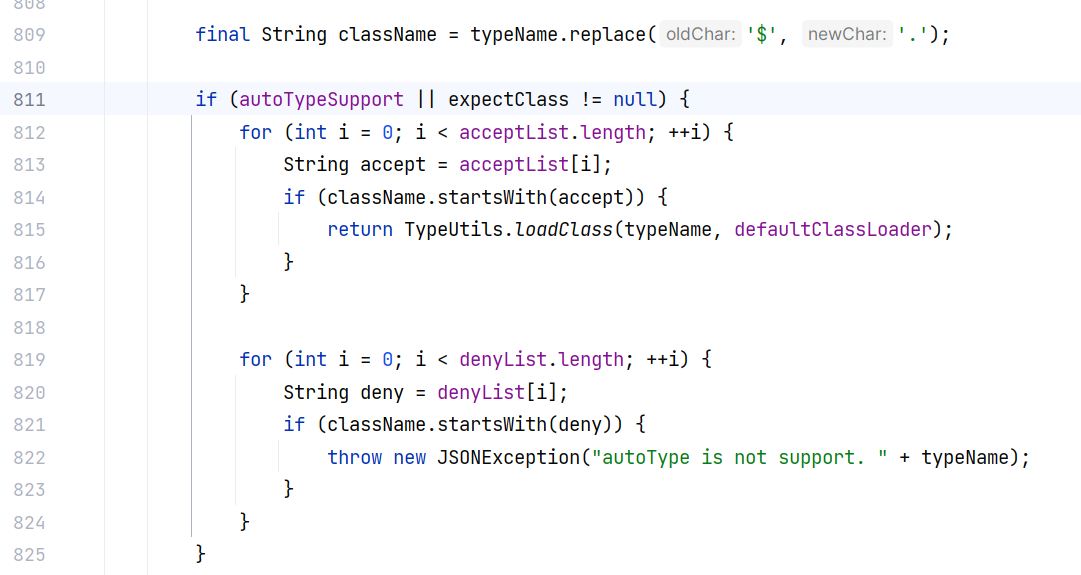
运行上面的 TemplateImplTest 代码时,这里的 expectClass 初始值为 null 。
如果 autoTypeSupport 为 false 的话,则先检查黑名单,再检查白名单。同样的是黑名单检查通过后也不能加载类:
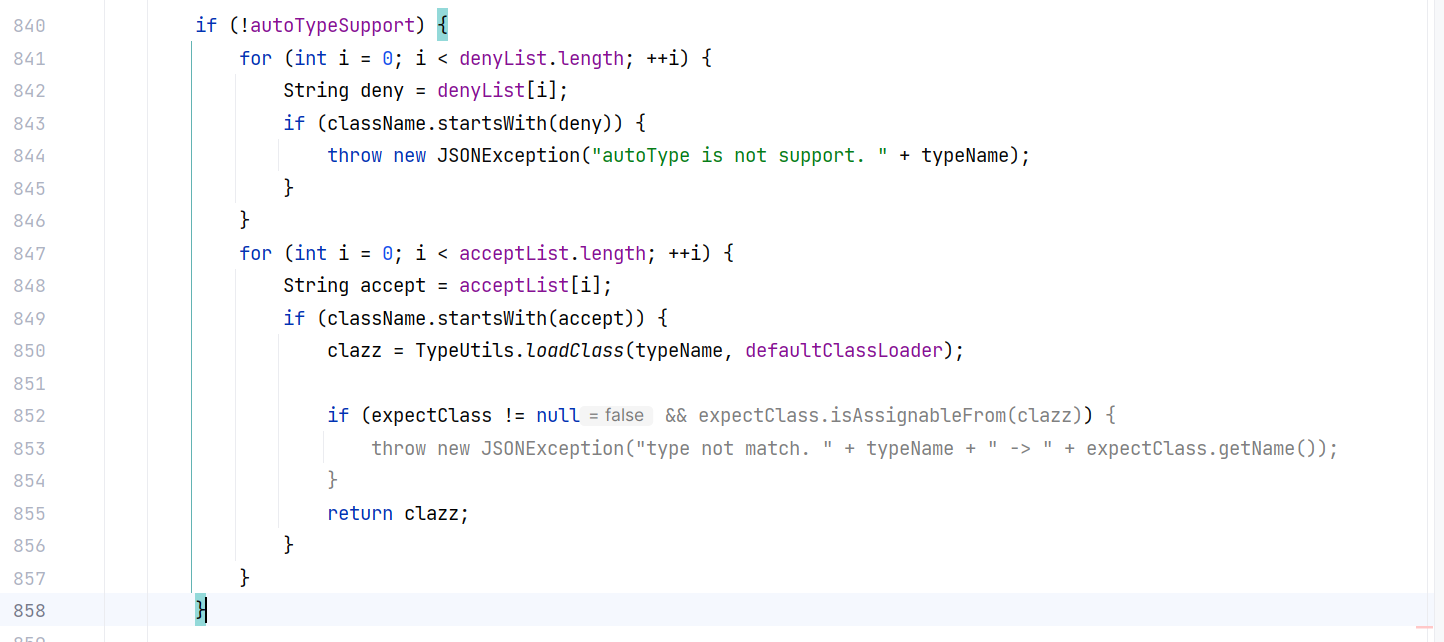
如果上面的检查都通过了但是没有加载类的话,再检查一次 autoTypeSupport 是否为 true ,如果是就加载类。这是这个方法中最后一次加载类的地方了,也就是说如果 autoTypeSupport 为 false 的话,是不会加载任何类的。而 autoTypeSupport 默认为 false :

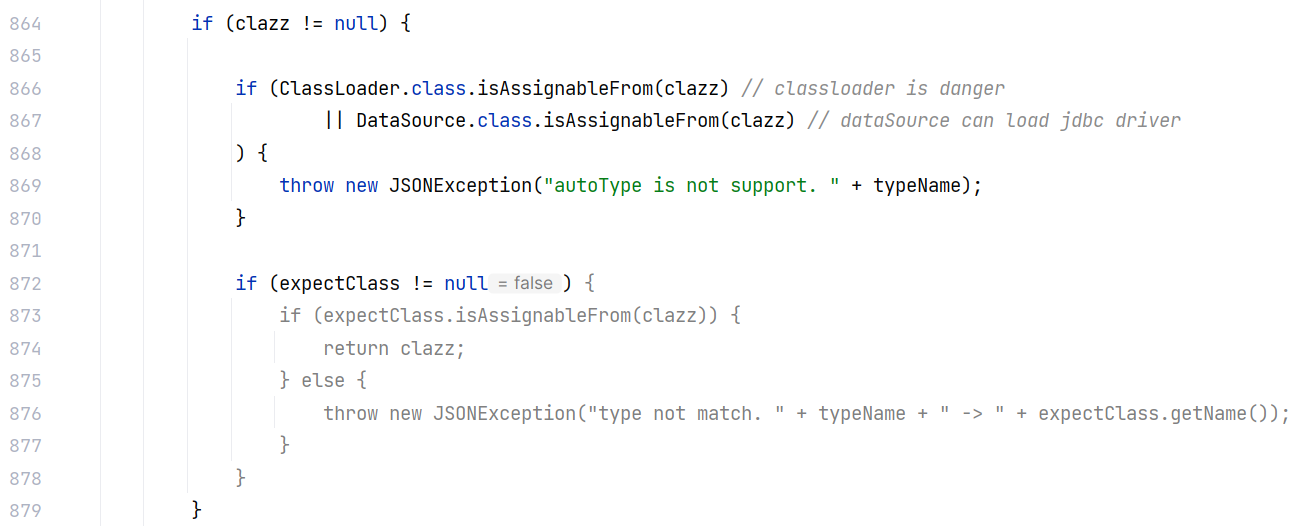
最后会检查加载的类是否是 ClassLoader 或 DataSource 的子类,这里是不允许加载它们的:
绕过方法
在上面加载类的时候会调用 TypeUtils.loadClass 方法,跟进看一下:

这其中的处理逻辑是这样的:
如果 classname 以 [ 开头,就去掉第一个字符 [ ,然后返回对应的数组类。这是因为在 Java 中,数组类型的类与普通类不同,它们有独特的类名表示方式。对于一维数组,类名以 [ 开头,例如 int[] 对应的类名是 [I,对象数组如 String[] 对应的类名是 [Ljava.lang.String;。这里的代码就是处理这种数组类型的加载。
如果 className 以 L 开头并以 ; 结尾,那么去掉头尾再加载。在字节码和序列化中,对象类型可能会被表示为 L类名; 的形式。例如 java.lang.String 可能被表示为 Ljava/lang/String;。本来是用于处理这种格式的类名,这样看来倒算是一种逻辑漏洞了。
这里先利用第二种机制,只需要在类名开头加上 L ,结尾加上 ; 就可以了。
payload 如下:
1 | { |
此外需要将 autoTypeSupport 设置为 true ,有两种办法。
第一种是全局设置:
1 | ParserConfig.getGlobalInstance().setAutoTypeSupport(true) |
第二种是为指定的类设置:
1 | ParserConfig.getGlobalInstance().addAccept("com.example.YourClass") |
fastjson 1.2.42
影响版本:1.2.25 <= fastjson <= 1.2.42
依然是关注 ParserConfig 这个类,主要有两个方面的改动,第一个就是黑名单采用 hash 的方式来表示类,不再是之前的明文了:
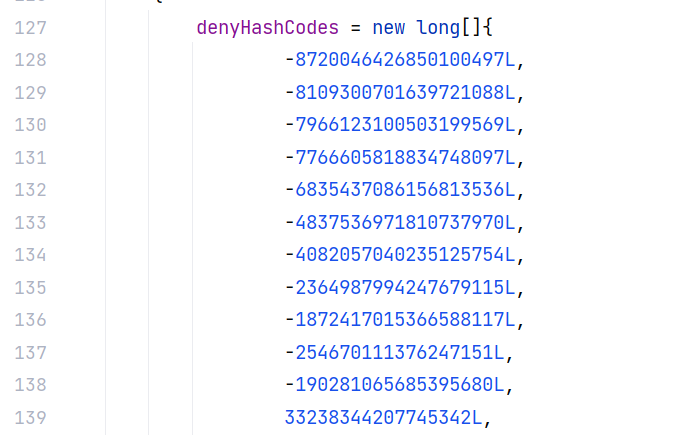
似乎是 FNV-1a 哈希算法(Fowler-Noll-Vo 哈希算法)的一种变体。hash 算法是不可逆的,无法还原出明文,但是可以通过 jackson 中的黑名单来撞库呢。
另一方面就是针对 checkAutoType 的改动,在做其他处理之前,首先针对以 L 开头并以 ; 结尾的 className 做了处理,去掉了开头和结尾:

这里也是采用了 hash 的方式进行了判断,虽然无法从代码直接看出想过滤什么字符,但是结合上个版本的问题也能猜出来。
此外,在原本判断黑白名单的地方也用 hash 的方式做了改动。作者这么做,想必是为了展示他深厚的功底,可以把相同的事物用不同的方式表达出来吧?
绕过方式也很容易想到,就是双写开头的 L 和结尾的 ; 。
payload:
1 | { |
fastjson 1.2.43
影响版本:1.2.25 <= fastjson <= 1.2.43
改动依然是在 ParserConfig#checkAutoType(String, Class<?>, int) ,如果开头出现了连续两个 L ,那么会抛出异常:
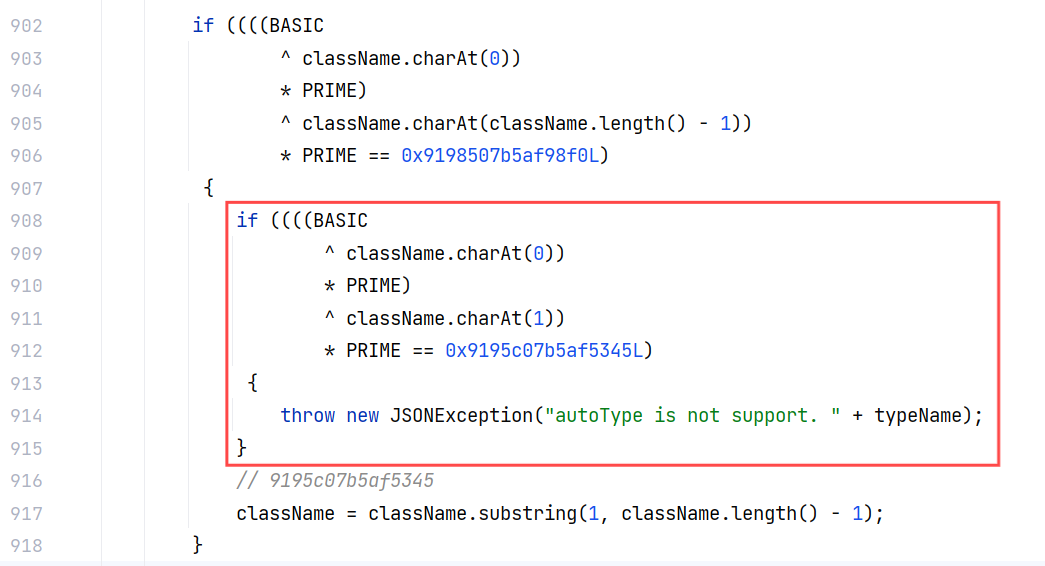
这样双写绕过的方式就失效了。不过前面提到了 TypeUtils.loadClass 方法有两种处理机制,现在来研究一下第一种,就是类名前加个 [ ,那么我给出一个测试用例:
1 | package fastjson1_2_43; |
运行后会报错:

报错信息显示:某个位置需要一个 [ ,但是却给了一个 , ,在 position 72 ,大概是第 72 个字符的意思。刚好是类名后面那个逗号,那就在这里加个 [ 。
报错位置在 DefaultJSONParser.parseArray :

加上 [ 后再次运行,还是报错:

position 73 需要一个 { ,就是前面加上的 [ 后面一个的位置,就再把它加上,这次运行成功了。
payload 就长这个样子:
1 | { |
fastjson 1.2.44
影响版本:1.2.25 <= fastjson <= 1.2.44
fastjson 1.2.44 版本不但修复了上个版本 [ 开头导致的绕过问题,而且只要是 [ 开头,或是以 L 开头 ; 结尾,会直接抛出异常,而不是像之前那样简单的过滤了:
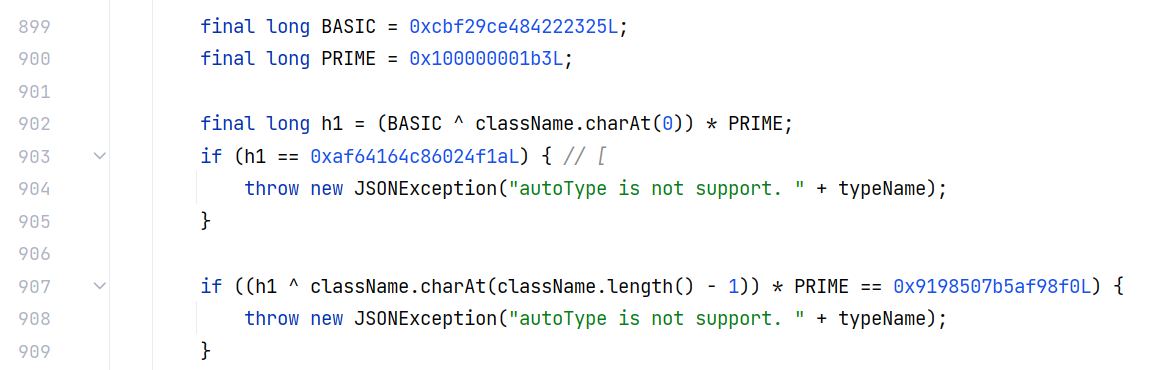
从代码逻辑上看,第一个 if 判断是否以 [ 开头,第二个 if 判断了是否以 L 开头并且以 ; 结尾。
这样的话就彻底杜绝了前面的几种绕过方式,果然是舍不得孩子套不着狼啊。
fastjson 1.2.45
影响版本:1.2.25 <= fastjson <= 1.2.45
1.2.45 版本曝出了新的可绕过黑名单的类 org.apache.ibatis.datasource.jndi.JndiDataSourceFactory ,这个类需要服务端有 mybatis 依赖 jar 包。
可以在我们的项目下手动添加一个:
1 | <dependency> |
payload 如下:
1 | { |
事实上这个类也可以用来绕过前面所有版本的黑名单。
不过在 1.2.46 版本中被加入了黑名单:
| version | hash | hex-hash | name |
|---|---|---|---|
| 1.2.46 | -8083514888460375884 | 0x8fd1960988bce8b4L | org.apache.ibatis.datasource |
fastjson 1.2.47
影响版本:1.2.25 <= fastjson <= 1.2.32 未开启 AutoTypeSupport 以及 1.2.33 <= fastjson <= 1.2.47 。
ParserConfig 的 checkAutoType 方法中有一个机制其实在之前的版本中已经有了,只是我们在研究的时候选择性忽略了而已。而这个利用方式在 1.2.47 版本被曝出来。
这个特性就是如果在黑白名单中没有找到匹配的类,会尝试在 TypeUtils 的 mappings 属性和 deserializers 中查找,如果能找到的话可以直接返回:
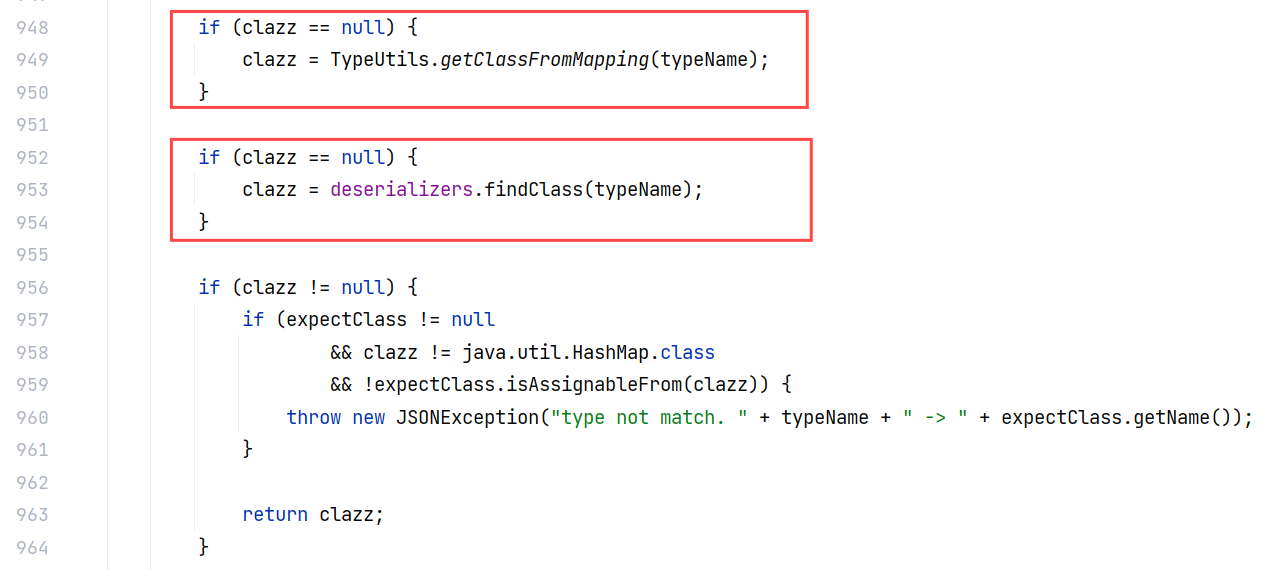
在 autoTypeSupport 为 true 的情况下,会进入前面的判断机制,但就算这个类在黑名单中,只要 TypeUtils 的 mappings 属性中能找到这个类,也不会抛出异常:
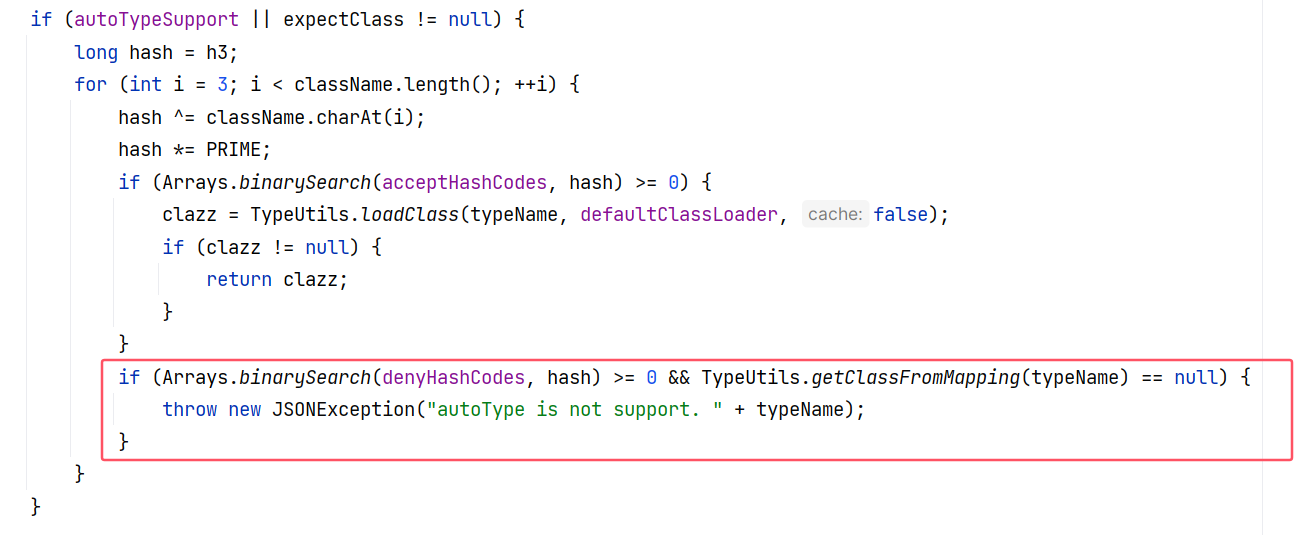
如果 autoTypeSupport 为 false ,那就更是畅通无阻了。于是就给了我们利用空间。
接下来的问题就是如何将类加载进 TypeUtils.mappings 或者是 ParserConfig.deserializers 。
将类加载进 TypeUtils.mappings
先来看 TypeUtils.mappings ,能将其赋值的方法有 addBaseClassMappings() ,loadClass(Stringe, ClassLoader, boolean)。
addBaseClassMappings() 中是对一些基本类型的赋值,没有什么操作空间:
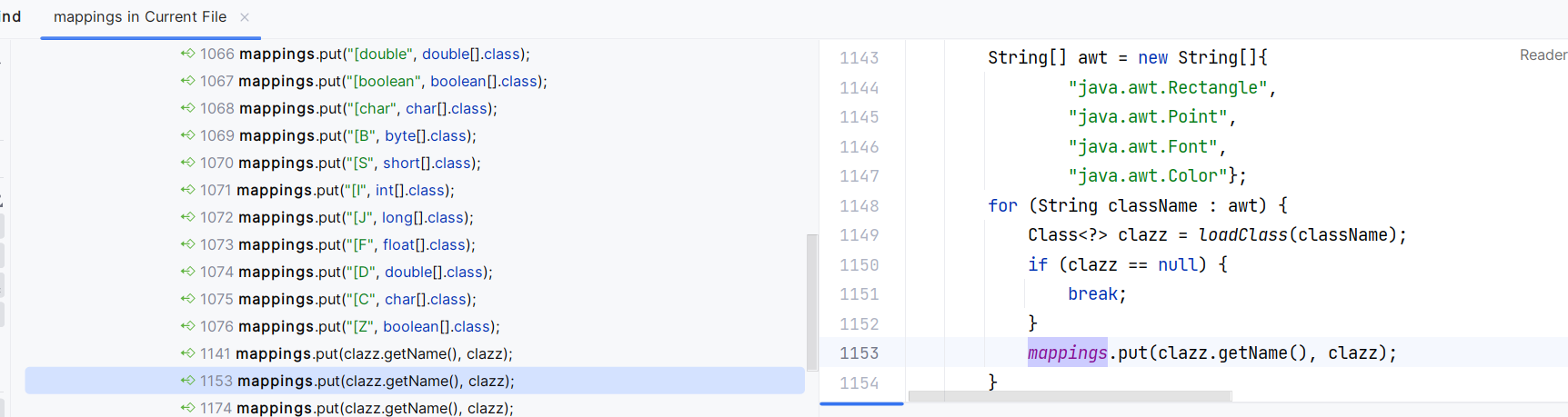
那么看 TypeUtils#loadClass(Stringe, ClassLoader, boolean),可以看到,只要传入的 cache 不为空,就可以将传入的 className put 进 mappings 中:

在 TypeUtils 中,loadClass(Stringe, ClassLoader, boolean) 只有一处被调用,就是两个参数的重写方法 loadClass(String, ClassLoader ):

并且这里默认会将 cache 设置为 true 。
其实还有个一参重写方法调用了这个两参重写方法,但是它会将 classLoader 设置为空,而在三参重写方法中是要用到这个 classLoader 的,所以不考虑:

向上找两参的 loadClass 方法在哪被调用。
关注 com.alibaba.fastjson.serializer.MiscCodec#deserialze 方法,如果方法传入的参数 clazz 为 Class.class ,那么会调用两参的 loadClass 方法:

这里传入的第一个参数是 strVal ,作为类名。往上看看 strVal 在哪被赋值:

显然是被 objVal 赋值,描述类名用字符串,我没意见。
再往前看 objVal ,如果 parser.resolveStatus 是 DefaultJSONParser.TypeNameRedirect 的话,就能给 objVal 赋值了:
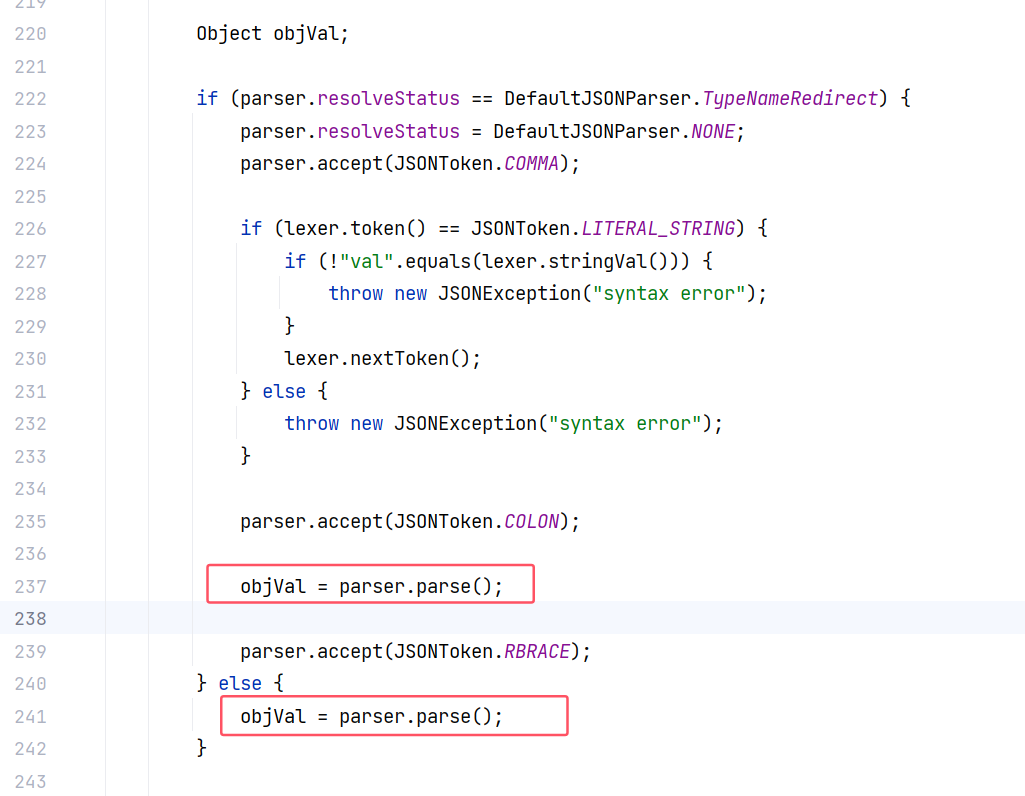
parser 也是传进来的参数,parser.parse() 这里面的调用链我就不分析了,简单总结一下:
1 | DefaultJSONParser#parse() |
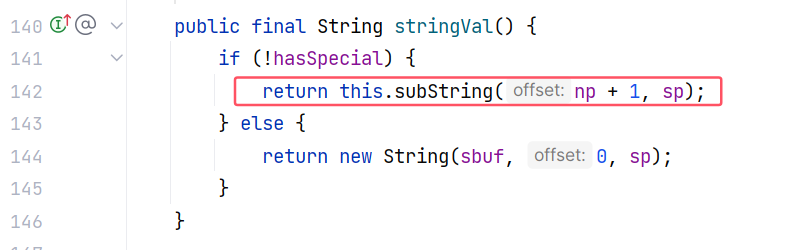
JSONScanner#subString(int, int):
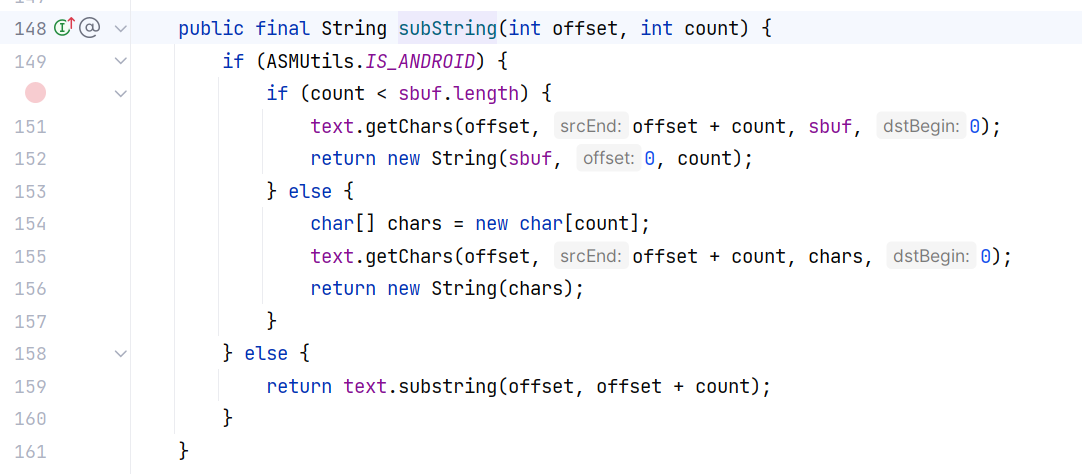
从 text 中取子串,至于取子串的位置早就设定好了,其实取的是 json 字符串的键名为 val 所对应的值。但是为什么从一开始就这么设定好了呢,这就不得不提到 lexer 这个 JSONScanner 扫描器对象了。
JSONScanner 扫描器
早在 JSON#parse 方法创建 DefaultJSONParser 对象的时候就创建了这个 JSONScanner 对象:
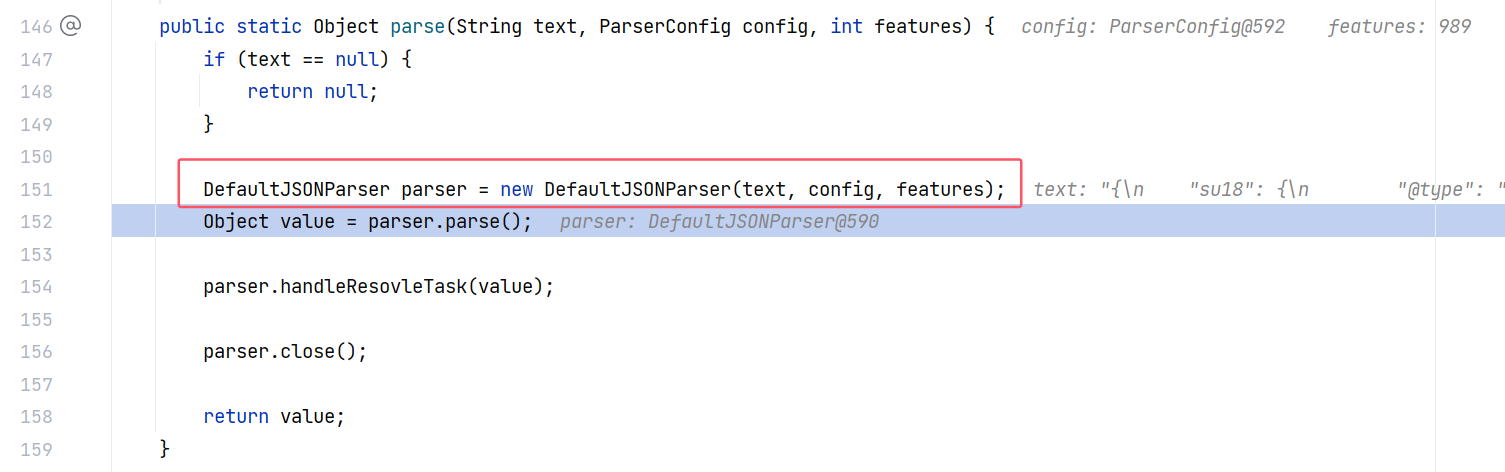
跟进去看构造方法:

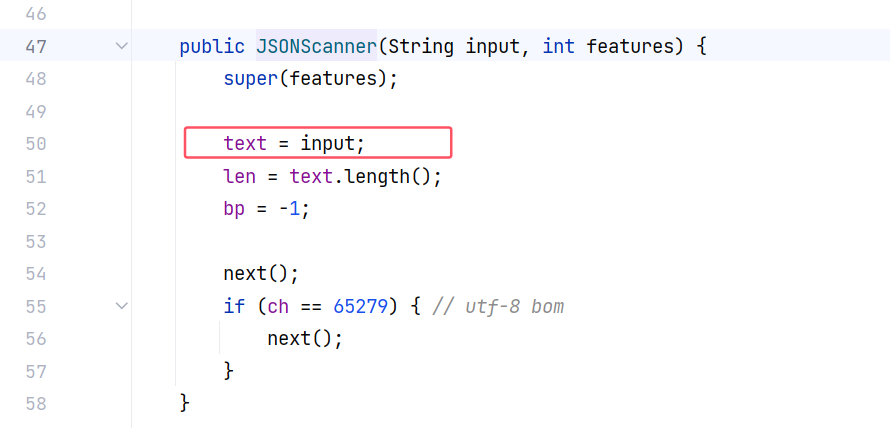
注意这里的 input 就是我们最初传入的 json 字符串。在 JSONScanner 的构造方法中被赋值到 JSONScanner 对象的 text 属性中:
那么 text 的赋值搞清楚了。看 JSONScanner#stringVal() :
这其中代表起始地址与长度的 np、sp 又是在何处赋值呢?
其实是 lexer.nextToken() 方法在改变 np、sp 的值,也就是 JSONScanner 的父类 JSONLexerBase 的 nextToken() 方法。
nextToken 会将 JSON 中的键或值解析成独立的词法单元。例如,在解析 JSON 对象 {"name": "John", "age": 30} 时,nextToken 依次识别并解析以下词法单元:
{:表示对象的开始,词法单元类型为LBRACE"name":字符串类型的键,词法单元类型为STRING::表示键和值的分隔符,词法单元类型为COLON"John":字符串类型的值,词法单元类型为STRING,:表示下一个键值对的开始,词法单元类型为COMMA"age":字符串类型的键,词法单元类型为STRING::表示键和值的分隔符,词法单元类型为COLON30:数字类型的值,词法单元类型为NUMBER}:表示对象的结束,词法单元类型为RBRACE
当 nextToken 方法识别到一个词法单元后,词法分析器(lexer)将准备好为下一个 nextToken 调用解析下一个词法单元。
回过头看 MiscCodec#deserialze(DefaultJSONParser, Type, Object):
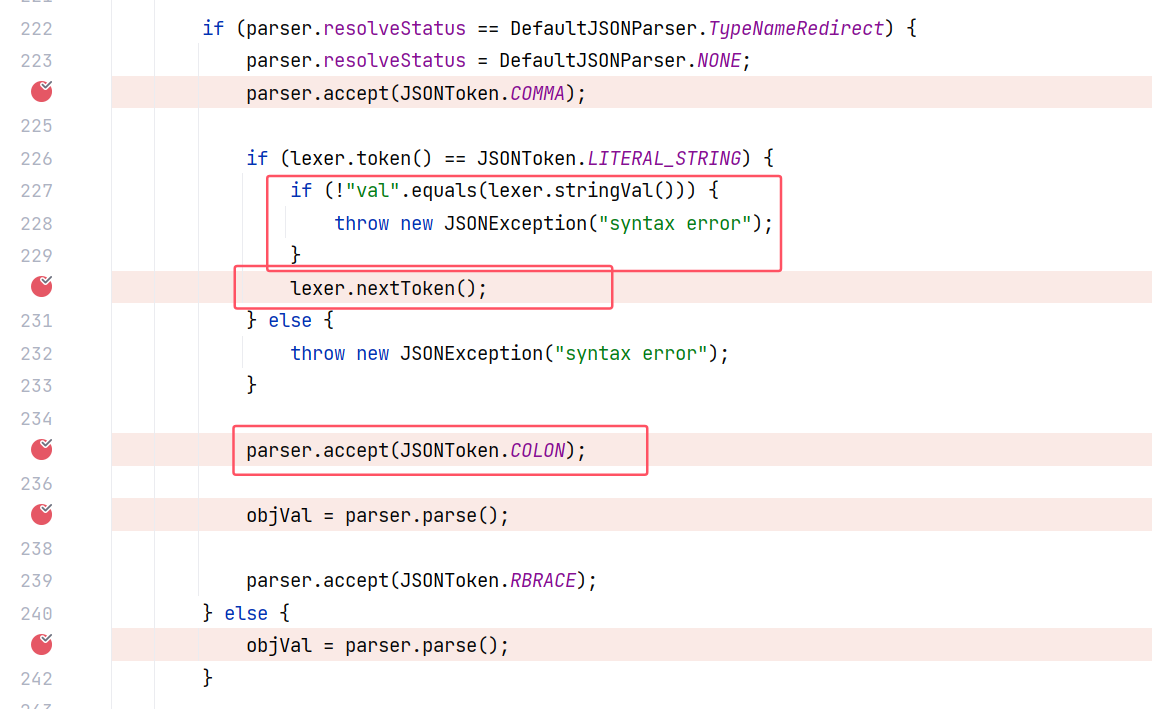
在做判断的时候判断当前词法单元是不是 “val” ,不是的话会抛出异常,是的话调用 nextToken ,假如 json 数据的格式是:{"val":"aaaaa"} 这样的形式,调用 nextToken 之后,当前的词法单元就是 : 了。
然后调用 parser.accept ,这里面其实也调用了 nextToken ,并且在调用之前会检查当前的词法单元是不是 : :
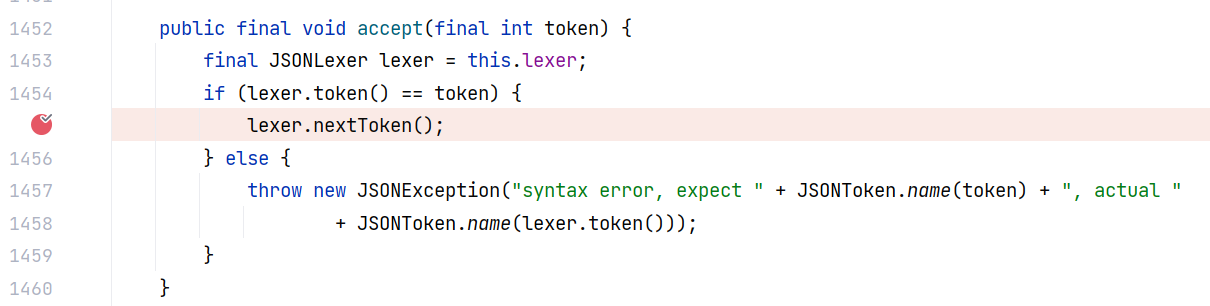
那么这个 nextToken 调用完之后,当前的词法单元就是 “val” 键对应的值了。所以 objVal 获取到的就是 val 键对应的值。
ParserConfig.deserializers 的初始化
现在回到最初的那个问题:如何将类加载进 TypeUtils.mappings 或者是 ParserConfig.deserializers 。
接下来看看能否将类加载进 ParserConfig.deserializers 中,但是不能,deserializers 是 ParserConfig 的一个成员属性,定义的时候就初始化好了,并且只有在 ParserConfig#initDeserializers() 中才有添加的操作:

都是硬编码写好的,没有操作空间,所以不考虑。不过其中有一条,Class 类也在这个里面,这就意味着,如果反序列化的是 java.lang.Class 类,那么它能顺利通过 checkAutoType 的检测。
剩余利用链分析
DefaultJSONParser#parseObject(final Map, Object) 方法在遇到 Class 这样的类时,会调用 MiscCodec 类来反序列化它们,并且前面还会设置好 resolveStatus 为 TypeNameRedirect ,这就满足了 MiscCodec#deserialze 中给 objVal 赋值的条件:
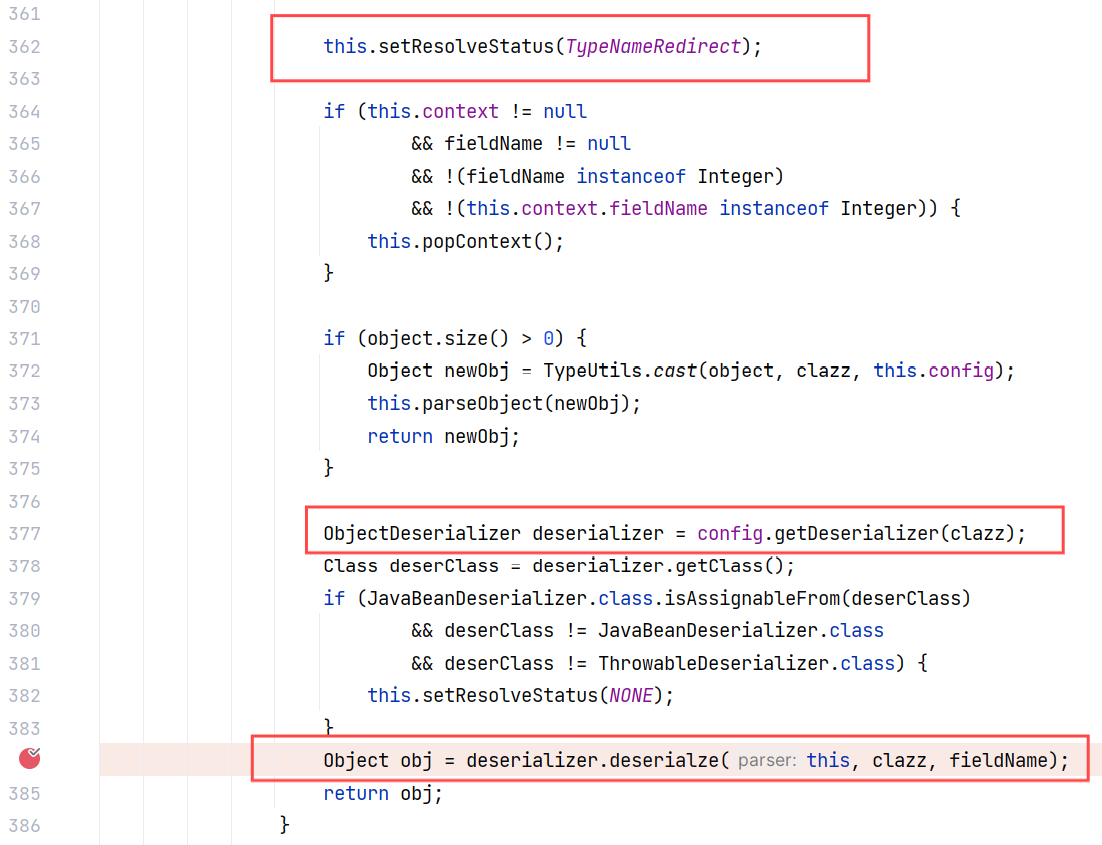
DefaultJSONParser#parseObject(final Map, Object) 这个方法很有意思,遇到不同的类还会调用不同的类来处理它,比如遇到 Class 类调用 MiscCodec 类来反序列化,这应该就是在前面的 ParserConfig#initDeserializers() 中指定的。
payload
这部分思路理清了之后,给出一个 payload :
1 | { |
反序列化第一个类时,Class 能顺利通过 checkAutoType 的检查并返回,随后进入 MiscCodec#deserialze 中将 “com.sun.rowset.JdbcRowSetImpl” 字符串加载进 TypeUtils.mappings 。
反序列化第二个类的时候,由于 TypeUtils.mappings 中存在 “com.sun.rowset.JdbcRowSetImpl” ,即使黑名单匹配到了也不会抛出异常,并且能够成功返回。
漏洞修复
1.2.48 版本对这种利用方式进行了修复,首先就是将 TypeUtils 的两参 loadClass 方法调用三参方法时的 cache 默认设置为 false :

这样就没有办法将类加载进 TypeUtils.mappings 了。
另一个更改的点就是 MiscCodec#deserialze(DefaultJSONParser, Type, Object) 直接调用 TypeUtils 的三参 loadClass 方法,并且将 cache 设置为 false :

最后一个点就是似乎将 java.lang.Class 类加入黑名单了,当我调试到 ParserConfig#checkAutoType 时,第一次进入就直接抛出异常:
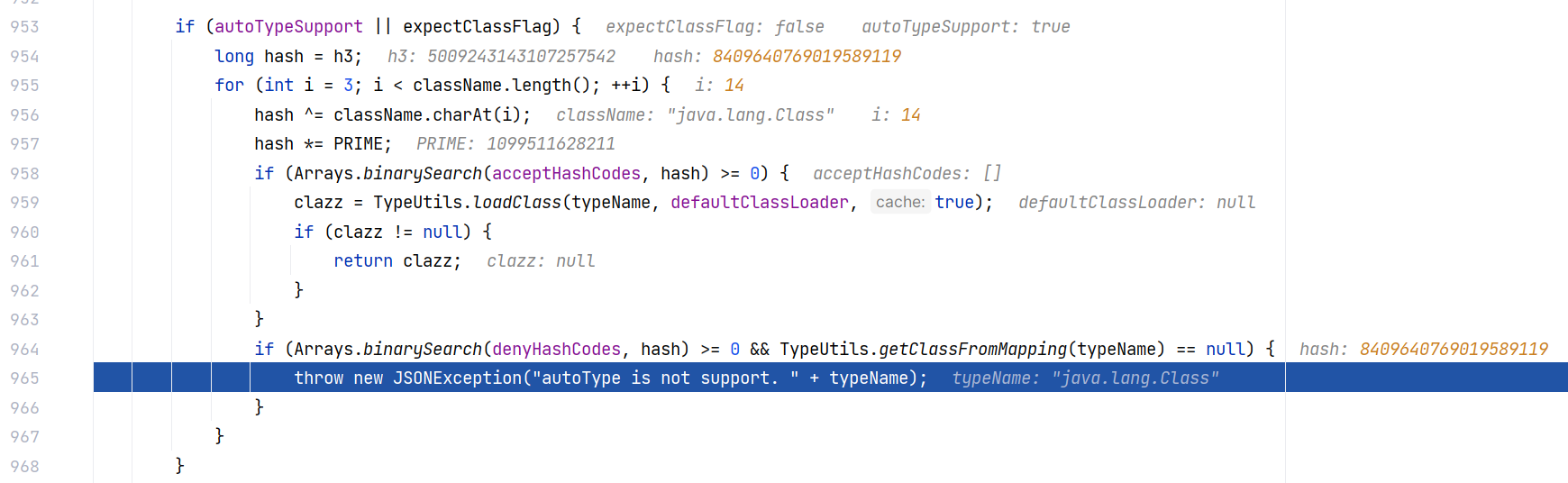
大概是将 java.lang.Class 类加入黑名单了。
fastjson 1.2.68
影响版本:fastjson <= 1.2.68
fastjson 1.2.68 版本在 ParserConfig 中新增了一个 safeMode 安全机制。在其 checkAutoType 方法中:

只要当前开启了安全模式 safeMode ,那么就会直接抛出异常,任何类都不能通过检查,那么就不能反序列化任何类。
另外,在 1.2.68 版本出现了一种新的绕过方式,利用点在 checkAutoType 方法的这个位置,如果能构造一个符合条件的 expectClass ,即要反序列化的类是传入的 expectClass 的子类,那么就能通过 checkAutoType 的检查:
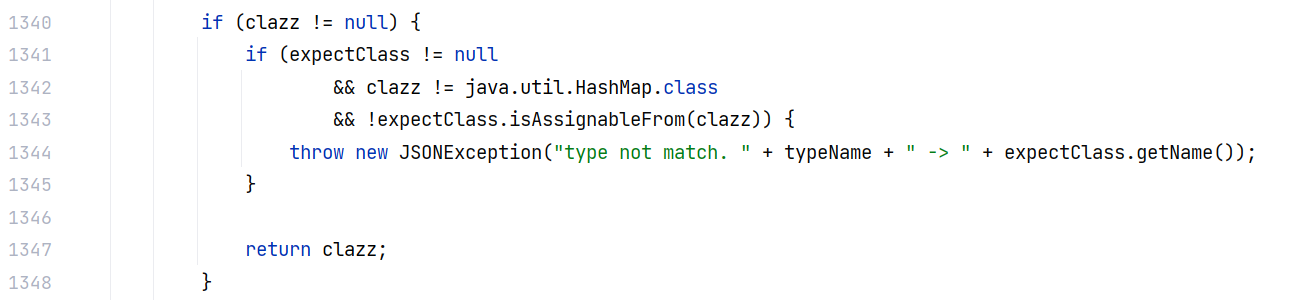
当然这是在 safeMode 关闭的前提下才能利用。其实这个点在过往的版本中也都有,只是利用方式在 1.2.68 版本才发现而已。
expectClass 是三参 checkAutoType 方法的参数:

找一找哪里调用了这个三参 checkAutoType 方法并且将 expectClass 赋值了。
抛开将 expectClass 设置为 null 的情况,可以找到:
- JavaBeanDeserializer#deserialzeArrayMapping
- JavaBeanDeserializer#deserialze
- ThrowableDeserializer#deserialze
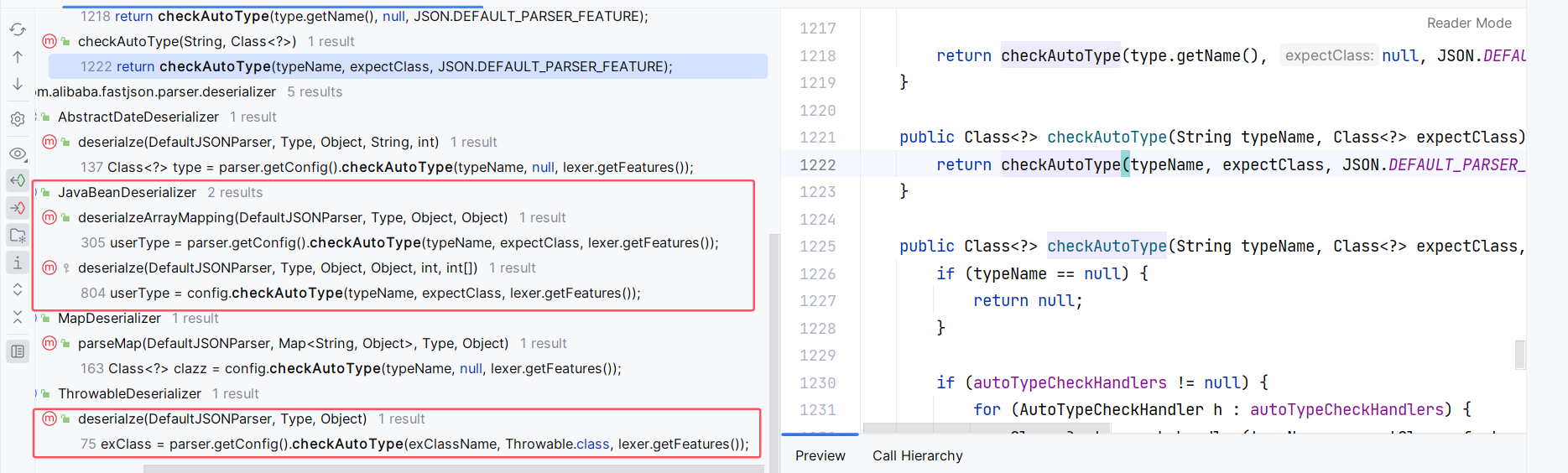
另外,两参 checkAutoType 也调用了三参 checkAutoType ,但是 expectClass 依然是传入的,而且两参 checkAutoType 被调用的点 expectClass 都是被设置为 null ,所以没有利用价值:
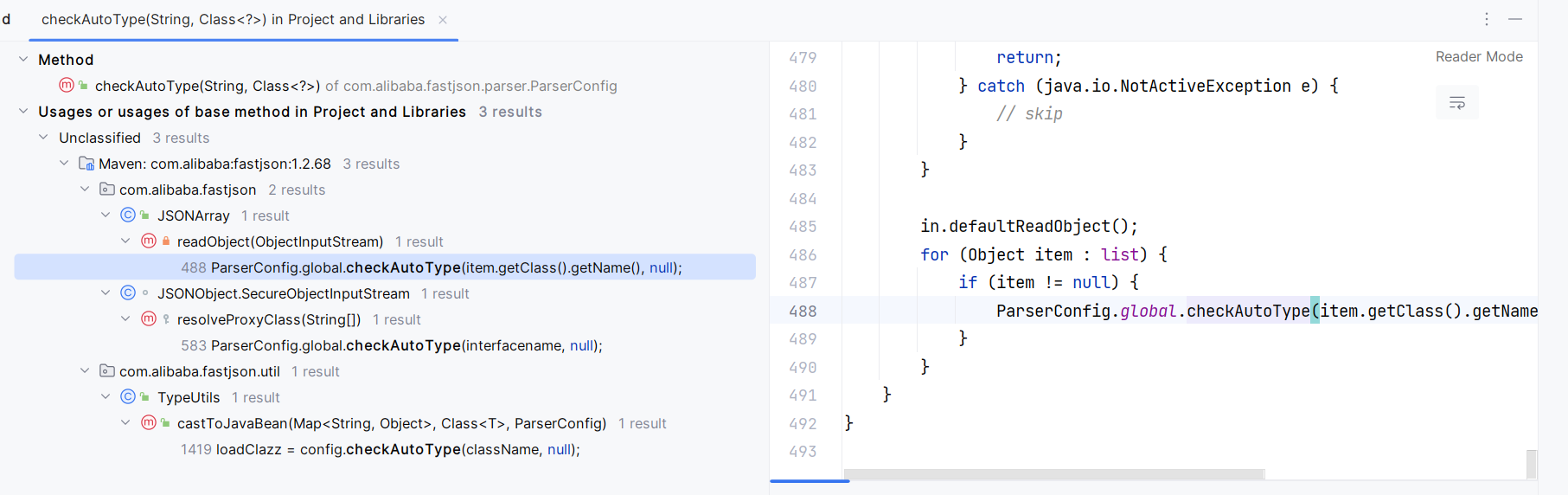
ThrowableDeserializer#deserialze
调用点在这里:

它会将 @type 对应的值传入第一个参数,Throwable.class 作为 expectClass 的值:
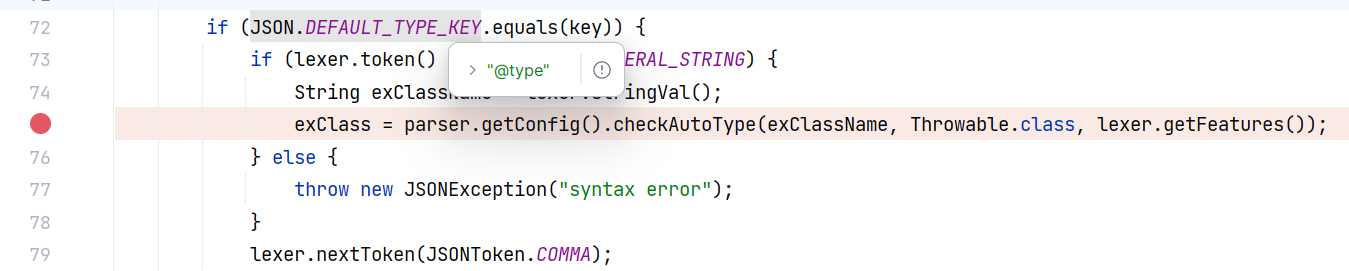
也就是说 @type 对应的类是 Throwable 的子类的话,通过 checkAutoType 的检查。
然后调用 createException 方法创建异常类:
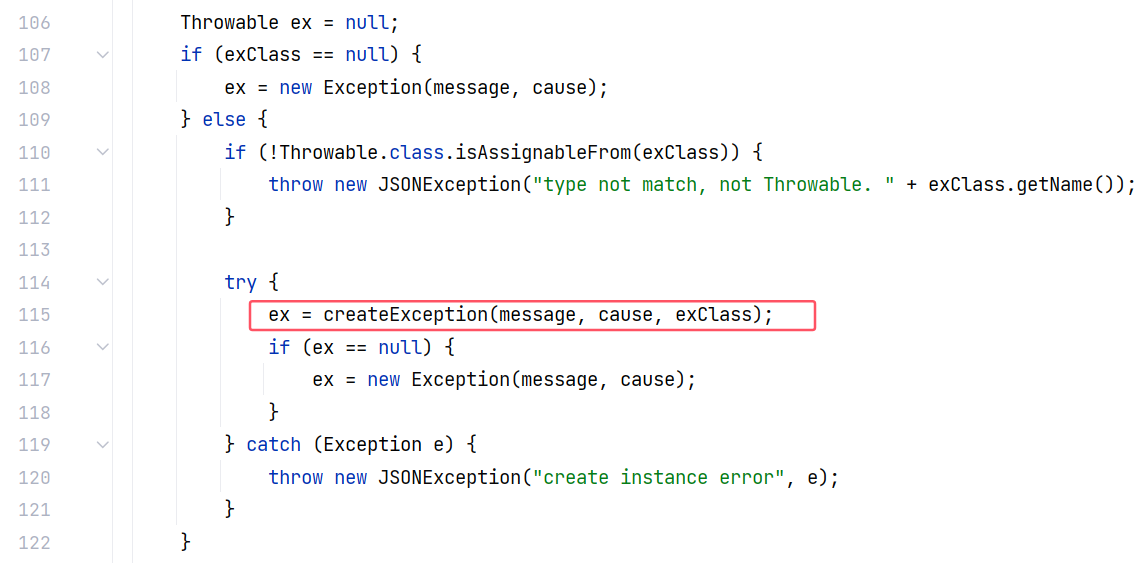
跟进 ThrowableDeserializer#createException(String, Throwable, Class<?>),最后在这里实例化:

那么核心点就在于找一个 Throwable 的子类,它的 getter/setter/static block/constructor 中有可利用的点,或者其他地方有可利用的链。从这个版本开始,再想要 RCE 就比较难了,大部分情况下考虑对文件的操作以及 SSRF 之类,而且可利用的链通常需要很多依赖。这个就留待后续说明吧。